
java LinkedHashSet 源码分析(深度讲解)
目录
一、前言
二、LinkedHashSet简介
三、LinkedHashSet的底层实现
四、LinkedHashSet的源码解读(断点调试)
0.准备工作 :
1.向集合中添加第一个元素 :
①跳入无参构造。
②跳入resize方法。
③threshold发生改变的真正原因。
④继续回到resize方法。
⑤回到演示类方法。
⑥多态数组的体现。
2.继续向集合添加元素 :
①向集合中添加重复元素。
②向集合中添加第二个元素。
③向集合中添加第三个元素。
④向集合中添加第四、五、六个元素。
五、完结撒❀
一、前言
大家好,本篇博文是对集合篇章——单列集合Set的内容补充。Set集合常见的实现类有两个——HashSet和TreeSet。上一篇博文中我们已经分析了HashSet的源码,知道了HashSet的底层其实就是HashMap。今天我们要解读的是HashSet的一个子类——LinkedHashSet。(建议先阅读HashSet源码分析)
注意 : ①解读源码需要扎实的基础,比较适合希望深究的同学; ②不要眼高手低,看会了不代表你会了,自己能全程Debug下来才算有收获; ③点击文章的侧边栏目录或者前面的目录可以进行跳转。良工不示人以朴,up所有文章都会适时改进。大家有问题都可以在评论区讨论交流,或者私信up。 感谢阅读!
二、LinkedHashSet简介
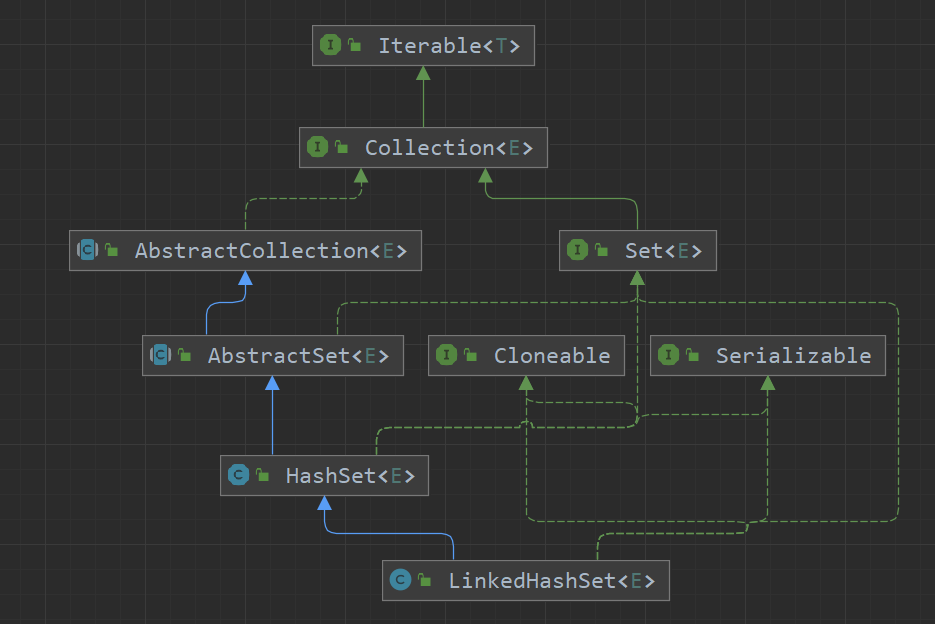
1.LinkedHashSet是HashSet的子类,而由于HashSet实现了Set接口,因此LinkedHashSet也间接实现了Set类。LinkedHashSet类属于java.base模块,java.util包下,如下图所示 :

我们再来看一下LinkedHashSet的类图,如下 :
2.LinkedHashSet底层是一个LinkedHashMap,是"数组 + 双向链表"的结构。
3.LinkedHashSet也具有Set集合"不可重复"的特点。但由于LinkedHashSet根据元素的hashCode值来决定元素的存储位置,同时使用双向链表来维护元素的次序,所以这就使得元素看起来是以插入顺序保存的。
三、LinkedHashSet的底层实现
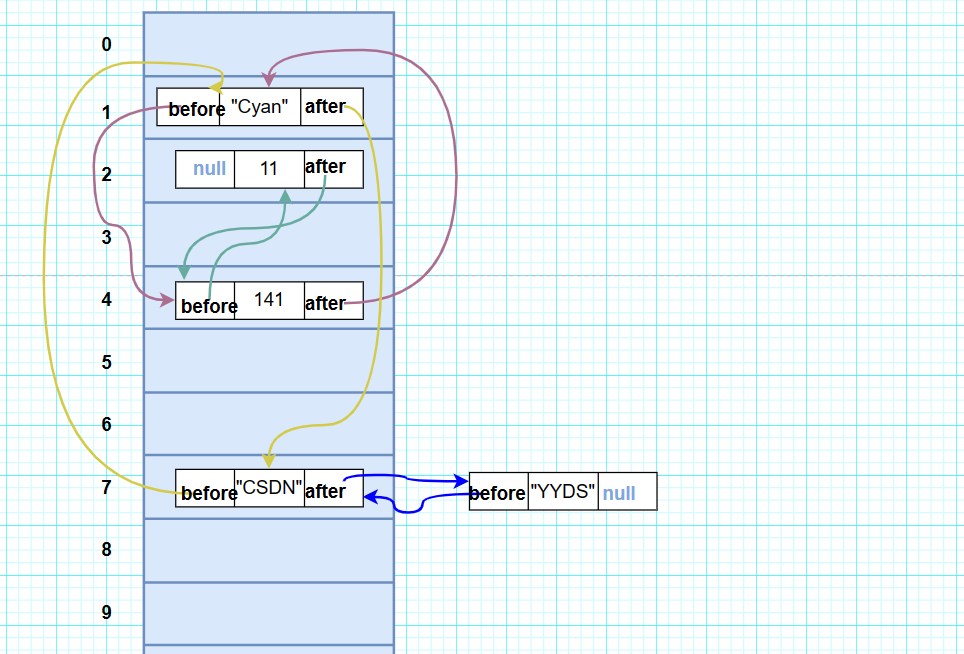
1.LinkedHashSet在底层维护了一个hash表(table)和双向链表。(LinkedHashSet和LinkedList一样也有head和tail)。
2.每个节点中维护了before,item,after三个属性,其中通过before指向前一个结点,通过after指向后一个结点,从而实现双向链表。
3.LinkedHashSet在添加元素时的底层规则和HashSet一样,即先求该元素的hash值,根据特定算法求得该元素在hashtable中应该存放的位置。如果该位置已经有相同元素,放弃添加;反之则将该元素加入到双向链表。
4.LinkedHashSet的底层其实就是LinkedHashMap,关于这一点,要类比HashSet的底层是HashMap。
5.LinkedHashSet的底层机制图示 :
四、LinkedHashSet的源码解读(断点调试)
0.准备工作 :
up以LinkedHashSet_Demo类为演示类,代码如下 : (main函数第一行设置断点)
package csdn.knowledge.api_tools.gather.set;import java.util.LinkedHashSet;
import java.util.Objects;/*** @author : Cyan_RA9* @version : 21.0*/
public class LinkedHashSet_Demo {public static void main(String[] args) {LinkedHashSet linkedHashSet = new LinkedHashSet();linkedHashSet.add(141);linkedHashSet.add(141);linkedHashSet.add("CSDN");linkedHashSet.add(11);linkedHashSet.add("Cyan");linkedHashSet.add(new Apple("红富士"));linkedHashSet.add(new Apple("红富士"));}
}class Apple {private String name;public Apple(String name) {this.name = name;}@Overridepublic int hashCode() {return 100;}
}1.向集合中添加第一个元素 :
①跳入无参构造。
首先我们跳入LinkedHashSet的无参构造,如下图所示 :

底层调用了其父类HashSet 的一个带参构造,我们继续追进去看看,如下 :

可以看到,最终调用的还是LinkedHashMap的构造器。(LinkedHashMap是HashMap的子类)
好的,接下来我们跳出构造器,回到演示类中,如下 :

可以看到,此时的map对象是LinkedHashMap类型。
②跳入resize方法。
准备向集合中添加第一个元素,注意,LinkedHashMap和HashMap在底层添加元素时,几乎完全一样,前面几步像是跳入add方法 ——> 跳入put方法 ——> 跳入putVal方法二者是完全一致的。up这里就不再赘述了,因为在之前的HashSet源码分析中我们已经非常详细地说过了,这里再长篇大论地给大家讲就真的有水博客的嫌疑了,虽然up蛮喜欢水博客的(bushi)。因此,为了大家的阅读体验,强烈建议大家在看本篇"LinkedHashSet"的源码分析之前,先去看看up写得"HashSet"源码分析。
我们直接从二者不一样的地方开始说起。在putVal方法中,第一个if语句满足判断,如下 :

可以看到,我们要进入resize方法对tab数组进行扩容,resize方法要返回一个Node类型的数组给tab数组。我们跳入resize方法,resize方法源码如下:
final Node[] resize() {Node[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node[] newTab = (Node[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode)e).split(this, newTab, j, oldCap);else { // preserve orderNode loHead = null, loTail = null;Node hiHead = null, hiTail = null;Node next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;} 好的,前面几步都还和HashSet添加第一个元素时一样,如下 :

定义Node数组类型的引用oldTabl,并将table数组赋值给oldTab引用,oldTab也为null;又用一个三目运算符最终将0赋值给了oldCap变量。
下一步开始就要不一样了,如下 :

注意看,不知道大家还记不记得,在HashSet的源码分析中,这里的threshold应该等于0呀。我们再次查看一下threshold的源码,如下 :

欸嘿,奇了怪了,int类型默认值应该为0呀,怎么这里也显示它为16了?
显然,在前面的某一个步骤中,threshold已经被作了修改。这时候可能会有p小将(personable小将,指风度翩翩的人)出来bb
③threshold发生改变的真正原因。
大家仔细想一想,到目前为止,有没有发觉到什么蹊跷的地方?
回顾目前执行过的步骤,呃,也就一个无参构造,后面跳入add方法几步都和HashSet一样我们也没再演示。没错!就是这个无参构造。请大家翻回去看看,我们一开始调用的明明是LinkedHashSet的无参构造,最后真正起到执行效果的却是LinkedHashMap的带参构造。还没发现么?带参构造!这肯定里面有东西呀。
所以,下一步我们直接重新Debug,并回到我们一开始追到HashSet构造器的界面,如下图所示:

注意看实参,初始容量和加载因子,都是老面孔了,这里不再赘述,但要记住它们此时的值——16和0.75。好的,接下来我们就继续追入LinkedHashMap的这个带参构造,看看里面究竟是什么牛马玩意儿,如下图所示 :

哎哟我趣,又是熟悉的复合包皮结构。没想到啊,LInkedHashMap的带参构造,最终却又调用了其父类HashMap的带参构造,不得不说,java语言里面的"啃老"现象,属实有丶严重了。
好的,看个玩笑。我们回到正题,继续追入HashMap的带参构造,如下 :
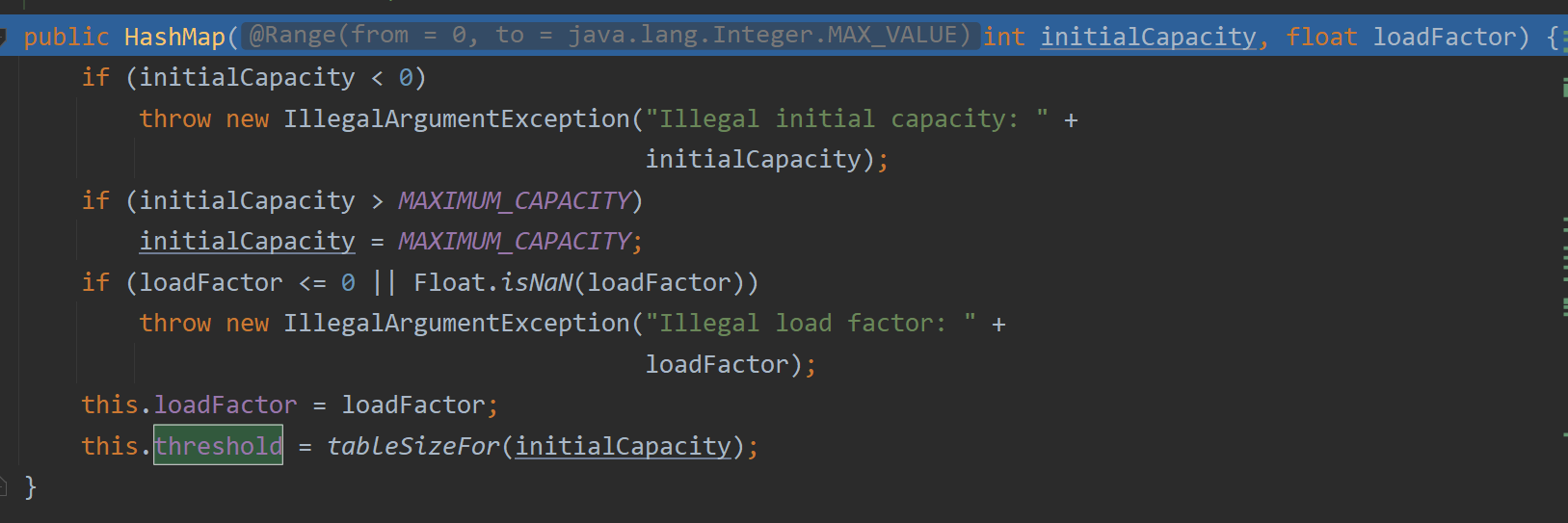
哎哟,这第一眼看上去还挺有货。当然,还是那句话——不要因为走得太远而忘了自己为什么出发。我们半路折回去,不就是想找到为threshold赋值的语句么。
仔细看,最后一句正是我们要找的为threshold赋值的语句。但是该赋值语句中又调用了tableSizeFor方法,见名知意,这个方法和table数组的容量有关。我们也没办法,毕竟已经上了贼船,还是得一路坐到西。
跳入tableSizeFor方法,如下 :

首先,定义了n变量,并通过一个算法为其初始化,这里涉及到了二进制无符号右移的内容,我们不再深究。看右面IDEA提示,我们只需要知道最后n = 15就可以了。
其次,return语句的返回值是一个双重复合的三目运算符。什么意思呢?就是说如果外层三目运算符的判断条件成立,就返回1,否则返回内层三目运算符的结果。而外层判断条件n < 0显然不成立,所以要返回内层三目运算符的结果;内容判断条件n是否大于那一大堆数(将鼠标悬浮在上面可以显示),显然不成立。所以return语句最后返回的值就是 n + 1 = 16。
跳出tableSizeFor方法,如下 :

这下可以解释我们前面的问题了。threshold就是在HashMap的无参构造中被初始化为了16。(注意此处loadFactor属性也被初始化,初始化为了0.75)
④继续回到resize方法。
好的,搞清楚threshold变量变化的原因后,我们可以返回到刚刚的resize方法继续解读。如下 :

可以看到,将threshold(= 16)赋值给oldThr变量后,又定义了newCap(即newCapacity)和newThr(即newThreshold)两个变量。第一个if语句显然判断不成立,不进入它。但后面的else if语句的判断是成立的,如下 :

else if语句中,将newCap赋值为了16。
继续,接下来的一个if语句如下 :

由于threshold的改变,我们并没有进入if-else if-esle中的else语句,而是进入了else if语句,所以newThr变量还是默认值0。这里其实就是将ft赋值给了newThr变量,计算方式仍然是数组容量 * 增长因子 = 16 * 0.75 = 12。
继续,如下图 :

后面几步就都一样了。将临界值12赋值给threshold属性,这才符合逻辑对不对?(关于临界值,up已经在HashSet源码分析中仔细讲过了,大家可以去找一下,这里不再赘述)。
然后,又是new一个长度为16的数组,并最终将table属性初始化。之后有个巨**大的if 语句,不过,幸好,判断为假,我们不用进去😂。
好的,最后就是返回这个新数组了,如下 :

⑤回到演示类方法。
接下来,我们先回到putVal方法,如下 :

仍然是根据当前元素(141)的hash值,通过特定的算法获得当前元素在table数组中应该存放的位置的索引值。然后判断,如果table数组该索引处为空,就直接放进去;不为空的话就去下面的else语句,去链表中一一进行判断。
当然,这些都是在HashSet源码分析中讲过的。以下几个步骤也都一样,我们也不再多说,毕竟老讲重复的东西也没啥意思对不对?
好滴,接下来我们逐层返回,一直到演示类中,如下GIF图所示 :

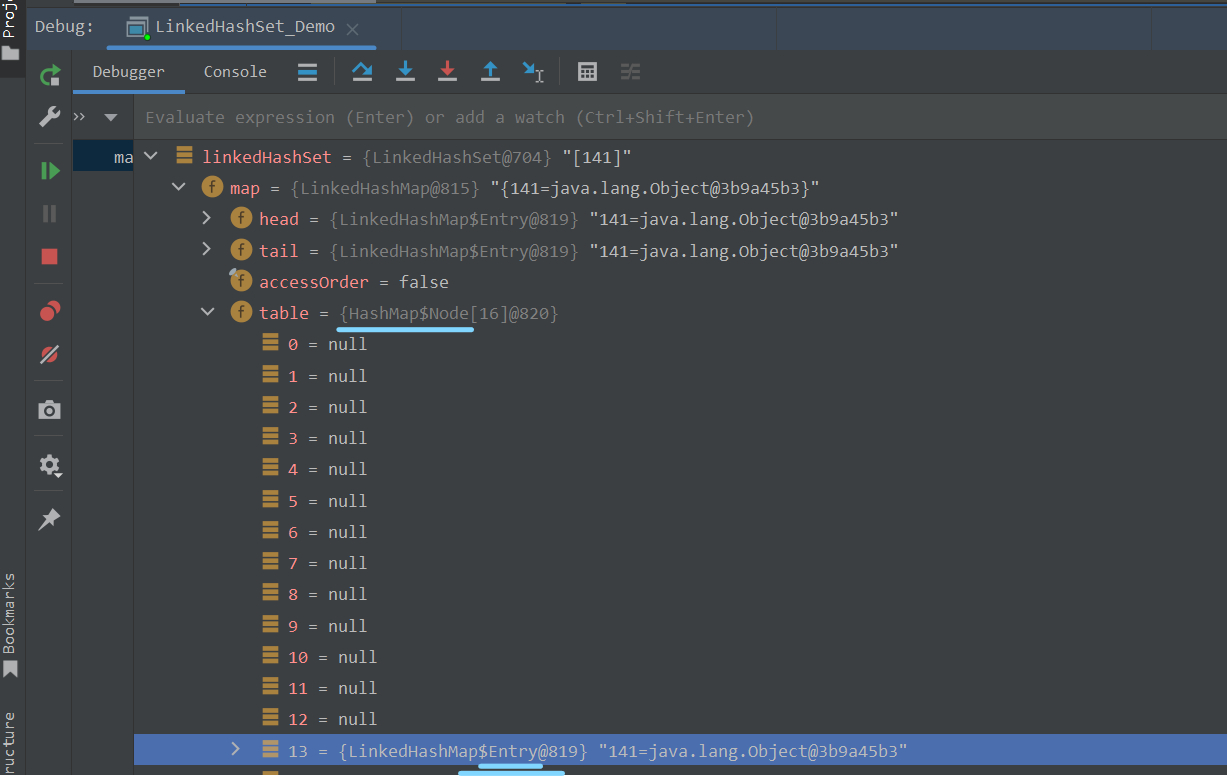
可以看到,table数组成功初始化为长度 = 16的数组,141元素也成功添加到了集合中。
但是注意看,此时table数组仍然是Node类型(LinkedHashMap的内部类),但是里面保存的元素却成了Entry类型(HashMap的内部类)。一个类型的数组里面存放了另一类型的元素,请问,你想到了什么?大声告诉我😎!没错,多态数组。显然,这里的Entry类型一定是继承或者实现了Node类型。
⑥多态数组的体现。
我们来看看Entry类的源码,如下 :
static class Entry extends HashMap.Node {Entry before, after;Entry(int hash, K key, V value, Node next) {super(hash, key, value, next);}} 这下真相大白了,Entry类继承了Node类,因此Node类型数组中存放Entry类型元素达到了多态的效果。大家注意,此处的Node类型是由HashMap通过类名来引用的,显然,Node类型其实就是HashMap类中的一个静态内部类。(关于java中的四种内部类,up之前已出过博文讲解,大家可以移步《java进阶》专栏阅读。)
同时要注意,Entry内部类中定义了before和after属性,即我们在上文"LinkedHashSet的底层实现"中提到的——before指向双向链表的前一个结点,after指向双向链表的后一个结点,从而实现双向链表。
2.继续向集合添加元素 :
①向集合中添加重复元素。
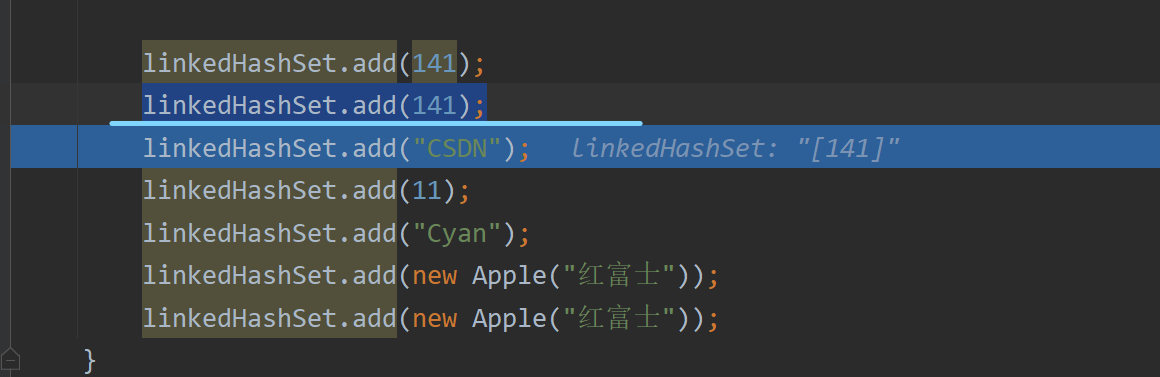
当我们重复添加141元素时,肯定无法加入。底层和HashSet玩得是一套,up就不演示了。大家可以自己下去Debug一次,回顾一下就好。
当然,我们在Debug界面中也可以查看table数组的情况,如下 :

可以看到,此时集合中仍然只有一个元素。
②向集合中添加第二个元素。
继续向下执行,将"CSDN"元素加入集合中。如下图所示 :
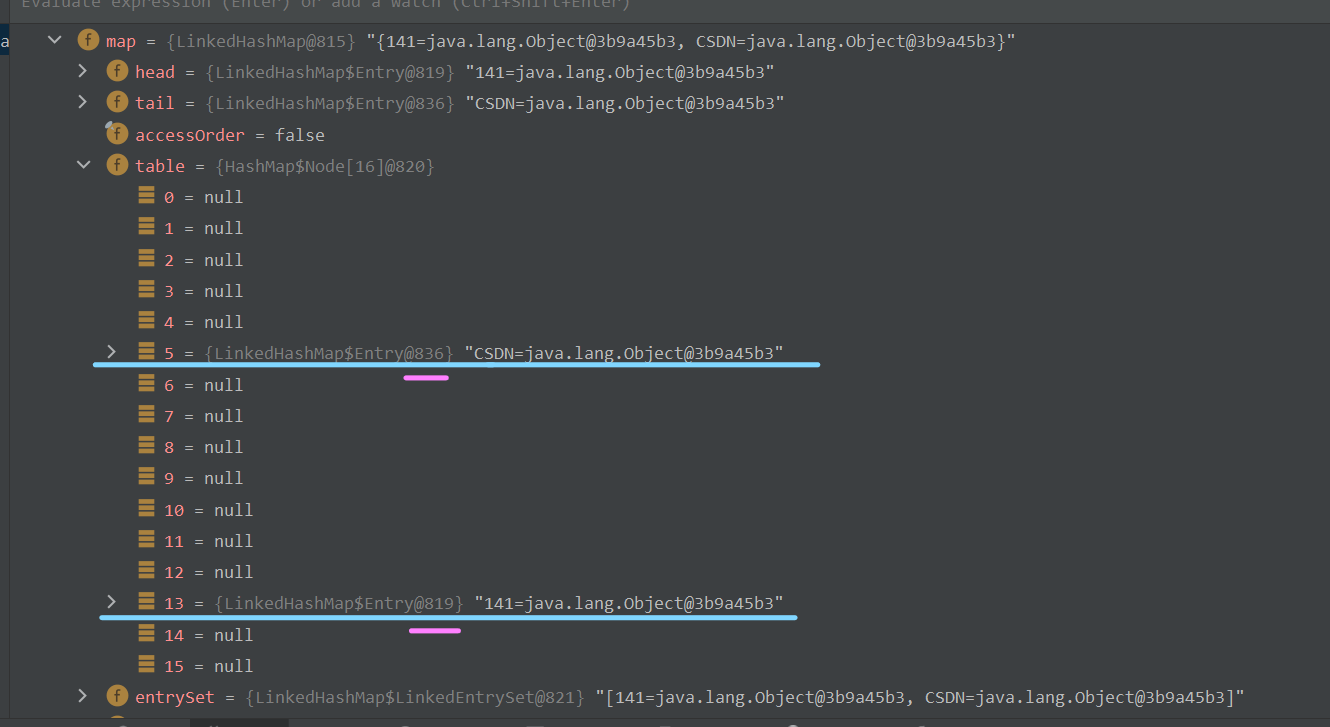
可以看到,目前table数组中已经有俩元素了。注意,记住这俩元素目前的标识——141的标识是819,"CSDN"的标识是836。
注意,精彩的要来了,如下 :
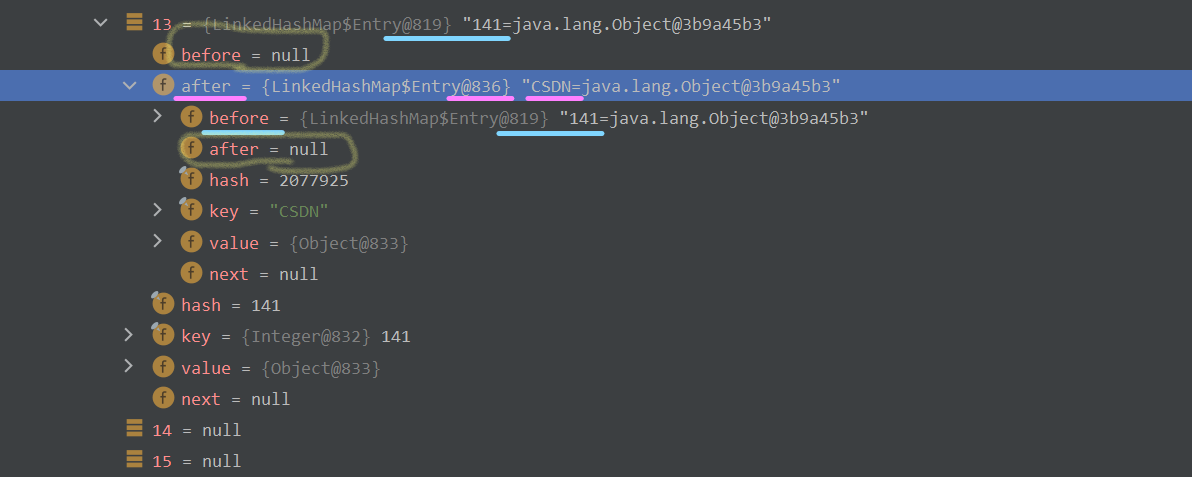
我们点开添加的第一个元素,可以看到,此时第一个元素141的after属性指向了第二个元素"CSDN",而第二个属性的before属性则指向了第一个元素141;并且141元素的before属性和"CSDN"元素的after属性均为null。此时,table数组中的两个元素已然形成了一个简单的双向链表。并且,我们还可以在map对象的界面看到head和tail分别指向了第一个元素和最后一个元素。
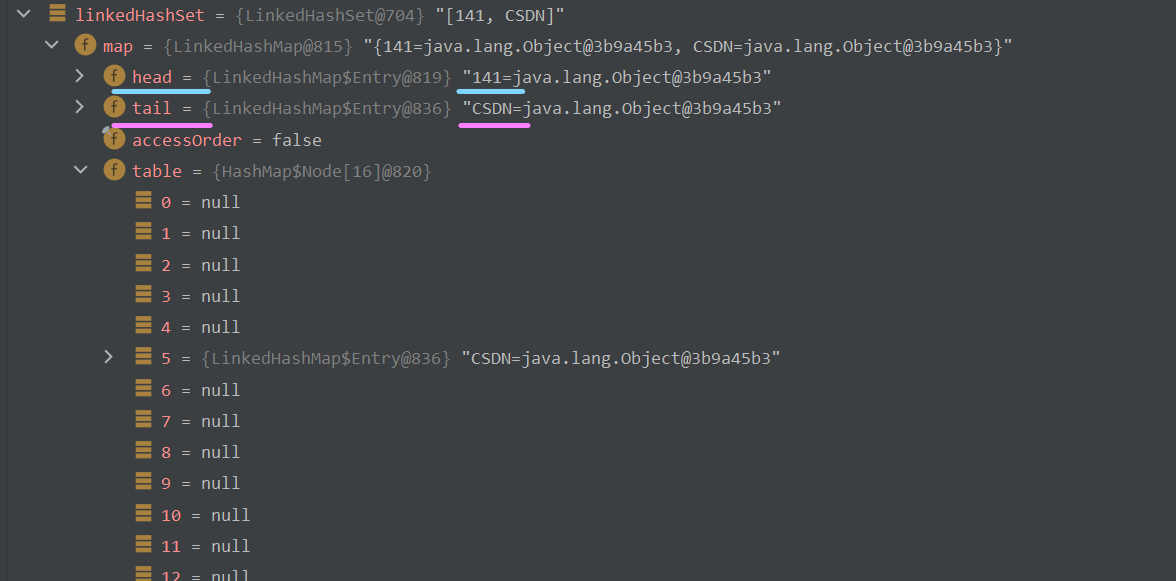
此时,这个简单的双向链表就应该长下面这个样子 :
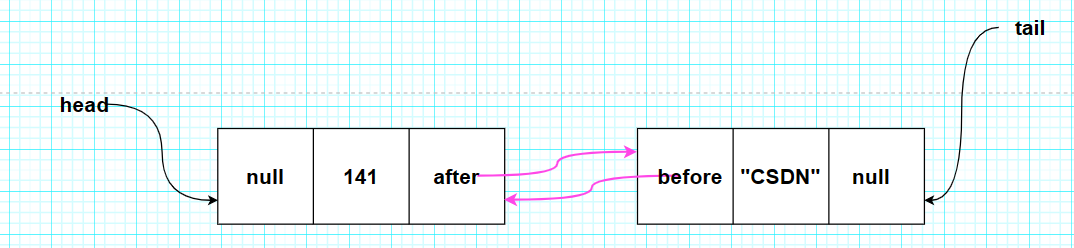
③向集合中添加第三个元素。
继续向下执行,将11元素加入到集合中,如下图所示 :
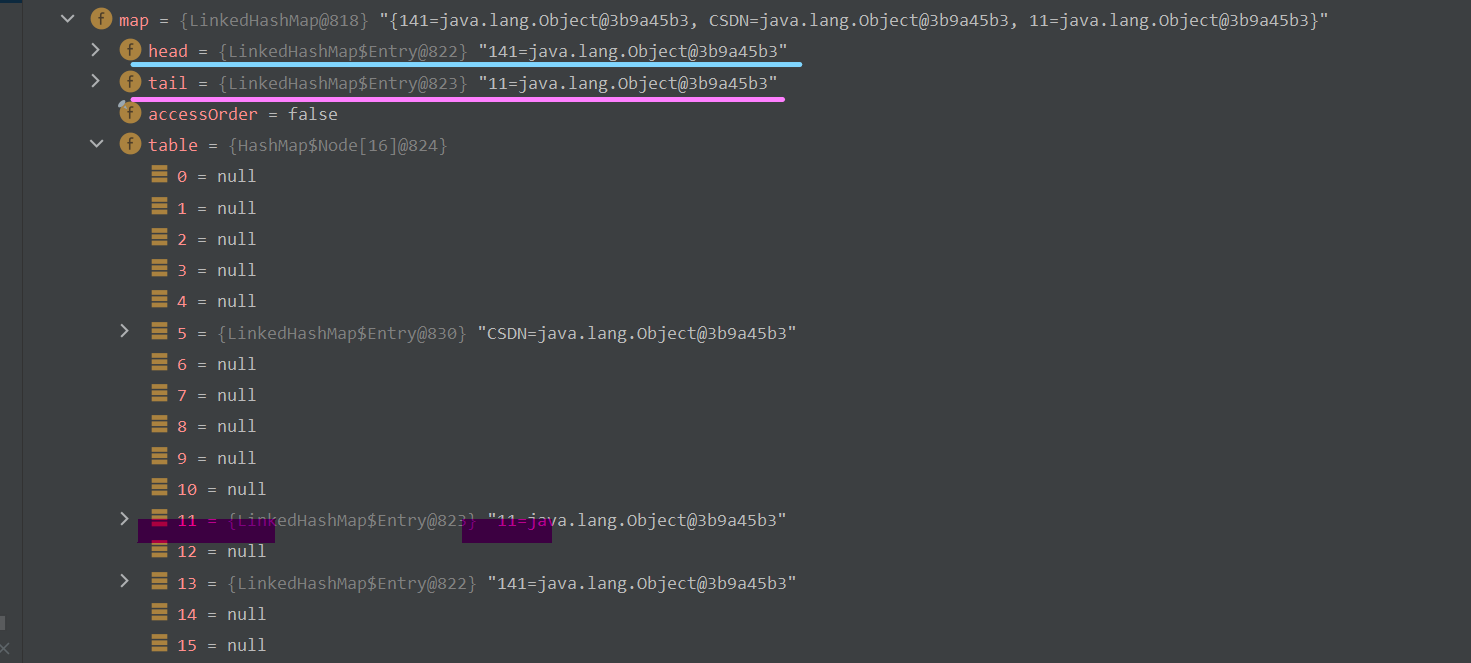
此时底层的"数组 + 链表"结构如下 :
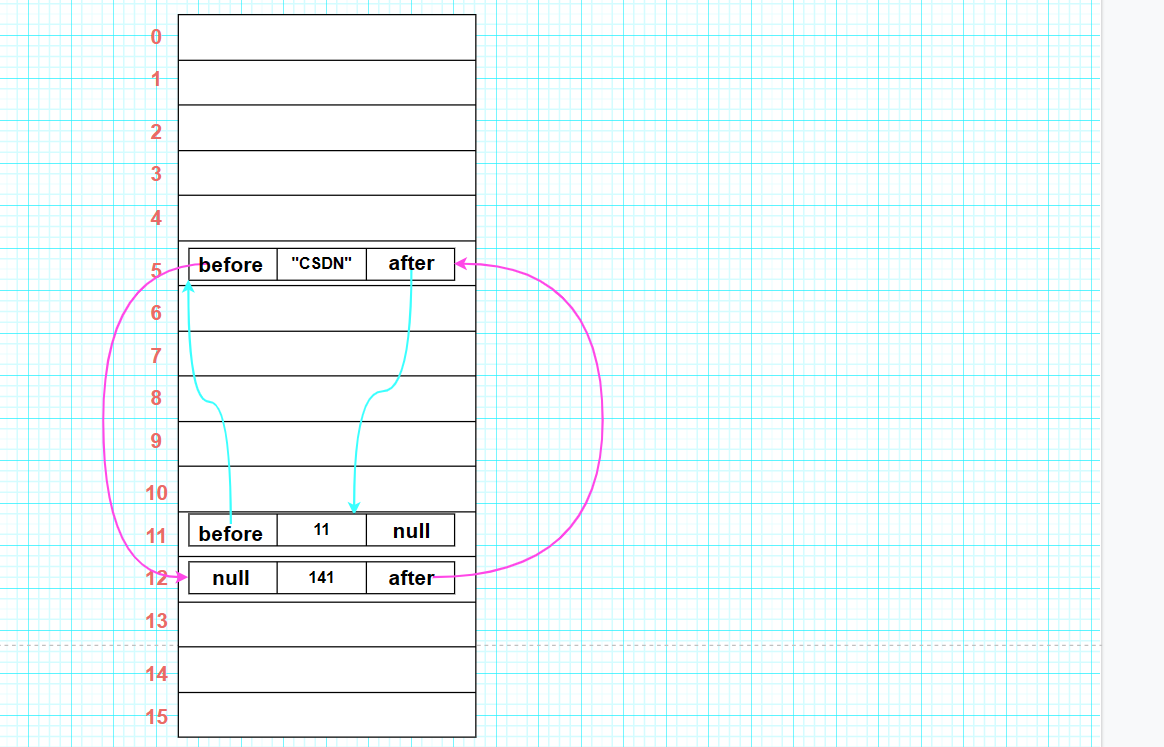
④向集合中添加第四、五、六个元素。
继续向下执行,向集合中添加"Cyan",new Apple("红富士"),和new Apple("红富士")这三个对象。注意,由于我们没有在Apple类重写equals方法,因此两个Apple对象会被判定为不同的元素,可以加入集合;但是由于我们在Apple类中重写了hashCode方法,这俩对象返回对哈希码值一样,因此它们会挂载到同一链表下。Debug界面图示如下 :
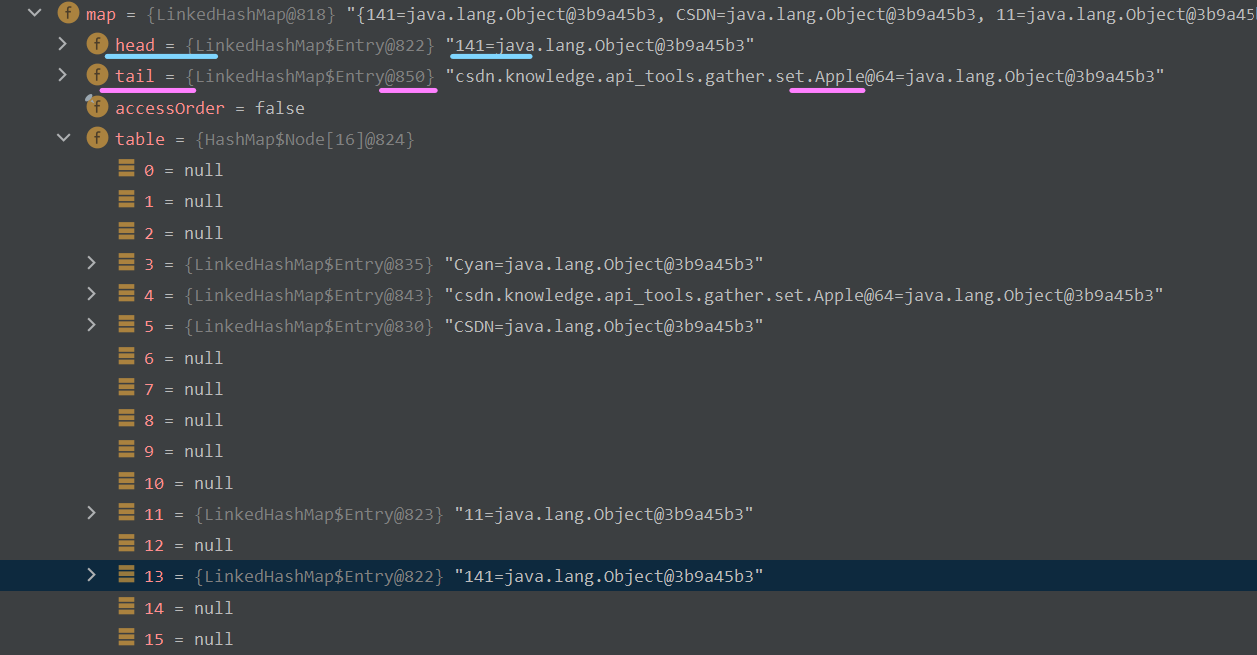
我们可以通过点击每个元素的after属性来直接查看它的下一个属性,如下GIF图所示 :

此时底层的"数组 + 链表"结构如下 :
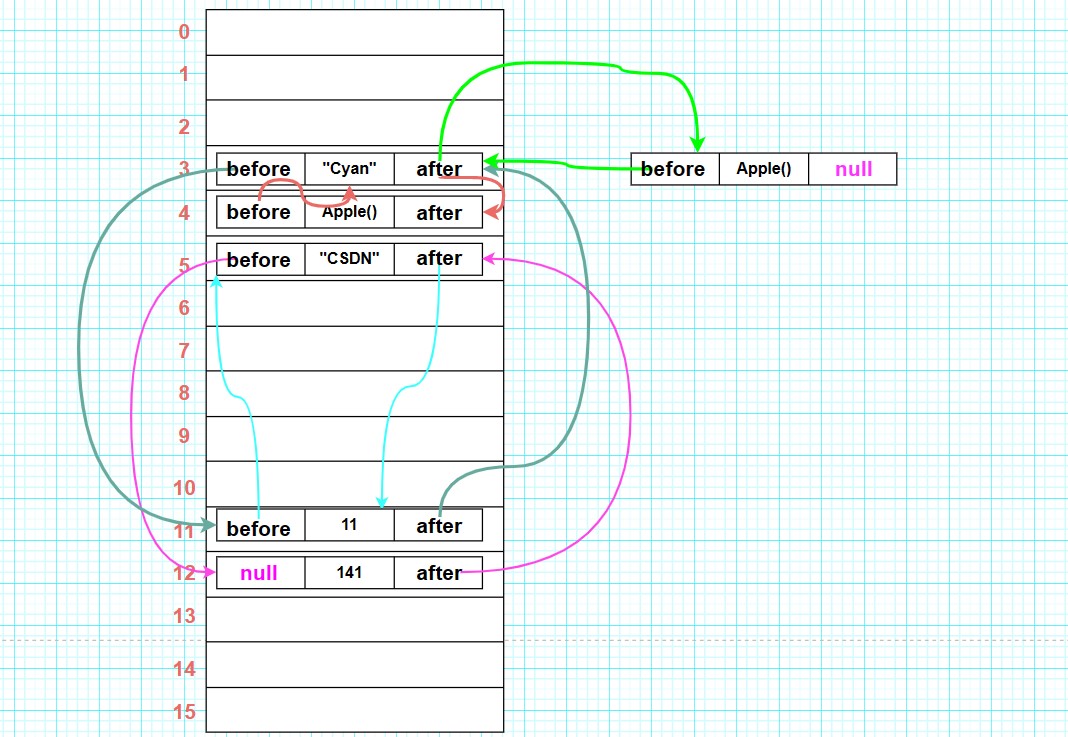
可能有点乱😂,不过看准每个结点的before和after,以及第一个结点和最后一个结点的null,还是可以很轻松找到顺序的。
这里还要再说一点——关于after和next的区别,其实很简单——
1°after是用于双向链表中专门指向下一个元素,没有下一个元素则为null。即不管某一个结点的下一个元素是在table数组中其他索引处的位置,还是挂载在该结点的后面,after都会指向它。
2°next则是和我们在HashSet中分析的一样,如果数组某一个索引处的元素形成了链表,next会指向链表中的下一个元素。
3°比如,此处的第一个Apple对象元素,它的after毫无疑问指向了第一个Apple对象元素;但是因为第二个Apple对象元素恰好挂载在了它的后面,即它们在table数组同一索引处的位置,所以第一个Apple对象元素的next属性也指向了第二个Apple对象。
4°也就是说,after是针对了整个双向链表,针对于所有元素,针对于全局;而next则是仅仅针对于同一索引位置处形成的单向链表,针对于table数组同一索引位置处的元素,针对于局部。
所以,我们可以通过Debug看到,在table数组的所有元素中,仅有第一个Apple对象元素的next属性有指向,且指向同它的after属性一样,指向了挂载在它后面的第二个Apple对象元素。如下图所示 :
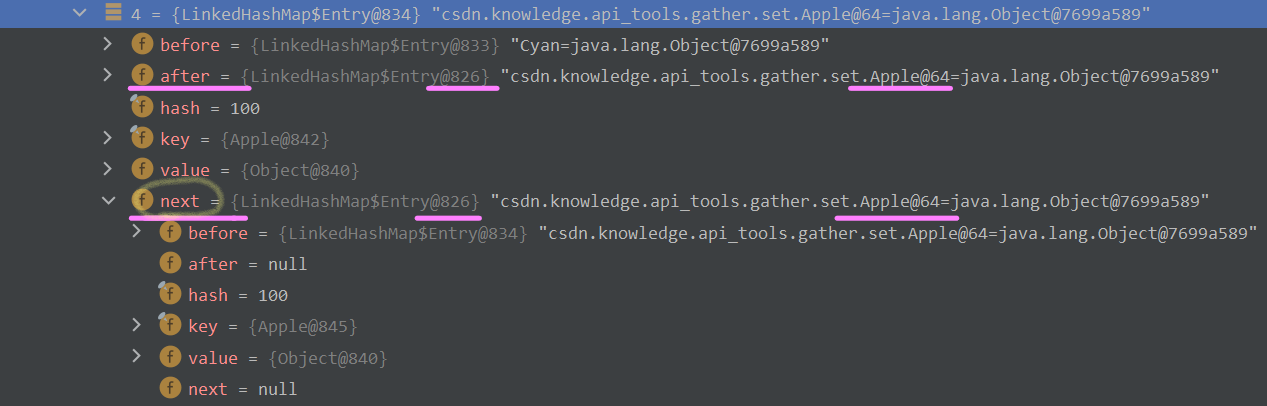
五、完结撒❀
🆗,以上就是我们LinkedHashSet源码分析的全部内容了😆。其实如果你认真看完了up之前对于HashSet的源码分析。看这篇LinkedHashSet的源码分析会轻松许多,毕竟有其父必有其子么(bushi)。当然,对于两者不同的地方,比如说是底层结构的差异,构造器的差异up也都有讲到。阅读源码的能力需要慢慢培养,希望大家都能下去亲自动动手,Debug一下。感谢阅读!