
Dubbo的独门绝技,SPI实现原理分析
文章目录
- 前言
- 普通SPI实现原理
- 实例化扩展点源码分析
- 扩展点加载流程分析
- LoadingStrategy分析
- 接口定义
- 接口实现
- 加载原理
- loadClass方法分析
- 自适应SPI实现原理
- 自适应扩展代码生成分析
- 自激活SPI
- 简单使用
- 原理分析
- Activate注解
- 源码分析
- IOC实现原理
- objectFactory介绍
- 总结
- AOP实现原理
- 总结
本专栏对应Dubbo版本:
2.7.8。官方文档地址:https://dubbo.apache.org/zh/docsv2.7/dev/
官方GitHub地址:https://github.com/apache/dubbo/releases/tag/dubbo-2.7.8
前言
在上篇文章我们已经对Dubbo中的SPI有了简单的了解,接下来我们通过源码详细了解其实现细节。
在本文中,我将SPI分为普通SPI,与之相对应的是自适应SPI,这个概念是笔者“捏造”的,为了更好的划分文章结构,读者不必纠结字眼。
普通SPI实现原理
核心的API为
// 第一步:获取到对应接口的ExtensionLoader
ExtensionLoader extensionLoader = ExtensionLoader.getExtensionLoader(SpiService.class);
// 第二步:通过ExtensionLoader实例化具体扩展点
SpiService internal = extensionLoader.getExtension("internal");
获取ExtensionLoader的逻辑非常简单,大家自行阅读源码即可,如何创建扩展点才是我们的重点
实例化扩展点源码分析
在没有进行源码分析之前大家应该能想到,要得到一个扩展点实现类对象起码要做这么几件事
- 根据接口名找到并解析配置文件,加载对应的扩展点实现类
- 类加载成功后就可以反射创建对象了
- 之后再对这个对象完成IOC及AOP
实际上Dubbo也确实是这么做的,接下来我们分析其源码
扩展点实例化核心方法如下,源码比较简单,这里我只保留了其骨架,我们先对整体流程有一个认知
// 直接定位到调用的核心方法
// name:为传入的扩展点名称
// wrap:代表是否要进行AOP,默认为true
private T createExtension(String name, boolean wrap) {// 1️⃣.加载扩展点实现类,得到class对象Class clazz = getExtensionClasses().get(name);// 2️⃣.这里通过反射调用空参构造函数,完成实例化T instance = (T) EXTENSION_INSTANCES.get(clazz);if (instance == null) { EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());instance = (T) EXTENSION_INSTANCES.get(clazz);}// 3️⃣.IOCinjectExtension(instance);// 4️⃣.AOPif (wrap) {// .....}// 5️⃣.扩展点生命周期,进一步完成初始化initExtension(instance);return instance;
}
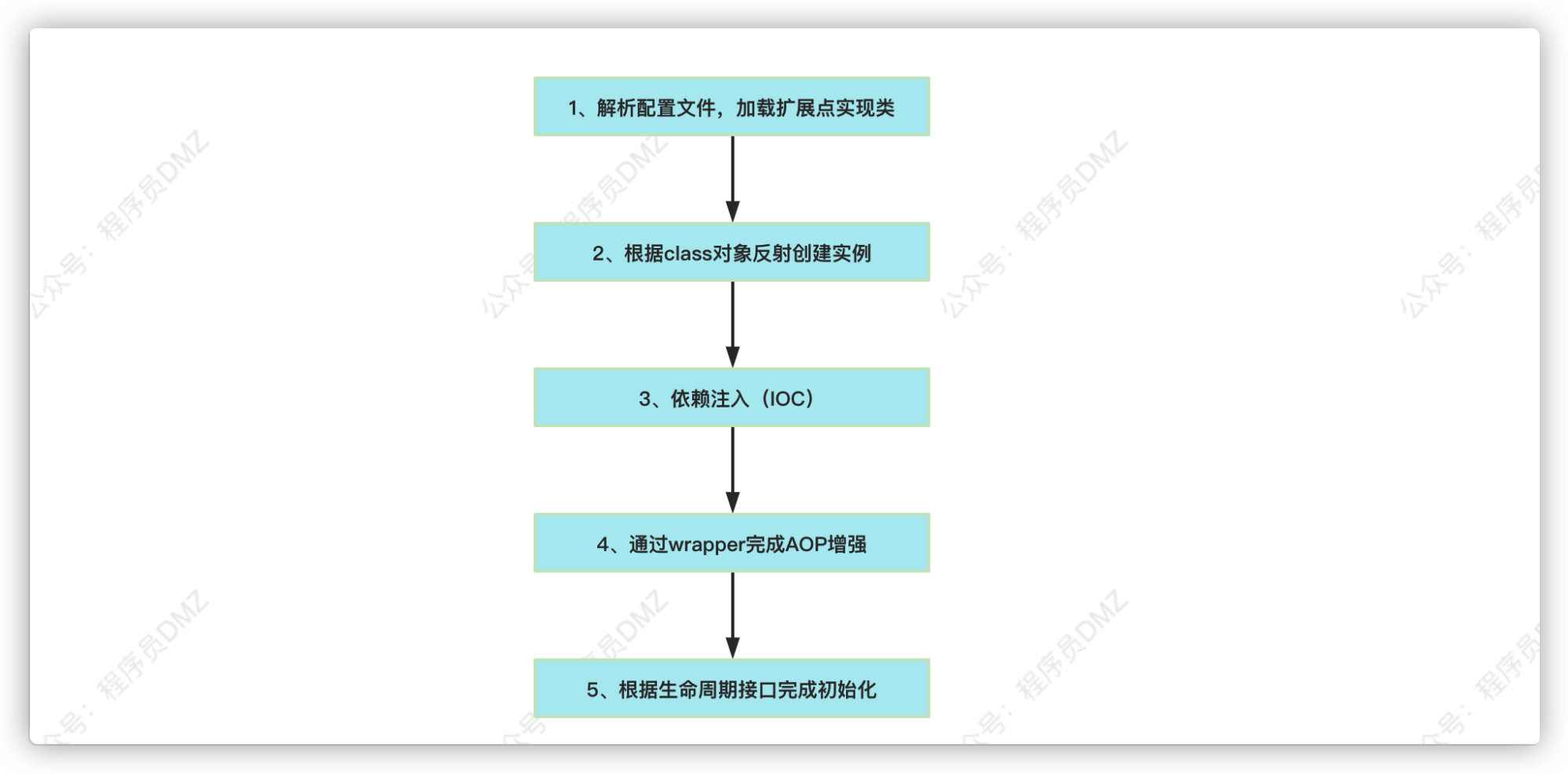
在上面的代码中我们可以清晰的看到整个扩展点实例化分为5步,如下图所示
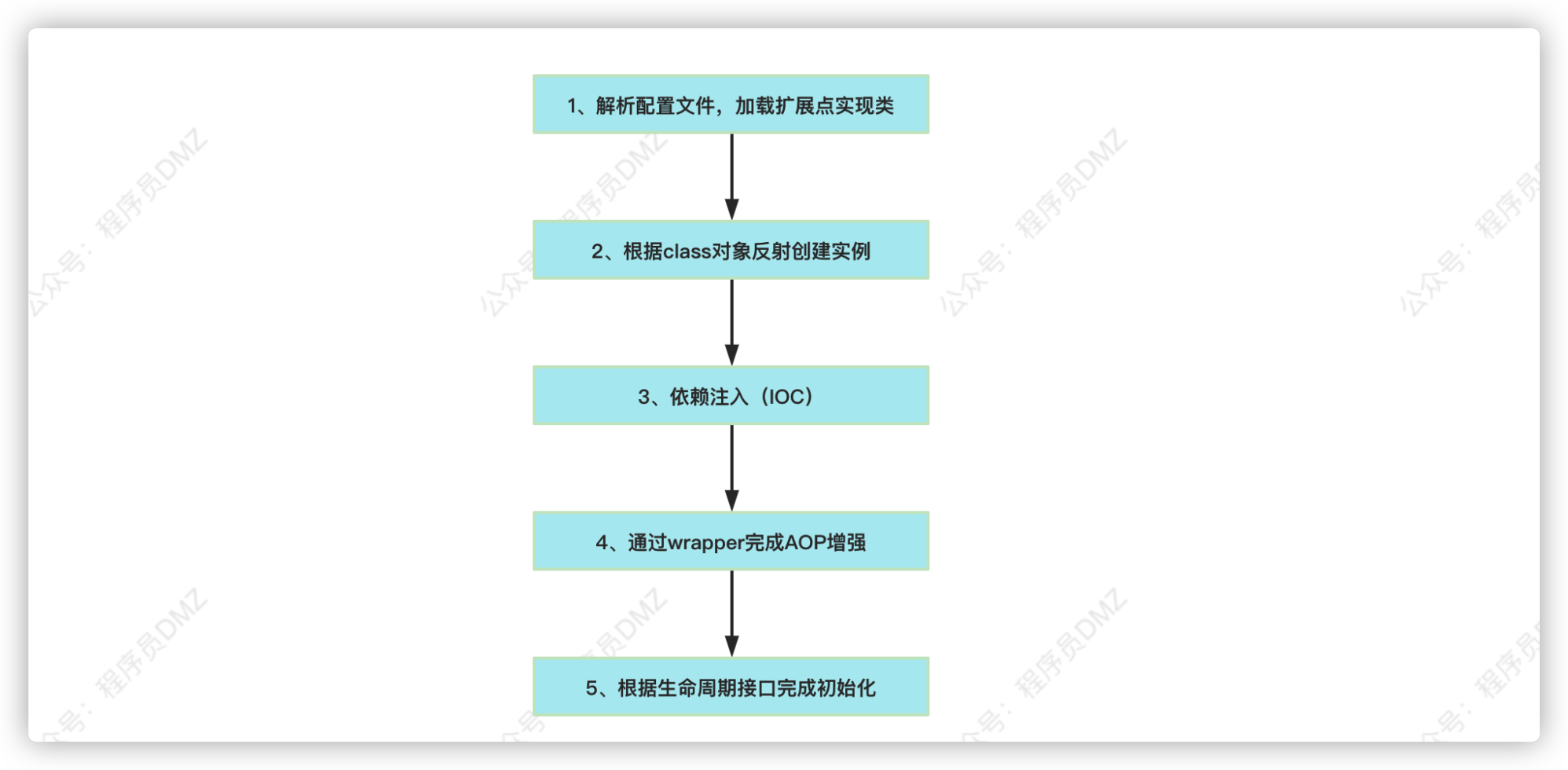
扩展点加载流程分析
在这一小节中,我们主要分析Dubbo是如何加载扩展点的,核心代码位于org.apache.dubbo.common.extension.ExtensionLoader#loadExtensionClasses,如下:
private Map> loadExtensionClasses() {// 我们可以在@SPI的注解中指定默认要使用的SPI名称cacheDefaultExtensionName();Map> extensionClasses = new HashMap<>();// dubbo中内置了一些加载策略for (LoadingStrategy strategy : strategies) {loadDirectory(extensionClasses, strategy.directory(), type.getName(),strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());// 这里主要是为了向下兼容alibaba DubboloadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());}return extensionClasses;
}
要理解上述代码,我们首先要搞懂LoadingStrategy的作用,其次我们知道在strategies这个集合中放入了哪些LoadingStrategy。
LoadingStrategy分析
接口定义

可以看到这个接口继承了Prioritized,Prioritized的主要作用是定义加载的优先级。LoadingStrategy的作用在于定义加载SPI配置文件时的策略,例如:从哪个目录下加载、哪些不需要加载等
public interface LoadingStrategy extends Prioritized {// 定义了SPI配置文件的加载地址String directory();// 目前没有看到哪个实现类复写了这个方法,可忽略default boolean preferExtensionClassLoader() {return false;}// 排除指定包下的SPI实现类default String[] excludedPackages() {return null;}// 如果一个SPI存在多个同名的实现的时候,是否要进行覆盖default boolean overridden() {return false;}
}
接口实现
在Dubbo中内置了三种LoadingStrategy,分别为:
-
DubboInternalLoadingStrategy:加载优先级最高(
Integer.MIN_VALUE),加载目录为:META-INF/dubbo/internal/,不支持覆盖。这个策略主要是Dubbo内部使用的[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SKPgpOCS-1679484853206)(/Users/mingzhidai/Library/Application Support/typora-user-images/image-20211219161506784.png)]
注意:这个策略的优先级是最高的,因此
META-INF/dubbo/internal/这个目录下的类会被最先加载,同时它是不支持覆盖的,因此如果同名的实现存在多个,第一个会生效 -
DubboLoadingStrategy:正常加载优先级(
0),加载目录为:META-INF/dubbo/,支持覆盖。这个策略是提供给外部开发者使用的,我们平常进行扩展时,更多是使用这个目录。由于这个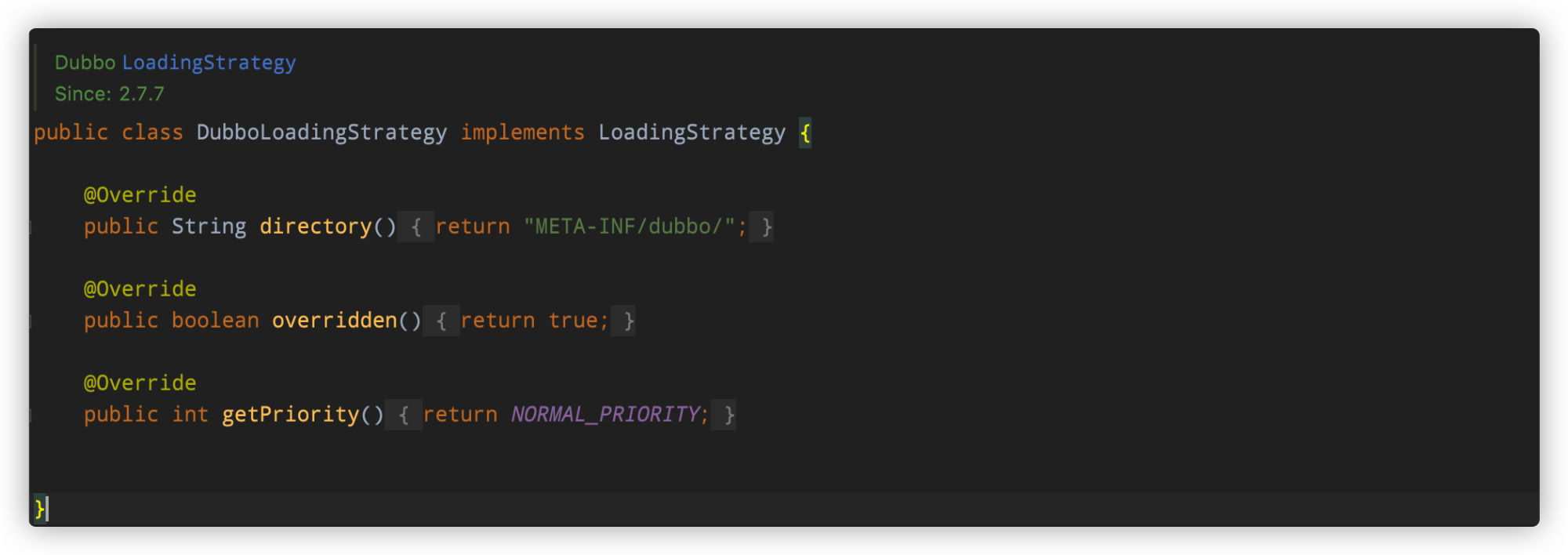
注意:这个策略的优先级低于
DubboInternalLoadingStrategy,因此META-INF/dubbo/这个目录下的类会晚于META-INF/dubbo/internal/中的类被加载,同时它又能支持覆盖已存在的同名实现类,这就意味在META-INF/dubbo/目录中的类的优先级是高于META-INF/dubbo/internal/的,通过这种方式我们就能替换Dubbo中默认的SPI实现,这也体现了内核+插件的思想 -
ServicesLoadingStrategy:加载目录为:
META-INF/services/,加载优先级最低(0),同时也支持覆盖。这个策略兼容了JDK原生SPI的加载目录。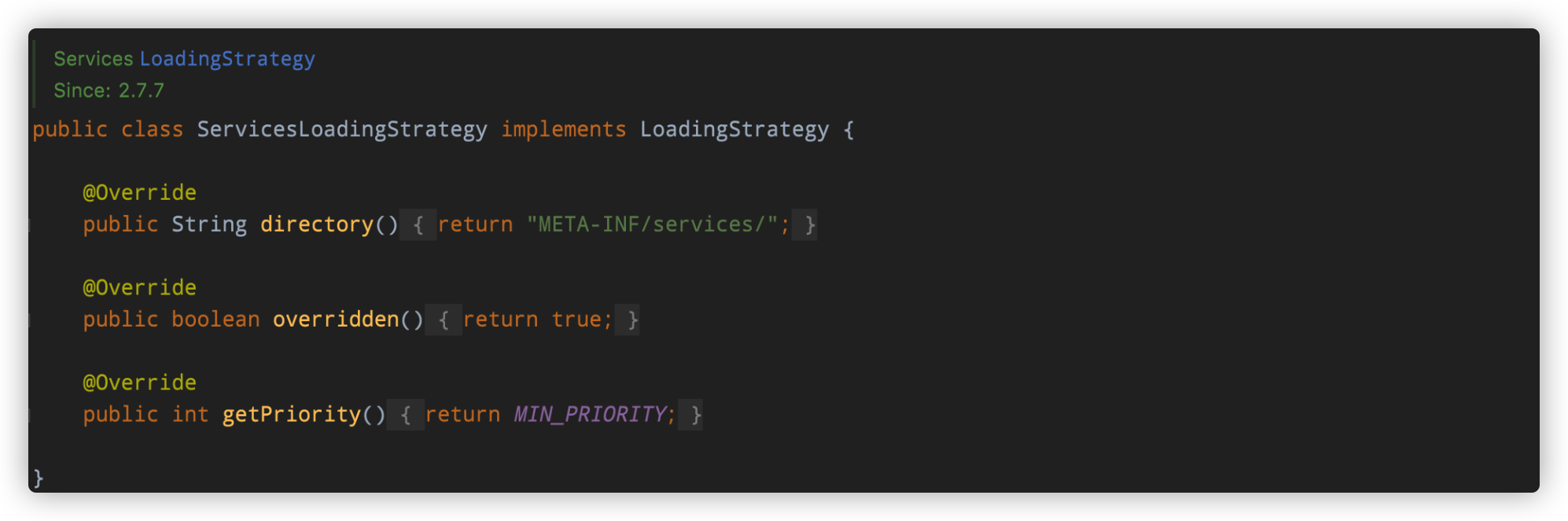
注意:这个策略的优先级是最低的,同时它支持覆盖,因为这个目录下的类的优先级是最高的,会覆盖之前加载的类。
整个优先级及是否覆盖的设计也体现了一个思想:越靠近应用,优先级越高,方便扩展
加载原理
LoadingStrategy的加载本身使用的是JDK原生的SPI,加载逻辑见org.apache.dubbo.common.extension.ExtensionLoader#loadLoadingStrategies,如下图所示:
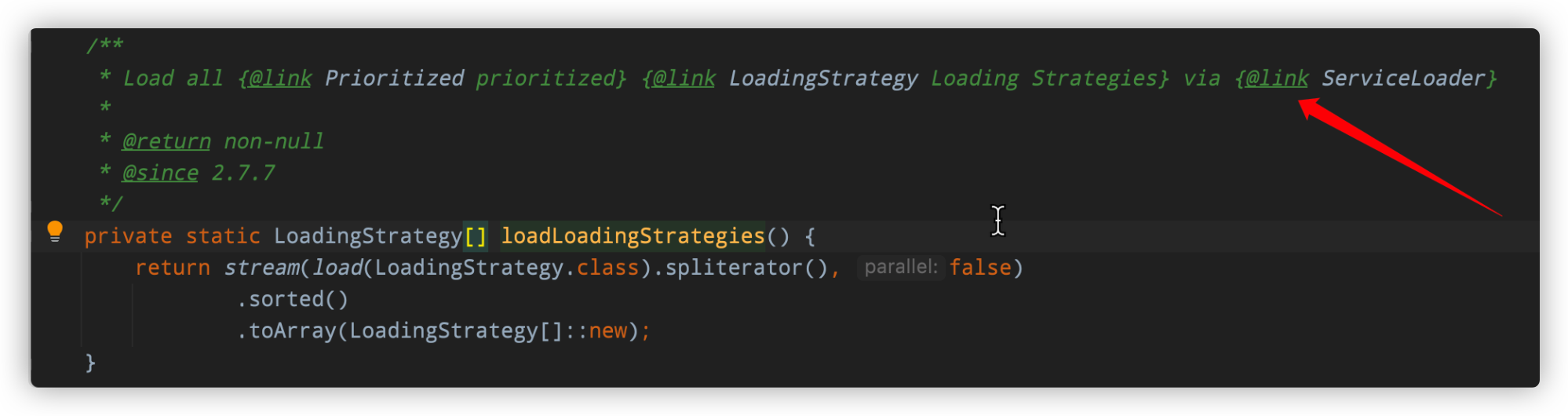 我们查看Dubbo Jar包内的
我们查看Dubbo Jar包内的META-INF/services/目录也能看到以下内容
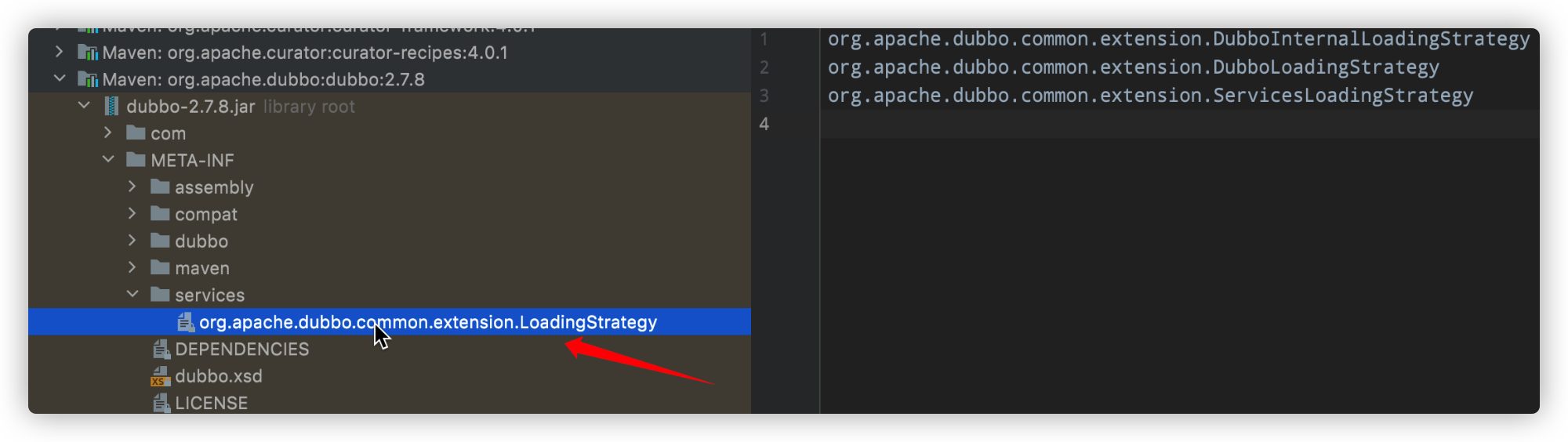
loadClass方法分析
在了解了LoadingStrategy之后,我们回头继续分析扩展点实现类的加载流程
-
org.apache.dubbo.common.extension.ExtensionLoader#loadExtensionClasses☞ 入口⇣⇣⇣⇣
-
org.apache.dubbo.common.extension.ExtensionLoader#loadDirectory☞ 加载目录⇣⇣⇣⇣
-
org.apache.dubbo.common.extension.ExtensionLoader#loadResource☞ 一个目录下会有很多配置文件,逐个解析配置文件⇣⇣⇣⇣
-
org.apache.dubbo.common.extension.ExtensionLoader#loadClass☞ 通过配置文件可以拿到全类名,加载并缓存
整个流程还是非常清晰的,先加载目录,通过对前面LoadingStrategy学习大家应该知道,不同加载策略的加载目录是不同的。目录加载完成后会得到一个配置文件列表,之后通过loadResource方法逐个加载配置文件,在这个过程中可以拿到所有扩展点实现的全类名,最后加载所有的扩展点实现类,并进行缓存。关于前面配置文件的加载较为简单,本文不做详细介绍,读者可自行阅读源码。我们着重看loadClass方法的处理逻辑,代码如下:
下面的代码忽略了一些简单及异常处理,只保留了核心逻辑
// extensionClasses:一个缓存map,key为SPI名称,value为对应的实现类Class对象
// resourceURL:这个参数传入进来只是为了更好的描述异常信息
// clazz:本次要被加载的类,通过Class.forName(”全类名“, true, classLoader)加载而来
// overridden:对应的加载策略是否允许覆盖已存在的类
private void loadClass(Map> extensionClasses, java.net.URL resourceURL, Class clazz, String name,boolean overridden) throws NoSuchMethodException {// 1️⃣.根据是否存在Adaptive注解判断实现类是否是一个Adaptive类,并进行缓存if (clazz.isAnnotationPresent(Adaptive.class)) {cacheAdaptiveClass(clazz, overridden);// 2️⃣.根据是否存在一个参数类型为当前SPI接口的构造函数判断是否是一个wrapper类,用于AOP} else if (isWrapperClass(clazz)) {cacheWrapperClass(clazz);} else {// 3️⃣.SPI实现类必须要有一个空参构造函数,// 这里相当于一个检查,保证缓存的扩展点实现是可用的// 如果不存在这个构造函数,这一步就会抛出异常clazz.getConstructor();// 4️⃣.如果使用在配置文件中没有对这个SPI扩展点命名,// 那么尝试直接从实现类中解析出该扩展点的名称if (StringUtils.isEmpty(name)) {name = findAnnotationName(clazz);}// 使用逗号对该name进行切割String[] names = NAME_SEPARATOR.split(name);if (ArrayUtils.isNotEmpty(names)) {// 5️⃣.缓存自激活扩展实现类,关于自激活我们在后文中分析cacheActivateClass(clazz, names[0]);for (String n : names) {// 缓存扩展点名称,只会缓存第一个名称cacheName(clazz, n);// 6️⃣.缓存扩展点实现,一个扩展点实现可以有多个名称// 但一个名称只能对应一个扩展点实现saveInExtensionClass(extensionClasses, clazz, n, overridden);}}}
}
上面代码逻辑非常简单,配合注释大家基本能看懂,注释中提到的自激活扩展实现类我会在后文进行分析。经过上面的分析,我们可以得到下面一张关系图:
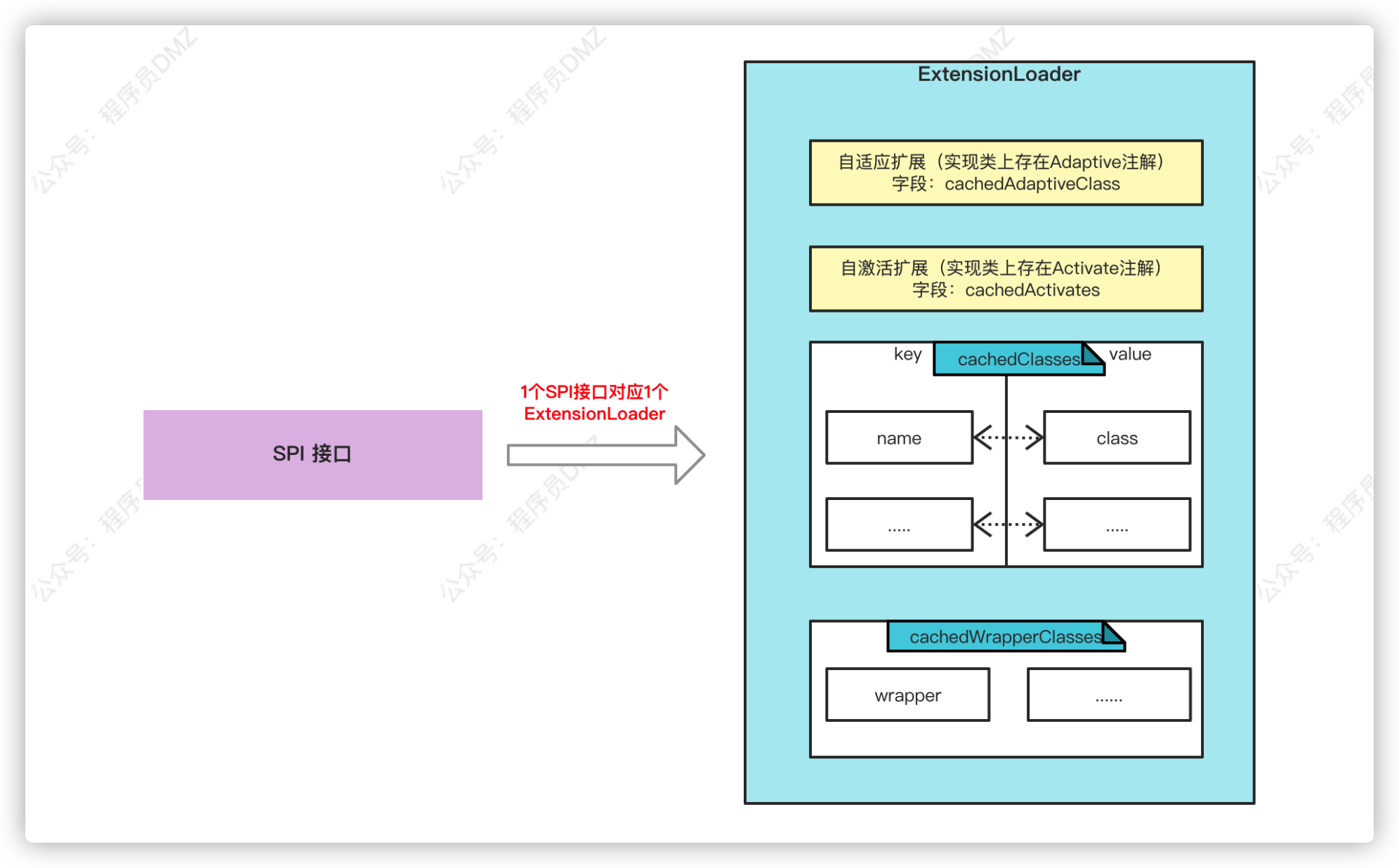
- 一个SPI接口,对应一个
ExtensionLoader - 在
ExtensionLoader中会按照不同的分类将加载的类缓存到不同字段中
到目前为止,我们已经知道了扩展点实现类是如何加载的, 对于整个扩展点实例化的流程我们已经完成了一大部分,再回过头来看一下整个扩展点实例化的流程图,如下:
按照图中流程,我现在应该跟大家介绍Dubbo中的IOC及AOP,不过由于IOC依赖了自适应SPI,所以这里我们先来详细了解一下自适应SPI,关于其使用我已经在之前的文章中介绍过了,本文更多的是分析原理
自适应SPI实现原理
使用自适应扩展的API如下:
ExtensionLoader orderServiceExtensionLoader = ExtensionLoader.getExtensionLoader(SPI接口).getAdaptiveExtension();
自适应扩展的核心代码如下:
private Class getAdaptiveExtensionClass() {// 实际上就是在加载配置文件中的类,并进行缓存 getExtensionClasses();// 是否存在被Adaptive注解修饰的自适应扩展类if (cachedAdaptiveClass != null) {return cachedAdaptiveClass;}// 如果不存在的话,通过代码生成创建一个自适应扩展类return cachedAdaptiveClass = createAdaptiveExtensionClass();
}private Class createAdaptiveExtensionClass() {// 生成代码,其实就是字符串的拼接String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();ClassLoader classLoader = findClassLoader();// 编译,并返回具体的Class对象org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();return compiler.compile(code, classLoader);
}
通过上面的代码要知道的是,自适应SPI有两种形式
- 在扩展点实现类上添加Adaptive注解,指定由这个类来实现自适应逻辑
- 如果我们没有添加Adaptive注解, 那么Dubbo会帮我们生成一个自适应类来完成适配逻辑
自适应扩展代码生成分析
关于代码生成的细节本文不做过多分析,主要是一些字符串的拼接,生成code字符串后再进行编译。我们重点关注最终生成的代码,首先我们编写一个测试接口,如下:
@SPI
public interface AdaptiveSpi {/*** 注意这个方法有两个特征* * 1.方法上有adaptive注解*
* 2.方法的参数中有一个URL,需要注意的是这是一个org.apache.dubbo.common.URL,不是java.net.URL*/@Adaptive("adaptive1")void adaptiveMethod1(URL url);@Adaptive("adaptive2")void adaptiveMethod2(URLHolder url);@Adaptivevoid adaptiveMethod3(URLHolder url, Invocation invocation);/*** 普通方法,用于观察最终生成的代码*/void normalMethod();class URLHolder {private final URL url;public URLHolder(URL url) {this.url = url;}public URL getUrl() {return url;}}
}
对应的生成的自适应扩展实现类代码如下:
限于篇幅问题,在下面的代码中我省去了一些检查相关代码。例如:url不能为空,扩展点名称不能为空等
public class AdaptiveSpi$Adaptive implements com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi {public void adaptiveMethod1(com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi.URLHolder arg0) {org.apache.dubbo.common.URL url = arg0.getUrl();String extName = url.getParameter("adaptive1");com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi extension = (com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi) ExtensionLoader.getExtensionLoader(com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi.class).getExtension(extName);extension.adaptiveMethod2(arg0);}public void adaptiveMethod2(org.apache.dubbo.common.URL arg0) {org.apache.dubbo.common.URL url = arg0;String extName = url.getParameter("adaptive2");com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi extension = (com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi) ExtensionLoader.getExtensionLoader(com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi.class).getExtension(extName);extension.adaptiveMethod1(arg0);}public void adaptiveMethod3(com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi.URLHolder arg0, org.apache.dubbo.rpc.Invocation arg1) {org.apache.dubbo.common.URL url = arg0.getUrl();String methodName = arg1.getMethodName();String extName = url.getMethodParameter(methodName, "adaptive.spi", "null");com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi extension = (com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi) ExtensionLoader.getExtensionLoader(com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi.class).getExtension(extName);extension.adaptiveMethod3(arg0, arg1);}public void normalMethod() {throw new UnsupportedOperationException("The method public abstract void com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi.normalMethod() of interface com.easy4coding.dubbo.spi.service.adaptive.AdaptiveSpi is not adaptive method!");}
}
观察上面3个方法,我们可以得出以下结论:
-
自适应SPI接口上中的方法如果要用到自适应的能力,必须要有
@Adaptive注解,例如的normalMethod直接抛出了UnsupportedOperationException。所谓自适应能力,我们在上篇文章中已经解释过了,就是根据方法调用的参数去适配真实的SPI实现类 -
自适应SPI实际调用的是其它实际的扩展点实现类,调用的API就是我们之前分析过的
ExtensionLoader.getExtensionLoader(扩展点名称).getExtension()。 -
真正要使用的扩展点的名称是从URL的参数中解析出来的,同时会将
@Adaptive注解中的值作为key,从而去从URL中解析出扩展点名称,如果@Adaptive注解中没有配置value属性的话,那么会将类名转换为key,如果类名是驼峰命名的方式的话,那么会将驼峰转换为"."分隔的形式,例如AdaptiveSpi会被转换为adaptive.spi(见adaptiveMethod3中的逻辑) -
另外,根据自适应方法(被
@Adaptive注解修饰的方法)的参数中是否存在org.apache.dubbo.rpc.Invocation,Dubbo从URL中解析扩展点名称的方式也存在一些差异,如果存在Invocation类型的参数,那么调用的是url.getMethodParameter(见adaptiveMethod3中的逻辑),如果不存在Invocation类型的参数调用的是url.getParameterorg.apache.dubbo.rpc.Invocation代表一次具体的RPC调用,它持有调用过程中的变量,比如方法名,参数等
自激活SPI
接下来我们学习自激活SPI,什么是自激活SPI呢?顾名思义,这一类的SPI扩展点是不需要显式的传入扩展点名称来获取的,而是当满足一定条件时,会自动返回。看到这里,你可能还不明白,没有关系,我们来看一个例子。
简单使用
@SPI
public interface ActivateSpi {void activateMethod();
}public class FirstActivateSpiImpl implements ActivateSpi {@Overridepublic void activateMethod() {System.out.println("activate first");}
}// ❤️ 注意这个注解
@Activate("second")
public class SecondActivateSpiImpl implements ActivateSpi {@Overridepublic void activateMethod() {System.out.println("activate second");}
}public static void main(String[] args) { URL url = new URL("","",0);url = url.addParameter("second","1");// 明确表明要加载的扩展点是firstString[] extensionNames = new String[]{"first"};final List activateExtension = ExtensionLoader.getExtensionLoader(ActivateSpi.class).getActivateExtension(url, extensionNames);activateExtension.forEach(ActivateSpi::activateMethod);
}// 程序输出:
// activate second
// activate first
不忘忘记要添加配置文件哈~
first=com.easy4coding.dubbo.spi.service.activate.FirstActivateSpiImpl second=com.easy4coding.dubbo.spi.service.activate.SecondActivateSpiImpl
在上面的例子中我们可以看到,当我们调用getActivateExtension时,显示传入的扩展点名称是first,但此方法返回的扩展点不仅仅有first,second也被加载了,这说明second这个扩展点自己激活了自己,这就是自激活SPI,接下来我们来分析一下其实现原理
原理分析
核心的API如下:
// key:用于从url中获取到具体的扩展点名称
public List getActivateExtension(URL url, String key, String group) {// 通过key,从url中获取对应的value,并将其作为扩展点名称String value = url.getParameter(key);return getActivateExtension(url, StringUtils.isEmpty(value) ? null : COMMA_SPLIT_PATTERN.split(value), group);
}
// values:代表要显式获取到的扩展点名称,具体源码我们在后文中分析
public List getActivateExtension(URL url, String[] values, String group) {...}
我们基于以上API进行分析其原理
Activate注解
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Activate {// 匹配通过API调用时方法参数中传入的groupString[] group() default {};// 用于跟Url中的参数进行匹配,只有匹配成功扩展点才会激活String[] value() default {};// 从2.7版本已经过时,用于排序,指定顺序在某一扩展点前@DeprecatedString[] before() default {};// 从2.7版本已经过时,用于排序,指定顺序在某一扩展点后@DeprecatedString[] after() default {};// 用于排序int order() default 0;
}
Activate注解中的group及value属性主要用于跟之前提到的API中传入的参数进行匹配,另外几个属性主要用于对加载的扩展点进行排序。
源码分析
核心代码位于:org.apache.dubbo.common.extension.ExtensionLoader#getActivateExtension(URL,String[],String)
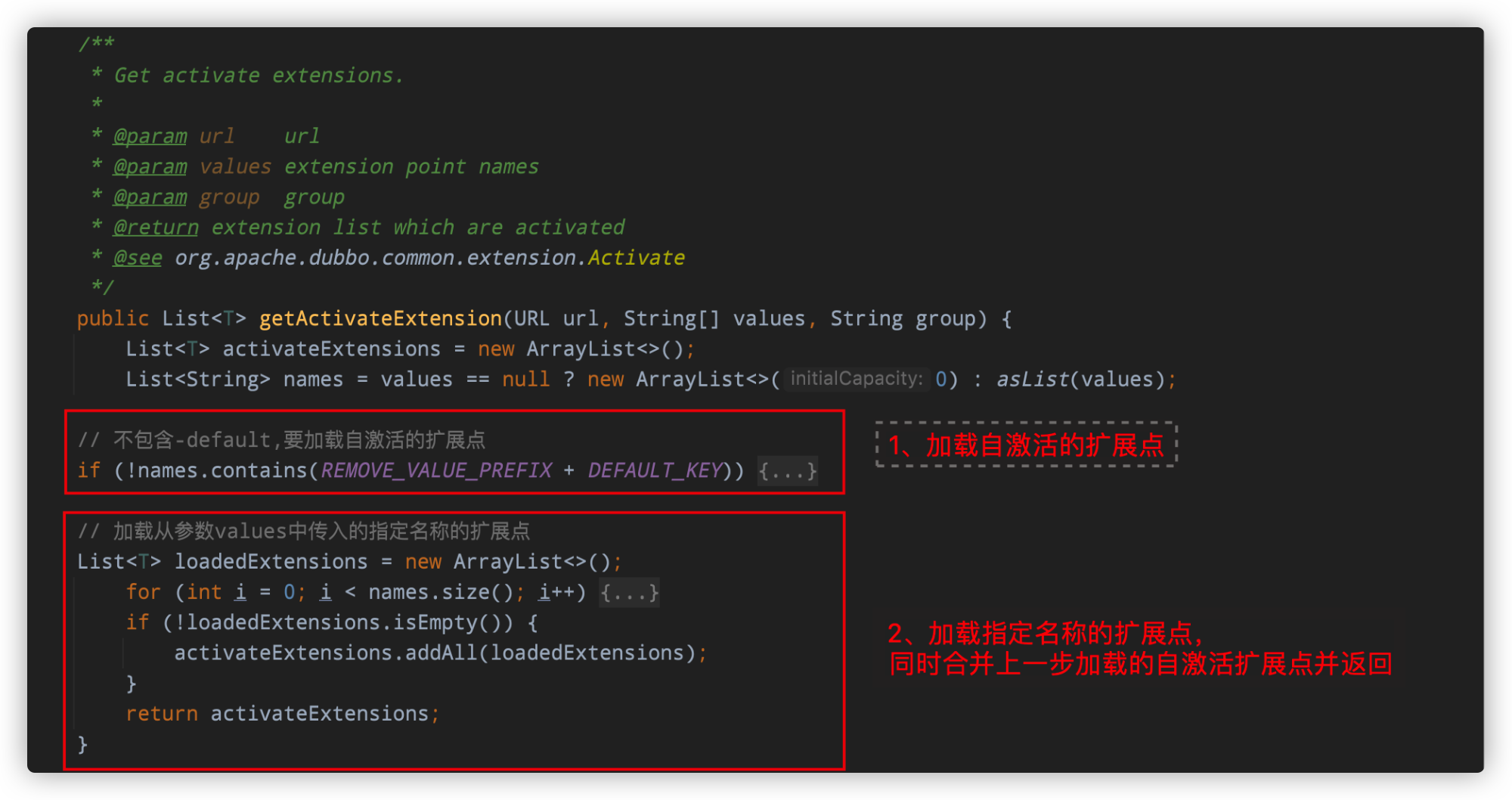
整个代码逻辑并不难,核心逻辑可以分为两部分
-
判断传入的扩展点名称中是否包含
-default,如果包含,代表不需要自激活的扩展点,只加载名称在values数组中的扩展点实现。-代表指定要排除某一个扩展点,例如传入的valuse集合为:[“name1”,“name2”,“-name3”],则代表要使用"name1","name2"及自激活的SPI扩展点实现,同时排除名称为"name3"的扩展点实现代码如下:
if (!names.contains(REMOVE_VALUE_PREFIX + DEFAULT_KEY)) {// 前文已经分析过,调用这个方法会去读取SPI配置文件并加载所有的类缓存到不同的集合中getExtensionClasses();// cachedActivates中缓存的是被Activate注解修饰的扩展点实现for (Map.Entry上面代码的核心在于,如何判断一个SPI实现是不是自激活的,对应判断条件如下:
-
isMatchGroup(group, activateGroup),分组是否匹配。在group参数不为空的情况下,要求Activate注解中的group的值必须跟方法参数group的值匹配。 -
!names.contains(name),不能是显示获取的扩展点,主要是为了排序,显示加载的扩展点会在后面进行统一加载 -
!names.contains(REMOVE_VALUE_PREFIX + name),不能是显示排除的扩展点 -
isActive(activateValue, url),必须跟URL中的key是匹配的,代码如下,注释中已经做了详细介绍,笔者不再过多介绍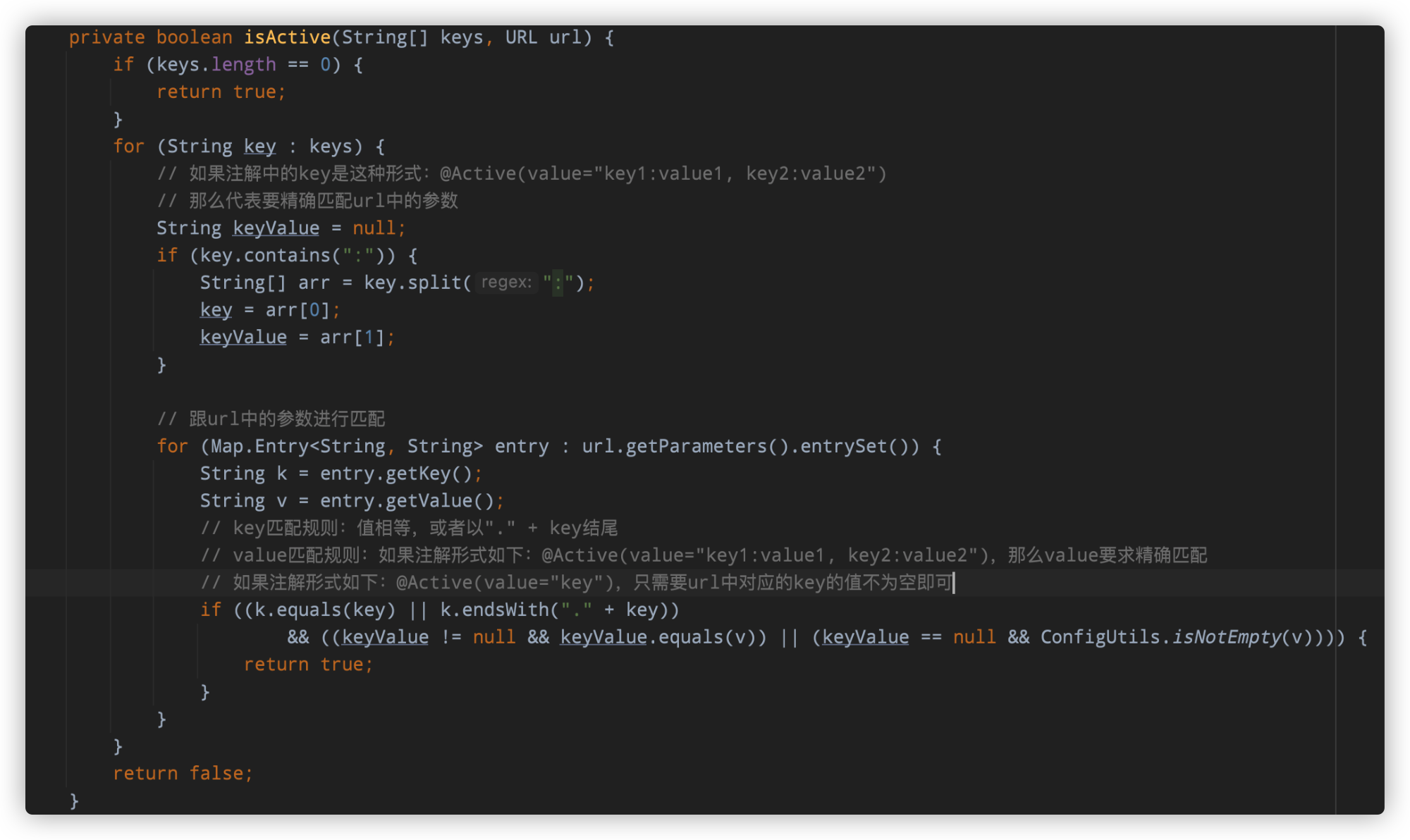
-
-
加载指定名称的扩展点实现
ListloadedExtensions = new ArrayList<>();for (int i = 0; i < names.size(); i++) {String name = names.get(i);if (!name.startsWith(REMOVE_VALUE_PREFIX)&& !names.contains(REMOVE_VALUE_PREFIX + name)) {if (DEFAULT_KEY.equals(name)) {if (!loadedExtensions.isEmpty()) {// default代表了自激活扩展点,这里主要是为了排序activateExtensions.addAll(0, loadedExtensions);loadedExtensions.clear();}} else {loadedExtensions.add(getExtension(name));}}}if (!loadedExtensions.isEmpty()) {// 最终都放入activateExtensions集合中统一返回activateExtensions.addAll(loadedExtensions);}
不知道大家有没有注意到,在分析上面两步时,文中都提到了一个词:排序。主要是因为这个方法最终返回的扩展点集合包含了两部分内容
- 自激活的扩展点
- 指定名称,显示申明要使用的扩展点(通过values参数申明)
对于自激活的扩展点,由于它们都被Activate注解修饰,因此可以直接依赖Activate注解对其进行排序,但是另外一部分显示要申明的扩展点要怎么办呢?Dubbo的做法是
- 默认自激活扩展点的顺序高于显式申明要使用的扩展点,所以最后一行代码调用了
activateExtensions.addAll(loadedExtensions) - 可以在
values参数中通过传入default值的方式来指定自激活扩展点的顺序。举个例子,如果传入的values值为:[“name1”,“name2”,“default”,“name3”],那么"name1",“name2"对应的扩展点实现的顺序高于自激活扩展点的顺序,自激活扩展点的顺序高于"name3"对应的扩展点实现。如果传入的如果传入的values值为[“name1”,“name2”,“name3”],不包含"default"的情况下,自激活扩展点的顺序高于"name1”,“name2”,"name3"对应的扩展点实现
到现在为止我们已经基本已经掌握了Dubbo中的SPI的核心内容,接下来我们要学习更高阶的知识了☞Dubbo中的IOC及AOP
通过前文我们应该知道,IOC及AOP发生在扩展点实例化的过程中,整个流程图如下:

核心代码如下:
private T createExtension(String name, boolean wrap) {// 1️⃣.加载扩展点实现类,得到class对象Class clazz = getExtensionClasses().get(name);// 2️⃣.这里通过反射调用空参构造函数,完成实例化T instance = (T) EXTENSION_INSTANCES.get(clazz);if (instance == null) { EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());instance = (T) EXTENSION_INSTANCES.get(clazz);}// 3️⃣.IOCinjectExtension(instance);// 4️⃣.AOPif (wrap) {// .....}// 5️⃣.扩展点生命周期,进一步完成初始化initExtension(instance);return instance;
}
接下来我们来分析整个IOC的过程,代码并不难哈~😎
IOC实现原理
核心代码如下:

可以看到代码真的非常简单,大概逻辑分为这么几步
- 判断setter方法上是否有
DisableInject注解,这个注解代表不需要进行注入 - 从
objectFactory中获取到一个指定名称的对象并反射调用setter方法进行注入
所以,我们要理解IOC首先要搞懂objectFactory是什么
objectFactory介绍

我们可以看到,objectFactory是在创建ExtensionLoader的过程中被初始化的,同时它是一个自适应SPI,对应的接口类型为:ExtensionFactory。这种情况,我们首先去查找它的SPI配置文件,如下: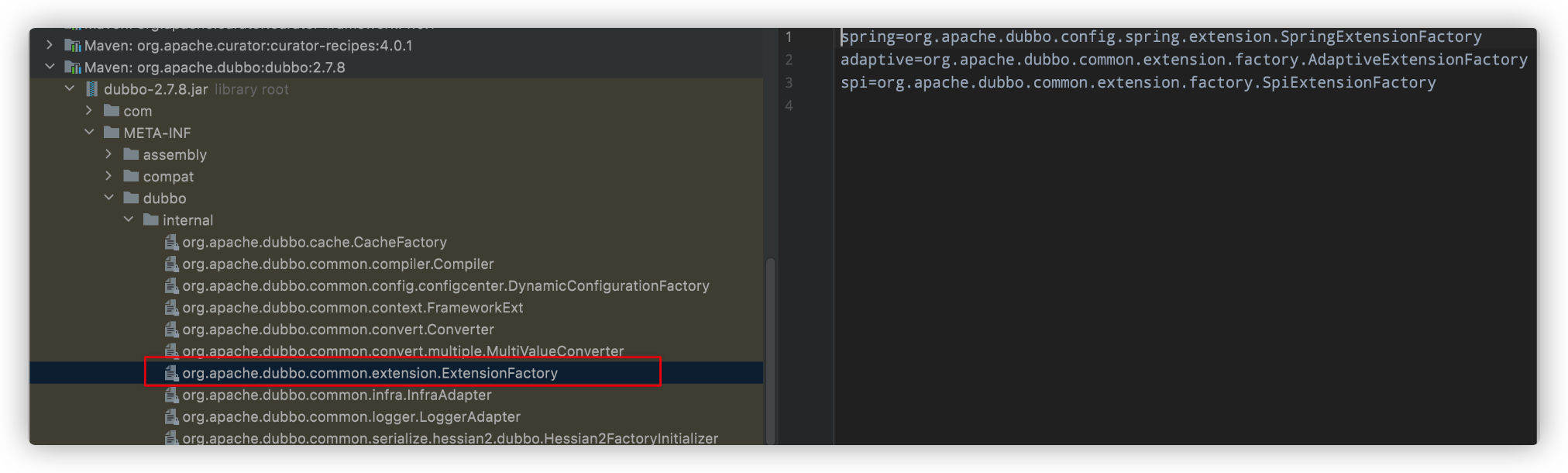
在其配置文件中存在三个SPI实现类
spring=org.apache.dubbo.config.spring.extension.SpringExtensionFactory
adaptive=org.apache.dubbo.common.extension.factory.AdaptiveExtensionFactory
spi=org.apache.dubbo.common.extension.factory.SpiExtensionFactory
我们分别查看对应的三个SPI实现会发在,在AdaptiveExtensionFactory这个实现类有一个@Adaptive注解,代表调用API获取自适应SPI时,真正返回的是这个类,这个类做的更多的是适配的工作,真正干活的还是SpringExtensionFactory及SpiExtensionFactory。SpringExtensionFactory这个类的作用是从Spring容器中获取到指定的Bean,而SpiExtensionFactory这个类的作用是依赖Dubbo的SPI机制获取到指定的对象,它们都是服务于Dubbo的IOC机制。
因为代码比较简单,这里我们就看一下AdaptiveExtensionFactory的代码:
AdaptiveExtensionFactory
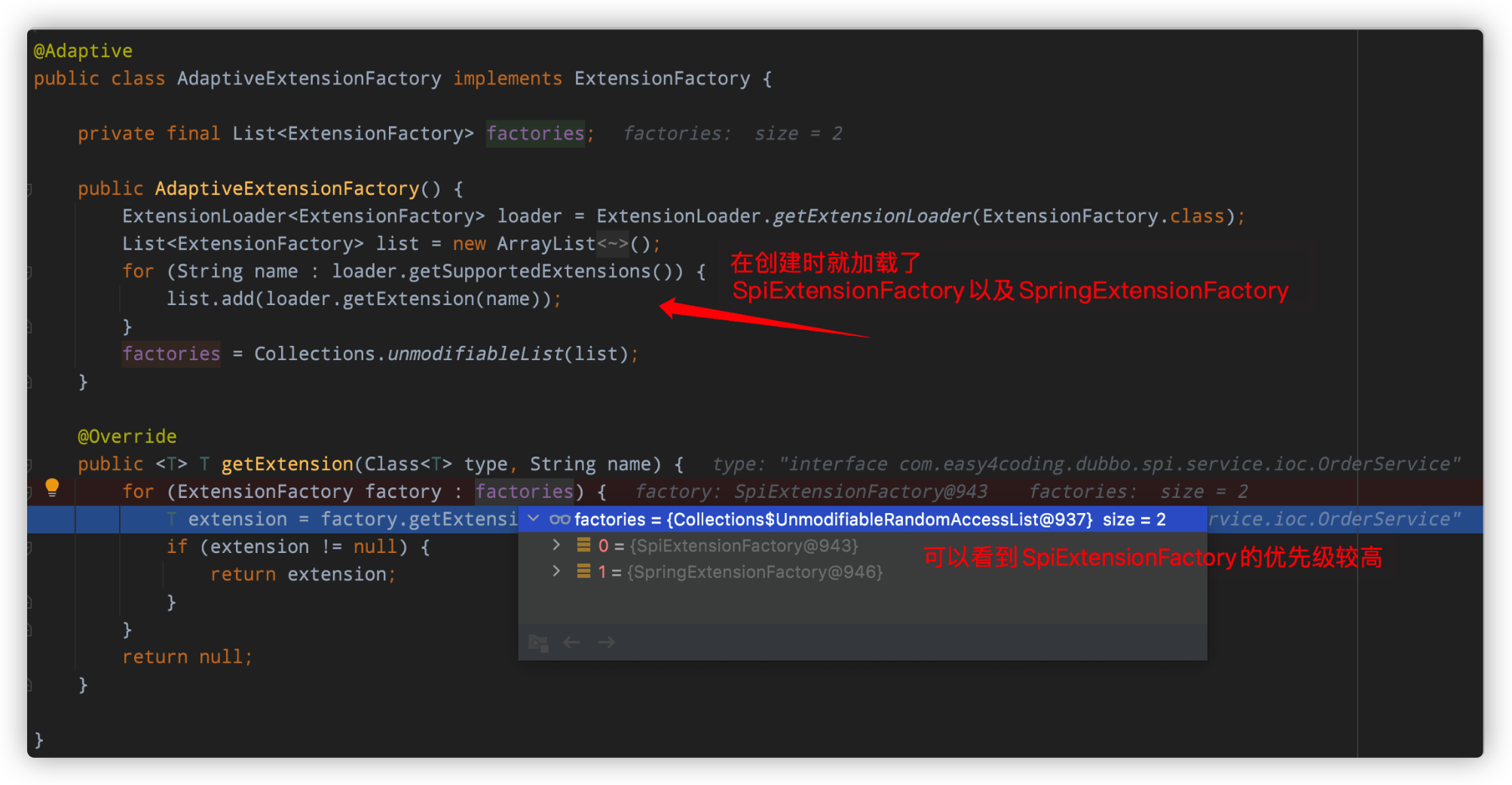
注意哦:dubbo中SPI实现类的优先级会高于spring容器中bean的优先级
现在我们已经知道了objectFactory的作用,那么IOC就已经没有任何秘密。简单总结一下:
总结
- IOC发生的时机:在实例化SPI实现时进行IOC
- IOC的条件
- 存在setter方法
- setter方法上没有
DisableInject注解 - 在进行IOC时,被注入的对象是通过
objectFactory获取,objectFactory是通过自适应SPI进行初始化的,实际上它会优先尝试使用Dubbo的SPI获取一个对象,如果获取到了,只会返回。如果没有获取到,那么会再次从Spring容器中获取一个对应的bean。
AOP实现原理
AOP的实现就更加简单了,实现AOP的关键是依赖通过loadExtensionClasses方法加载的wrapper类,还记得loadExtensionClasses干了啥吗?回顾一下这张图
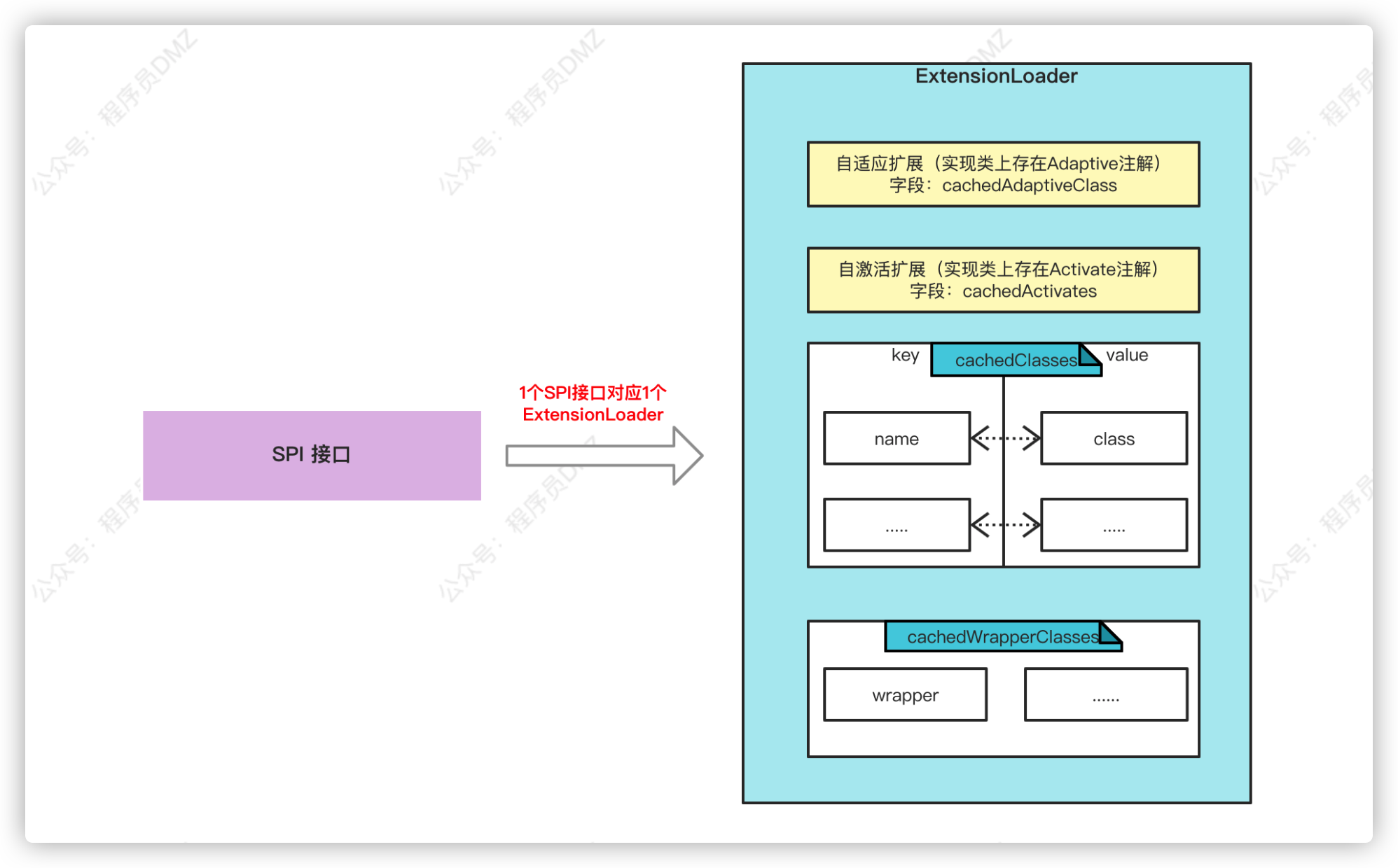
AOP的核心代码如下:
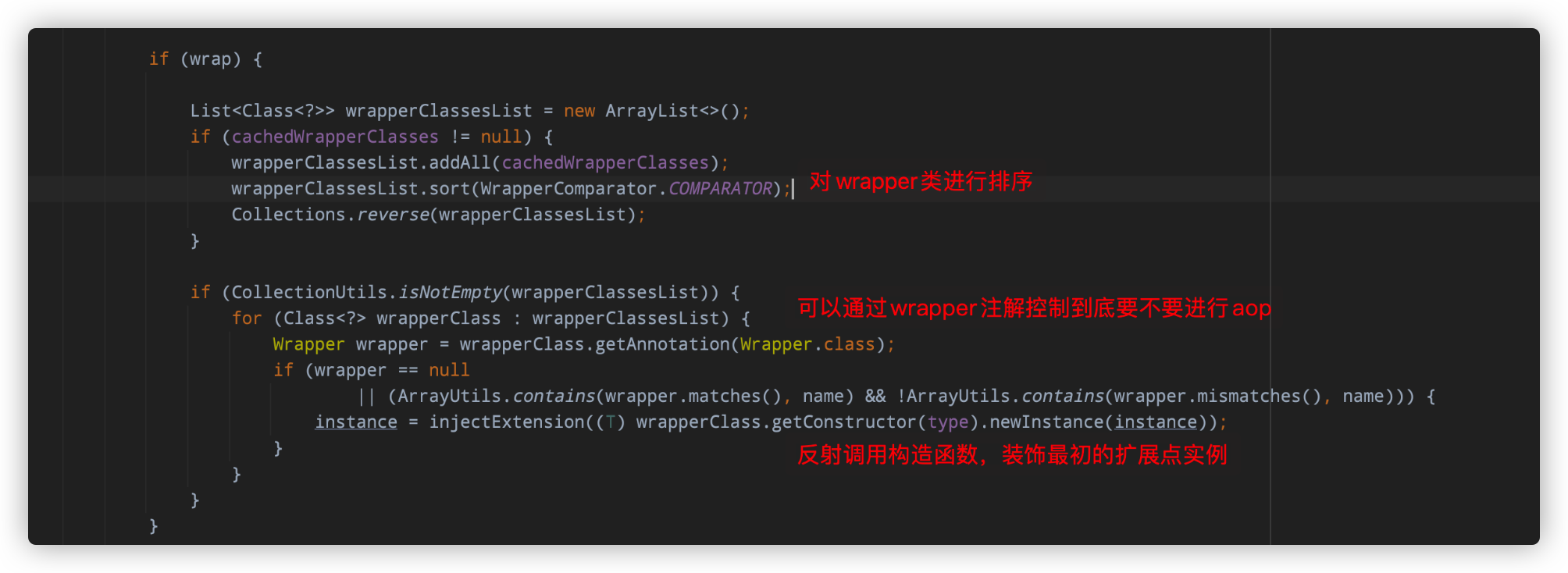 Dubbo的AOP说白了就是依靠wrapper类来对真实的扩展点进行一次包装,wrapper类持有一个真实的扩展点实现引用!
Dubbo的AOP说白了就是依靠wrapper类来对真实的扩展点进行一次包装,wrapper类持有一个真实的扩展点实现引用!
总结
这篇文章我们分析了Dubbo中的各种SPI实现,以及Dubbo基于SPI扩展出来功能:IOC、AOP。我相信只要大家认真看完这篇文章,积极动手实践,搞懂Dubbo的SPI是没有任何问题。要学好Dubbo,掌握SPI是第一步,整个框架中用到SPI的地方数不胜数。
谢谢你看完这篇文章,也请你谢谢认真学习的自己!