
17万字 JUC 看这一篇就够了(三) (精华)

今天我们继续来学习Java并发编程 Juc框架 ,把剩余部分学习完
- 17万字 JUC 看这一篇就够了(一) (精华)
- 17万字 JUC 看这一篇就够了(二) (精华)
文章目录
- 非公原理
- 加锁
- 解锁
- 公平原理
- 可重入
- 可打断
- 基本使用
- 实现原理
- 锁超时
- 基本使用
- 实现原理
- 哲学家就餐
- 条件变量
- 基本使用
- 实现原理
- await
- signal
- ReadWrite
- 读写锁
- 缓存应用
- 实现原理
- 成员属性
- 加锁原理
- 解锁原理
- Stamped
- CountDown
- 基本使用
- 实现原理
- CyclicBarrier
- 基本使用
- 实现原理
- 成员属性
- 成员方法
- Semaphore
- 基本使用
- 实现原理
- PROPAGATE
- Exchanger
- 并发包
- ConHashMap
- 并发集合
- 集合对比
- 并发死链
- 成员属性
- 变量
- 内部类
- 代码块
- 构造方法
- 成员方法
- 数据访存
- 添加方法
- 扩容方法
- 获取方法
- 删除方法
- JDK7原理
- CopyOnWrite
- 原理分析
- 弱一致性
- 安全失败
- Collections
- SkipListMap
- 底层结构
- 成员变量
- 成员方法
- 其他方法
- 添加方法
- 获取方法
- 删除方法
- NoBlocking
- 非阻塞队列
- 构造方法
- 入队方法
- 出队方法
- 成员方法
- NET
- DES
- 网络编程
- 通信协议
- Java模型
- I/O
- IO模型
- 五种模型
- 阻塞式IO
- 非阻塞式
- 信号驱动
- IO 复用
- 异步 IO
- 多路复用
- select
- 函数
- 流程
- poll
- epoll
- 函数
- 特点
- 应用
- 系统调用
- 内核态
- 80中断
- 零拷贝
- DMA
- BIO
- mmap
- sendfile
- BIO
- Inet
- UDP
- 基本介绍
- 实现UDP
- 通讯方式
- TCP
- 基本介绍
- Socket
- 实现TCP
- 开发流程
- 实现通信
- 伪异步
- 文件传输
- 字节流
- 数据流
- NIO
- 基本介绍
- 实现原理
- 缓冲区
- 基本介绍
- 基本属性
- 常用API
- 读写数据
- 粘包拆包
- 直接内存
- 基本介绍
- 通信原理
- 分配回收
- 共享内存
- 通道
- 基本介绍
- 常用API
- 文件读写
- 文件复制
- 分散聚集
- 选择器
- 基本介绍
- 常用API
- NIO实现
- 常用API
- 代码实现
- AIO
非公原理
加锁
NonfairSync 继承自 AQS
public void lock() {sync.lock();
}
-
没有竞争:ExclusiveOwnerThread 属于 Thread-0,state 设置为 1
// ReentrantLock.NonfairSync#lock final void lock() {// 用 cas 尝试(仅尝试一次)将 state 从 0 改为 1, 如果成功表示【获得了独占锁】if (compareAndSetState(0, 1))// 设置当前线程为独占线程setExclusiveOwnerThread(Thread.currentThread());elseacquire(1);//失败进入 } -
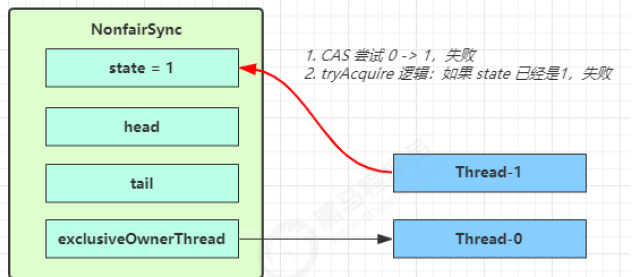
第一个竞争出现:Thread-1 执行,CAS 尝试将 state 由 0 改为 1,结果失败(第一次),进入 acquire 逻辑
// AbstractQueuedSynchronizer#acquire public final void acquire(int arg) {// tryAcquire 尝试获取锁失败时, 会调用 addWaiter 将当前线程封装成node入队,acquireQueued 阻塞当前线程,// acquireQueued 返回 true 表示挂起过程中线程被中断唤醒过,false 表示未被中断过if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))// 如果线程被中断了逻辑来到这,完成一次真正的打断效果selfInterrupt(); }
-
进入 tryAcquire 尝试获取锁逻辑,这时 state 已经是1,结果仍然失败(第二次),加锁成功有两种情况:
- 当前 AQS 处于无锁状态
- 加锁线程就是当前线程,说明发生了锁重入
// ReentrantLock.NonfairSync#tryAcquire protected final boolean tryAcquire(int acquires) {return nonfairTryAcquire(acquires); } // 抢占成功返回 true,抢占失败返回 false final boolean nonfairTryAcquire(int acquires) {final Thread current = Thread.currentThread();// state 值int c = getState();// 条件成立说明当前处于【无锁状态】if (c == 0) {//如果还没有获得锁,尝试用cas获得,这里体现非公平性: 不去检查 AQS 队列是否有阻塞线程直接获取锁 if (compareAndSetState(0, acquires)) {// 获取锁成功设置当前线程为独占锁线程。setExclusiveOwnerThread(current);return true;} } // 如果已经有线程获得了锁, 独占锁线程还是当前线程, 表示【发生了锁重入】else if (current == getExclusiveOwnerThread()) {// 更新锁重入的值int nextc = c + acquires;// 越界判断,当重入的深度很深时,会导致 nextc < 0,int值达到最大之后再 + 1 变负数if (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");// 更新 state 的值,这里不使用 cas 是因为当前线程正在持有锁,所以这里的操作相当于在一个管程内setState(nextc);return true;}// 获取失败return false; } -
接下来进入 addWaiter 逻辑,构造 Node 队列(不是阻塞队列),前置条件是当前线程获取锁失败,说明有线程占用了锁
- 图中黄色三角表示该 Node 的 waitStatus 状态,其中 0 为默认正常状态
- Node 的创建是懒惰的,其中第一个 Node 称为 Dummy(哑元)或哨兵,用来占位,并不关联线程
// AbstractQueuedSynchronizer#addWaiter,返回当前线程的 node 节点 private Node addWaiter(Node mode) {// 将当前线程关联到一个 Node 对象上, 模式为独占模式 Node node = new Node(Thread.currentThread(), mode);Node pred = tail;// 快速入队,如果 tail 不为 null,说明存在队列if (pred != null) {// 将当前节点的前驱节点指向 尾节点node.prev = pred;// 通过 cas 将 Node 对象加入 AQS 队列,成为尾节点,【尾插法】if (compareAndSetTail(pred, node)) {pred.next = node;// 双向链表return node;}}// 初始时队列为空,或者 CAS 失败进入这里enq(node);return node; }// AbstractQueuedSynchronizer#enq private Node enq(final Node node) {// 自旋入队,必须入队成功才结束循环for (;;) {Node t = tail;// 说明当前锁被占用,且当前线程可能是【第一个获取锁失败】的线程,【还没有建立队列】if (t == null) {// 设置一个【哑元节点】,头尾指针都指向该节点if (compareAndSetHead(new Node()))tail = head;} else {// 自旋到这,普通入队方式,首先赋值尾节点的前驱节点【尾插法】node.prev = t;// 【在设置完尾节点后,才更新的原始尾节点的后继节点,所以此时从前往后遍历会丢失尾节点】if (compareAndSetTail(t, node)) {//【此时 t.next = null,并且这里已经 CAS 结束,线程并不是安全的】t.next = node;return t; // 返回当前 node 的前驱节点}}} }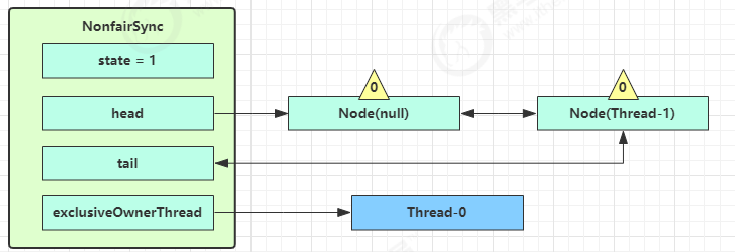
-
线程节点加入队列成功,进入 AbstractQueuedSynchronizer#acquireQueued 逻辑阻塞线程
-
acquireQueued 会在一个自旋中不断尝试获得锁,失败后进入 park 阻塞
-
如果当前线程是在 head 节点后,会再次 tryAcquire 尝试获取锁,state 仍为 1 则失败(第三次)
final boolean acquireQueued(final Node node, int arg) {// true 表示当前线程抢占锁失败,false 表示成功boolean failed = true;try {// 中断标记,表示当前线程是否被中断boolean interrupted = false;for (;;) {// 获得当前线程节点的前驱节点final Node p = node.predecessor();// 前驱节点是 head, FIFO 队列的特性表示轮到当前线程可以去获取锁if (p == head && tryAcquire(arg)) {// 获取成功, 设置当前线程自己的 node 为 headsetHead(node);p.next = null; // help GC// 表示抢占锁成功failed = false;// 返回当前线程是否被中断return interrupted;}// 判断是否应当 park,返回 false 后需要新一轮的循环,返回 true 进入条件二阻塞线程if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())// 条件二返回结果是当前线程是否被打断,没有被打断返回 false 不进入这里的逻辑// 【就算被打断了,也会继续循环,并不会返回】interrupted = true;}} finally {// 【可打断模式下才会进入该逻辑】if (failed)cancelAcquire(node);} }- 进入 shouldParkAfterFailedAcquire 逻辑,将前驱 node 的 waitStatus 改为 -1,返回 false;waitStatus 为 -1 的节点用来唤醒下一个节点
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {int ws = pred.waitStatus;// 表示前置节点是个可以唤醒当前节点的节点,返回 trueif (ws == Node.SIGNAL)return true;// 前置节点的状态处于取消状态,需要【删除前面所有取消的节点】, 返回到外层循环重试if (ws > 0) {do {node.prev = pred = pred.prev;} while (pred.waitStatus > 0);// 获取到非取消的节点,连接上当前节点pred.next = node;// 默认情况下 node 的 waitStatus 是 0,进入这里的逻辑} else {// 【设置上一个节点状态为 Node.SIGNAL】,返回外层循环重试compareAndSetWaitStatus(pred, ws, Node.SIGNAL);}// 返回不应该 park,再次尝试一次return false; }- shouldParkAfterFailedAcquire 执行完毕回到 acquireQueued ,再次 tryAcquire 尝试获取锁,这时 state 仍为 1 获取失败(第四次)
- 当再次进入 shouldParkAfterFailedAcquire 时,这时其前驱 node 的 waitStatus 已经是 -1 了,返回 true
- 进入 parkAndCheckInterrupt, Thread-1 park(灰色表示)
private final boolean parkAndCheckInterrupt() {// 阻塞当前线程,如果打断标记已经是 true, 则 park 会失效LockSupport.park(this);// 判断当前线程是否被打断,清除打断标记return Thread.interrupted(); } -
-
再有多个线程经历竞争失败后:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tQ7iZKgb-1679358011068)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ReentrantLock-非公平锁3.png)]
解锁
ReentrantLock#unlock:释放锁
public void unlock() {sync.release(1);
}
Thread-0 释放锁,进入 release 流程
-
进入 tryRelease,设置 exclusiveOwnerThread 为 null,state = 0
-
当前队列不为 null,并且 head 的 waitStatus = -1,进入 unparkSuccessor
// AbstractQueuedSynchronizer#release public final boolean release(int arg) {// 尝试释放锁,tryRelease 返回 true 表示当前线程已经【完全释放锁,重入的释放了】if (tryRelease(arg)) {// 队列头节点Node h = head;// 头节点什么时候是空?没有发生锁竞争,没有竞争线程创建哑元节点// 条件成立说明阻塞队列有等待线程,需要唤醒 head 节点后面的线程if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;} return false; }// ReentrantLock.Sync#tryRelease protected final boolean tryRelease(int releases) {// 减去释放的值,可能重入int c = getState() - releases;// 如果当前线程不是持有锁的线程直接报错if (Thread.currentThread() != getExclusiveOwnerThread())throw new IllegalMonitorStateException();// 是否已经完全释放锁boolean free = false;// 支持锁重入, 只有 state 减为 0, 才完全释放锁成功if (c == 0) {free = true;setExclusiveOwnerThread(null);}// 当前线程就是持有锁线程,所以可以直接更新锁,不需要使用 CASsetState(c);return free; } -
进入 AbstractQueuedSynchronizer#unparkSuccessor 方法,唤醒当前节点的后继节点
- 找到队列中距离 head 最近的一个没取消的 Node,unpark 恢复其运行,本例中即为 Thread-1
- 回到 Thread-1 的 acquireQueued 流程
private void unparkSuccessor(Node node) {// 当前节点的状态int ws = node.waitStatus; if (ws < 0) // 【尝试重置状态为 0】,因为当前节点要完成对后续节点的唤醒任务了,不需要 -1 了compareAndSetWaitStatus(node, ws, 0); // 找到需要 unpark 的节点,当前节点的下一个 Node s = node.next; // 已取消的节点不能唤醒,需要找到距离头节点最近的非取消的节点if (s == null || s.waitStatus > 0) {s = null;// AQS 队列【从后至前】找需要 unpark 的节点,直到 t == 当前的 node 为止,找不到就不唤醒了for (Node t = tail; t != null && t != node; t = t.prev)// 说明当前线程状态需要被唤醒if (t.waitStatus <= 0)// 置换引用s = t;}// 【找到合适的可以被唤醒的 node,则唤醒线程】if (s != null)LockSupport.unpark(s.thread); }从后向前的唤醒的原因:enq 方法中,节点是尾插法,首先赋值的是尾节点的前驱节点,此时前驱节点的 next 并没有指向尾节点,从前遍历会丢失尾节点
-
唤醒的线程会从 park 位置开始执行,如果加锁成功(没有竞争),会设置
- exclusiveOwnerThread 为 Thread-1,state = 1
- head 指向刚刚 Thread-1 所在的 Node,该 Node 会清空 Thread
- 原本的 head 因为从链表断开,而可被垃圾回收(图中有错误,原来的头节点的 waitStatus 被改为 0 了)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LXCp0lox-1679358011068)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ReentrantLock-非公平锁4.png)]
-
如果这时有其它线程来竞争**(非公平)**,例如这时有 Thread-4 来了并抢占了锁
- Thread-4 被设置为 exclusiveOwnerThread,state = 1
- Thread-1 再次进入 acquireQueued 流程,获取锁失败,重新进入 park 阻塞
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0eQ8vo9D-1679358011069)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ReentrantLock-非公平锁5.png)]
公平原理
与非公平锁主要区别在于 tryAcquire 方法:先检查 AQS 队列中是否有前驱节点,没有才去 CAS 竞争
static final class FairSync extends Sync {private static final long serialVersionUID = -3000897897090466540L;final void lock() {acquire(1);}protected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {// 先检查 AQS 队列中是否有前驱节点, 没有(false)才去竞争if (!hasQueuedPredecessors() &&compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}// 锁重入return false;}
}
public final boolean hasQueuedPredecessors() { Node t = tail;Node h = head;Node s; // 头尾指向一个节点,链表为空,返回falsereturn h != t &&// 头尾之间有节点,判断头节点的下一个是不是空// 不是空进入最后的判断,第二个节点的线程是否是本线程,不是返回 true,表示当前节点有前驱节点((s = h.next) == null || s.thread != Thread.currentThread());
}
可重入
可重入是指同一个线程如果首次获得了这把锁,那么它是这把锁的拥有者,因此有权利再次获取这把锁,如果不可重入锁,那么第二次获得锁时,自己也会被锁挡住,直接造成死锁
源码解析参考:nonfairTryAcquire(int acquires)) 和 tryRelease(int releases)
static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {method1();
}
public static void method1() {lock.lock();try {System.out.println(Thread.currentThread().getName() + " execute method1");method2();} finally {lock.unlock();}
}
public static void method2() {lock.lock();try {System.out.println(Thread.currentThread().getName() + " execute method2");} finally {lock.unlock();}
}
在 Lock 方法加两把锁会是什么情况呢?
- 加锁两次解锁两次:正常执行
- 加锁两次解锁一次:程序直接卡死,线程不能出来,也就说明申请几把锁,最后需要解除几把锁
- 加锁一次解锁两次:运行程序会直接报错
public void getLock() {lock.lock();lock.lock();try {System.out.println(Thread.currentThread().getName() + "\t get Lock");} finally {lock.unlock();//lock.unlock();}
}
可打断
基本使用
public void lockInterruptibly():获得可打断的锁
- 如果没有竞争此方法就会获取 lock 对象锁
- 如果有竞争就进入阻塞队列,可以被其他线程用 interrupt 打断
注意:如果是不可中断模式,那么即使使用了 interrupt 也不会让等待状态中的线程中断
public static void main(String[] args) throws InterruptedException { ReentrantLock lock = new ReentrantLock(); Thread t1 = new Thread(() -> { try { System.out.println("尝试获取锁"); lock.lockInterruptibly(); } catch (InterruptedException e) { System.out.println("没有获取到锁,被打断,直接返回"); return; } try { System.out.println("获取到锁"); } finally { lock.unlock(); } }, "t1"); lock.lock(); t1.start(); Thread.sleep(2000); System.out.println("主线程进行打断锁"); t1.interrupt();
}
实现原理
-
不可打断模式:即使它被打断,仍会驻留在 AQS 阻塞队列中,一直要等到获得锁后才能得知自己被打断了
public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))//阻塞等待 // 如果acquireQueued返回true,打断状态 interrupted = true selfInterrupt(); } static void selfInterrupt() {// 知道自己被打断了,需要重新产生一次中断完成中断效果Thread.currentThread().interrupt(); }final boolean acquireQueued(final Node node, int arg) { try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; // 还是需要获得锁后, 才能返回打断状态return interrupted; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()){// 条件二中判断当前线程是否被打断,被打断返回true,设置中断标记为 true,【获取锁后返回】interrupted = true; } } } finally {if (failed)cancelAcquire(node);} }private final boolean parkAndCheckInterrupt() { // 阻塞当前线程,如果打断标记已经是 true, 则 park 会失效LockSupport.park(this); // 判断当前线程是否被打断,清除打断标记,被打断返回truereturn Thread.interrupted();} -
可打断模式:AbstractQueuedSynchronizer#acquireInterruptibly,被打断后会直接抛出异常
public void lockInterruptibly() throws InterruptedException { sync.acquireInterruptibly(1); } public final void acquireInterruptibly(int arg) {// 被其他线程打断了直接返回 falseif (Thread.interrupted())throw new InterruptedException();if (!tryAcquire(arg))// 没获取到锁,进入这里doAcquireInterruptibly(arg); }private void doAcquireInterruptibly(int arg) throws InterruptedException {// 返回封装当前线程的节点final Node node = addWaiter(Node.EXCLUSIVE);boolean failed = true;try {for (;;) {//...if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())// 【在 park 过程中如果被 interrupt 会抛出异常】, 而不会再次进入循环获取锁后才完成打断效果throw new InterruptedException();} } finally {// 抛出异常前会进入这里if (failed)// 取消当前线程的节点cancelAcquire(node);} }// 取消节点出队的逻辑 private void cancelAcquire(Node node) {// 判空if (node == null)return;// 把当前节点封装的 Thread 置为空node.thread = null;// 获取当前取消的 node 的前驱节点Node pred = node.prev;// 前驱节点也被取消了,循环找到前面最近的没被取消的节点while (pred.waitStatus > 0)node.prev = pred = pred.prev;// 获取前驱节点的后继节点,可能是当前 node,也可能是 waitStatus > 0 的节点Node predNext = pred.next;// 把当前节点的状态设置为 【取消状态 1】node.waitStatus = Node.CANCELLED;// 条件成立说明当前节点是尾节点,把当前节点的前驱节点设置为尾节点if (node == tail && compareAndSetTail(node, pred)) {// 把前驱节点的后继节点置空,这里直接把所有的取消节点出队compareAndSetNext(pred, predNext, null);} else {// 说明当前节点不是 tail 节点int ws;// 条件一成立说明当前节点不是 head.next 节点if (pred != head &&// 判断前驱节点的状态是不是 -1,不成立说明前驱状态可能是 0 或者刚被其他线程取消排队了((ws = pred.waitStatus) == Node.SIGNAL ||// 如果状态不是 -1,设置前驱节点的状态为 -1(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&// 前驱节点的线程不为nullpred.thread != null) {Node next = node.next;// 当前节点的后继节点是正常节点if (next != null && next.waitStatus <= 0)// 把 前驱节点的后继节点 设置为 当前节点的后继节点,【从队列中删除了当前节点】compareAndSetNext(pred, predNext, next);} else {// 当前节点是 head.next 节点,唤醒当前节点的后继节点unparkSuccessor(node);}node.next = node; // help GC} }
锁超时
基本使用
public boolean tryLock():尝试获取锁,获取到返回 true,获取不到直接放弃,不进入阻塞队列
public boolean tryLock(long timeout, TimeUnit unit):在给定时间内获取锁,获取不到就退出
注意:tryLock 期间也可以被打断
public static void main(String[] args) {ReentrantLock lock = new ReentrantLock();Thread t1 = new Thread(() -> {try {if (!lock.tryLock(2, TimeUnit.SECONDS)) {System.out.println("获取不到锁");return;}} catch (InterruptedException e) {System.out.println("被打断,获取不到锁");return;}try {log.debug("获取到锁");} finally {lock.unlock();}}, "t1");lock.lock();System.out.println("主线程获取到锁");t1.start();Thread.sleep(1000);try {System.out.println("主线程释放了锁");} finally {lock.unlock();}
}
实现原理
-
成员变量:指定超时限制的阈值,小于该值的线程不会被挂起
static final long spinForTimeoutThreshold = 1000L;超时时间设置的小于该值,就会被禁止挂起,因为阻塞在唤醒的成本太高,不如选择自旋空转
-
tryLock()
public boolean tryLock() { // 只尝试一次return sync.nonfairTryAcquire(1); } -
tryLock(long timeout, TimeUnit unit)
public final boolean tryAcquireNanos(int arg, long nanosTimeout) {if (Thread.interrupted()) throw new InterruptedException(); // tryAcquire 尝试一次return tryAcquire(arg) || doAcquireNanos(arg, nanosTimeout); } protected final boolean tryAcquire(int acquires) { return nonfairTryAcquire(acquires); }private boolean doAcquireNanos(int arg, long nanosTimeout) { if (nanosTimeout <= 0L)return false;// 获取最后期限的时间戳final long deadline = System.nanoTime() + nanosTimeout;//...try {for (;;) {//...// 计算还需等待的时间nanosTimeout = deadline - System.nanoTime();if (nanosTimeout <= 0L) //时间已到 return false;if (shouldParkAfterFailedAcquire(p, node) &&// 如果 nanosTimeout 大于该值,才有阻塞的意义,否则直接自旋会好点nanosTimeout > spinForTimeoutThreshold)LockSupport.parkNanos(this, nanosTimeout);// 【被打断会报异常】if (Thread.interrupted())throw new InterruptedException();} } }
哲学家就餐
public static void main(String[] args) {Chopstick c1 = new Chopstick("1");//...Chopstick c5 = new Chopstick("5");new Philosopher("苏格拉底", c1, c2).start();new Philosopher("柏拉图", c2, c3).start();new Philosopher("亚里士多德", c3, c4).start();new Philosopher("赫拉克利特", c4, c5).start(); new Philosopher("阿基米德", c5, c1).start();
}
class Philosopher extends Thread {Chopstick left;Chopstick right;public void run() {while (true) {// 尝试获得左手筷子if (left.tryLock()) {try {// 尝试获得右手筷子if (right.tryLock()) {try {System.out.println("eating...");Thread.sleep(1000);} finally {right.unlock();}}} finally {left.unlock();}}}}
}
class Chopstick extends ReentrantLock {String name;public Chopstick(String name) {this.name = name;}@Overridepublic String toString() {return "筷子{" + name + '}';}
}
条件变量
基本使用
synchronized 的条件变量,是当条件不满足时进入 WaitSet 等待;ReentrantLock 的条件变量比 synchronized 强大之处在于支持多个条件变量
ReentrantLock 类获取 Condition 对象:public Condition newCondition()
Condition 类 API:
void await():当前线程从运行状态进入等待状态,释放锁void signal():唤醒一个等待在 Condition 上的线程,但是必须获得与该 Condition 相关的锁
使用流程:
-
await / signal 前需要获得锁
-
await 执行后,会释放锁进入 ConditionObject 等待
-
await 的线程被唤醒去重新竞争 lock 锁
-
线程在条件队列被打断会抛出中断异常
-
竞争 lock 锁成功后,从 await 后继续执行
public static void main(String[] args) throws InterruptedException { ReentrantLock lock = new ReentrantLock();//创建一个新的条件变量Condition condition1 = lock.newCondition();Condition condition2 = lock.newCondition();new Thread(() -> {try {lock.lock();System.out.println("进入等待");//进入休息室等待condition1.await();System.out.println("被唤醒了");} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();} }).start();Thread.sleep(1000);//叫醒new Thread(() -> {try { lock.lock();//唤醒condition2.signal();} finally {lock.unlock();}}).start();
}
实现原理
await
总体流程是将 await 线程包装成 node 节点放入 ConditionObject 的条件队列,如果被唤醒就将 node 转移到 AQS 的执行阻塞队列,等待获取锁,每个 Condition 对象都包含一个等待队列
-
开始 Thread-0 持有锁,调用 await,线程进入 ConditionObject 等待,直到被唤醒或打断,调用 await 方法的线程都是持锁状态的,所以说逻辑里不存在并发
public final void await() throws InterruptedException {// 判断当前线程是否是中断状态,是就直接给个中断异常if (Thread.interrupted())throw new InterruptedException();// 将调用 await 的线程包装成 Node,添加到条件队列并返回Node node = addConditionWaiter();// 完全释放节点持有的锁,因为其他线程唤醒当前线程的前提是【持有锁】int savedState = fullyRelease(node);// 设置打断模式为没有被打断,状态码为 0int interruptMode = 0;// 如果该节点还没有转移至 AQS 阻塞队列, park 阻塞,等待进入阻塞队列while (!isOnSyncQueue(node)) {LockSupport.park(this);// 如果被打断,退出等待队列,对应的 node 【也会被迁移到阻塞队列】尾部,状态设置为 0if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)break;}// 逻辑到这说明当前线程退出等待队列,进入【阻塞队列】// 尝试枪锁,释放了多少锁就【重新获取多少锁】,获取锁成功判断打断模式if (acquireQueued(node, savedState) && interruptMode != THROW_IE)interruptMode = REINTERRUPT;// node 在条件队列时 如果被外部线程中断唤醒,会加入到阻塞队列,但是并未设 nextWaiter = nullif (node.nextWaiter != null)// 清理条件队列内所有已取消的 NodeunlinkCancelledWaiters();// 条件成立说明挂起期间发生过中断if (interruptMode != 0)// 应用打断模式reportInterruptAfterWait(interruptMode); }// 打断模式 - 在退出等待时重新设置打断状态 private static final int REINTERRUPT = 1; // 打断模式 - 在退出等待时抛出异常 private static final int THROW_IE = -1;[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0V5nt2PN-1679358011069)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ReentrantLock-条件变量1.png)]
-
创建新的 Node 状态为 -2(Node.CONDITION),关联 Thread-0,加入等待队列尾部
private Node addConditionWaiter() {// 获取当前条件队列的尾节点的引用,保存到局部变量 t 中Node t = lastWaiter;// 当前队列中不是空,并且节点的状态不是 CONDITION(-2),说明当前节点发生了中断if (t != null && t.waitStatus != Node.CONDITION) {// 清理条件队列内所有已取消的 NodeunlinkCancelledWaiters();// 清理完成重新获取 尾节点 的引用t = lastWaiter;}// 创建一个关联当前线程的新 node, 设置状态为 CONDITION(-2),添加至队列尾部Node node = new Node(Thread.currentThread(), Node.CONDITION);if (t == null)firstWaiter = node; // 空队列直接放在队首【不用CAS因为执行线程是持锁线程,并发安全】elset.nextWaiter = node; // 非空队列队尾追加lastWaiter = node; // 更新队尾的引用return node; }// 清理条件队列内所有已取消(不是CONDITION)的 node,【链表删除的逻辑】 private void unlinkCancelledWaiters() {// 从头节点开始遍历【FIFO】Node t = firstWaiter;// 指向正常的 CONDITION 节点Node trail = null;// 等待队列不空while (t != null) {// 获取当前节点的后继节点Node next = t.nextWaiter;// 判断 t 节点是不是 CONDITION 节点,条件队列内不是 CONDITION 就不是正常的if (t.waitStatus != Node.CONDITION) { // 不是正常节点,需要 t 与下一个节点断开t.nextWaiter = null;// 条件成立说明遍历到的节点还未碰到过正常节点if (trail == null)// 更新 firstWaiter 指针为下个节点firstWaiter = next;else// 让上一个正常节点指向 当前取消节点的 下一个节点,【删除非正常的节点】trail.nextWaiter = next;// t 是尾节点了,更新 lastWaiter 指向最后一个正常节点if (next == null)lastWaiter = trail;} else {// trail 指向的是正常节点 trail = t;}// 把 t.next 赋值给 t,循环遍历t = next; } } -
接下来 Thread-0 进入 AQS 的 fullyRelease 流程,释放同步器上的锁
// 线程可能重入,需要将 state 全部释放 final int fullyRelease(Node node) {// 完全释放锁是否成功,false 代表成功boolean failed = true;try {// 获取当前线程所持有的 state 值总数int savedState = getState();// release -> tryRelease 解锁重入锁if (release(savedState)) {// 释放成功failed = false;// 返回解锁的深度return savedState;} else {// 解锁失败抛出异常throw new IllegalMonitorStateException();}} finally {// 没有释放成功,将当前 node 设置为取消状态if (failed)node.waitStatus = Node.CANCELLED;} } -
fullyRelease 中会 unpark AQS 队列中的下一个节点竞争锁,假设 Thread-1 竞争成功
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4pT5CYeh-1679358011069)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ReentrantLock-条件变量2.png)]
-
Thread-0 进入 isOnSyncQueue 逻辑判断节点是否移动到阻塞队列,没有就 park 阻塞 Thread-0
final boolean isOnSyncQueue(Node node) {// node 的状态是 CONDITION,signal 方法是先修改状态再迁移,所以前驱节点为空证明还【没有完成迁移】if (node.waitStatus == Node.CONDITION || node.prev == null)return false;// 说明当前节点已经成功入队到阻塞队列,且当前节点后面已经有其它 node,因为条件队列的 next 指针为 nullif (node.next != null)return true;// 说明【可能在阻塞队列,但是是尾节点】// 从阻塞队列的尾节点开始向前【遍历查找 node】,如果查找到返回 true,查找不到返回 falsereturn findNodeFromTail(node); } -
await 线程 park 后如果被 unpark 或者被打断,都会进入 checkInterruptWhileWaiting 判断线程是否被打断:在条件队列被打断的线程需要抛出异常
private int checkInterruptWhileWaiting(Node node) {// Thread.interrupted() 返回当前线程中断标记位,并且重置当前标记位 为 false// 如果被中断了,根据是否在条件队列被中断的,设置中断状态码return Thread.interrupted() ?(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) : 0; }// 这个方法只有在线程是被打断唤醒时才会调用 final boolean transferAfterCancelledWait(Node node) {// 条件成立说明当前node一定是在条件队列内,因为 signal 迁移节点到阻塞队列时,会将节点的状态修改为 0if (compareAndSetWaitStatus(node, Node.CONDITION, 0)) {// 把【中断唤醒的 node 加入到阻塞队列中】enq(node);// 表示是在条件队列内被中断了,设置为 THROW_IE 为 -1return true;}//执行到这里的情况://1.当前node已经被外部线程调用 signal 方法将其迁移到 阻塞队列 内了//2.当前node正在被外部线程调用 signal 方法将其迁移至 阻塞队列 进行中状态// 如果当前线程还没到阻塞队列,一直释放 CPUwhile (!isOnSyncQueue(node))Thread.yield();// 表示当前节点被中断唤醒时不在条件队列了,设置为 REINTERRUPT 为 1return false; } -
最后开始处理中断状态:
private void reportInterruptAfterWait(int interruptMode) throws InterruptedException {// 条件成立说明【在条件队列内发生过中断,此时 await 方法抛出中断异常】if (interruptMode == THROW_IE)throw new InterruptedException();// 条件成立说明【在条件队列外发生的中断,此时设置当前线程的中断标记位为 true】else if (interruptMode == REINTERRUPT)// 进行一次自己打断,产生中断的效果selfInterrupt(); }
signal
-
假设 Thread-1 要来唤醒 Thread-0,进入 ConditionObject 的 doSignal 流程,取得等待队列中第一个 Node,即 Thread-0 所在 Node,必须持有锁才能唤醒, 因此 doSignal 内线程安全
public final void signal() {// 判断调用 signal 方法的线程是否是独占锁持有线程if (!isHeldExclusively())throw new IllegalMonitorStateException();// 获取条件队列中第一个 NodeNode first = firstWaiter;// 不为空就将第该节点【迁移到阻塞队列】if (first != null)doSignal(first); }// 唤醒 - 【将没取消的第一个节点转移至 AQS 队列尾部】 private void doSignal(Node first) {do {// 成立说明当前节点的下一个节点是 null,当前节点是尾节点了,队列中只有当前一个节点了if ((firstWaiter = first.nextWaiter) == null)lastWaiter = null;first.nextWaiter = null;// 将等待队列中的 Node 转移至 AQS 队列,不成功且还有节点则继续循环} while (!transferForSignal(first) && (first = firstWaiter) != null); }// signalAll() 会调用这个函数,唤醒所有的节点 private void doSignalAll(Node first) {lastWaiter = firstWaiter = null;do {Node next = first.nextWaiter;first.nextWaiter = null;transferForSignal(first);first = next;// 唤醒所有的节点,都放到阻塞队列中} while (first != null); } -
执行 transferForSignal,先将节点的 waitStatus 改为 0,然后加入 AQS 阻塞队列尾部,将 Thread-3 的 waitStatus 改为 -1
// 如果节点状态是取消, 返回 false 表示转移失败, 否则转移成功 final boolean transferForSignal(Node node) {// CAS 修改当前节点的状态,修改为 0,因为当前节点马上要迁移到阻塞队列了// 如果状态已经不是 CONDITION, 说明线程被取消(await 释放全部锁失败)或者被中断(可打断 cancelAcquire)if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))// 返回函数调用处继续寻找下一个节点return false;// 【先改状态,再进行迁移】// 将当前 node 入阻塞队列,p 是当前节点在阻塞队列的【前驱节点】Node p = enq(node);int ws = p.waitStatus;// 如果前驱节点被取消或者不能设置状态为 Node.SIGNAL,就 unpark 取消当前节点线程的阻塞状态, // 让 thread-0 线程竞争锁,重新同步状态if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))LockSupport.unpark(node.thread);return true; }[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tTefvvSx-1679358011070)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ReentrantLock-条件变量3.png)]
-
Thread-1 释放锁,进入 unlock 流程
ReadWrite
读写锁
独占锁:指该锁一次只能被一个线程所持有,对 ReentrantLock 和 Synchronized 而言都是独占锁
共享锁:指该锁可以被多个线程锁持有
ReentrantReadWriteLock 其读锁是共享锁,写锁是独占锁
作用:多个线程同时读一个资源类没有任何问题,为了满足并发量,读取共享资源应该同时进行,但是如果一个线程想去写共享资源,就不应该再有其它线程可以对该资源进行读或写
使用规则:
-
加锁解锁格式:
r.lock(); try {// 临界区 } finally {r.unlock(); } -
读-读能共存、读-写不能共存、写-写不能共存
-
读锁不支持条件变量
-
重入时升级不支持:持有读锁的情况下去获取写锁会导致获取写锁永久等待,需要先释放读,再去获得写
-
重入时降级支持:持有写锁的情况下去获取读锁,造成只有当前线程会持有读锁,因为写锁会互斥其他的锁
w.lock(); try {r.lock();// 降级为读锁, 释放写锁, 这样能够让其它线程读取缓存try {// ...} finally{w.unlock();// 要在写锁释放之前获取读锁} } finally{r.unlock(); }
构造方法:
public ReentrantReadWriteLock():默认构造方法,非公平锁public ReentrantReadWriteLock(boolean fair):true 为公平锁
常用API:
public ReentrantReadWriteLock.ReadLock readLock():返回读锁public ReentrantReadWriteLock.WriteLock writeLock():返回写锁public void lock():加锁public void unlock():解锁public boolean tryLock():尝试获取锁
读读并发:
public static void main(String[] args) {ReentrantReadWriteLock rw = new ReentrantReadWriteLock();ReentrantReadWriteLock.ReadLock r = rw.readLock();ReentrantReadWriteLock.WriteLock w = rw.writeLock();new Thread(() -> {r.lock();try {Thread.sleep(2000);System.out.println("Thread 1 running " + new Date());} finally {r.unlock();}},"t1").start();new Thread(() -> {r.lock();try {Thread.sleep(2000);System.out.println("Thread 2 running " + new Date());} finally {r.unlock();}},"t2").start();
}
缓存应用
缓存更新时,是先清缓存还是先更新数据库
-
先清缓存:可能造成刚清理缓存还没有更新数据库,线程直接查询了数据库更新过期数据到缓存
-
先更新据库:可能造成刚更新数据库,还没清空缓存就有线程从缓存拿到了旧数据
-
补充情况:查询线程 A 查询数据时恰好缓存数据由于时间到期失效,或是第一次查询
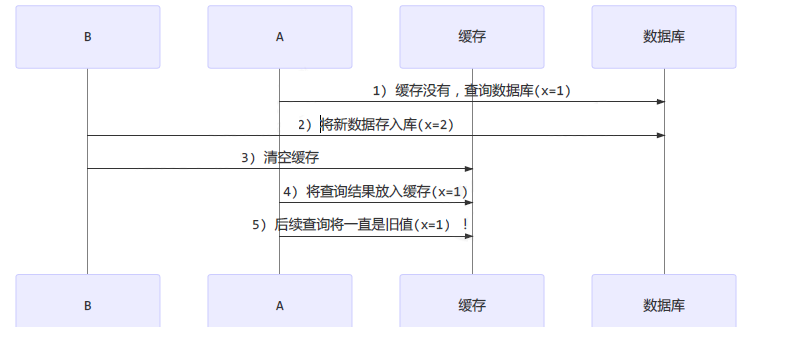
可以使用读写锁进行操作
实现原理
成员属性
读写锁用的是同一个 Sycn 同步器,因此等待队列、state 等也是同一个,原理与 ReentrantLock 加锁相比没有特殊之处,不同是写锁状态占了 state 的低 16 位,而读锁使用的是 state 的高 16 位
-
读写锁:
private final ReentrantReadWriteLock.ReadLock readerLock; private final ReentrantReadWriteLock.WriteLock writerLock; -
构造方法:默认是非公平锁,可以指定参数创建公平锁
public ReentrantReadWriteLock(boolean fair) {// true 为公平锁sync = fair ? new FairSync() : new NonfairSync();// 这两个 lock 共享同一个 sync 实例,都是由 ReentrantReadWriteLock 的 sync 提供同步实现readerLock = new ReadLock(this);writerLock = new WriteLock(this); }
Sync 类的属性:
-
统计变量:
// 用来移位 static final int SHARED_SHIFT = 16; // 高16位的1 static final int SHARED_UNIT = (1 << SHARED_SHIFT); // 65535,16个1,代表写锁的最大重入次数 static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1; // 低16位掩码:0b 1111 1111 1111 1111,用来获取写锁重入的次数 static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1; -
获取读写锁的次数:
// 获取读写锁的读锁分配的总次数 static int sharedCount(int c) { return c >>> SHARED_SHIFT; } // 写锁(独占)锁的重入次数 static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; } -
内部类:
// 记录读锁线程自己的持有读锁的数量(重入次数),因为 state 高16位记录的是全局范围内所有的读线程获取读锁的总量 static final class HoldCounter {int count = 0;// Use id, not reference, to avoid garbage retentionfinal long tid = getThreadId(Thread.currentThread()); } // 线程安全的存放线程各自的 HoldCounter 对象 static final class ThreadLocalHoldCounter extends ThreadLocal{public HoldCounter initialValue() {return new HoldCounter();} } -
内部类实例:
// 当前线程持有的可重入读锁的数量,计数为 0 时删除 private transient ThreadLocalHoldCounter readHolds; // 记录最后一个获取【读锁】线程的 HoldCounter 对象 private transient HoldCounter cachedHoldCounter; -
首次获取锁:
// 第一个获取读锁的线程 private transient Thread firstReader = null; // 记录该线程持有的读锁次数(读锁重入次数) private transient int firstReaderHoldCount; -
Sync 构造方法:
Sync() {readHolds = new ThreadLocalHoldCounter();// 确保其他线程的数据可见性,state 是 volatile 修饰的变量,重写该值会将线程本地缓存数据【同步至主存】setState(getState()); }
加锁原理
-
t1 线程:w.lock(写锁),成功上锁 state = 0_1
// lock() -> sync.acquire(1); public void lock() {sync.acquire(1); } public final void acquire(int arg) {// 尝试获得写锁,获得写锁失败,将当前线程关联到一个 Node 对象上, 模式为独占模式 if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt(); }protected final boolean tryAcquire(int acquires) {Thread current = Thread.currentThread();int c = getState();// 获得低 16 位, 代表写锁的 state 计数int w = exclusiveCount(c);// 说明有读锁或者写锁if (c != 0) {// c != 0 and w == 0 表示有读锁,【读锁不能升级】,直接返回 false// w != 0 说明有写锁,写锁的拥有者不是自己,获取失败if (w == 0 || current != getExclusiveOwnerThread())return false;// 执行到这里只有一种情况:【写锁重入】,所以下面几行代码不存在并发if (w + exclusiveCount(acquires) > MAX_COUNT)throw new Error("Maximum lock count exceeded");// 写锁重入, 获得锁成功,没有并发,所以不使用 CASsetState(c + acquires);return true;}// c == 0,说明没有任何锁,判断写锁是否该阻塞,是 false 就尝试获取锁,失败返回 falseif (writerShouldBlock() || !compareAndSetState(c, c + acquires))return false;// 获得锁成功,设置锁的持有线程为当前线程setExclusiveOwnerThread(current);return true; } // 非公平锁 writerShouldBlock 总是返回 false, 无需阻塞 final boolean writerShouldBlock() {return false; } // 公平锁会检查 AQS 队列中是否有前驱节点, 没有(false)才去竞争 final boolean writerShouldBlock() {return hasQueuedPredecessors(); } -
t2 r.lock(读锁),进入 tryAcquireShared 流程:
- 返回 -1 表示失败
- 如果返回 0 表示成功
- 返回正数表示还有多少后继节点支持共享模式,读写锁返回 1
public void lock() {sync.acquireShared(1); } public final void acquireShared(int arg) {// tryAcquireShared 返回负数, 表示获取读锁失败if (tryAcquireShared(arg) < 0)doAcquireShared(arg); }// 尝试以共享模式获取 protected final int tryAcquireShared(int unused) {Thread current = Thread.currentThread();int c = getState();// exclusiveCount(c) 代表低 16 位, 写锁的 state,成立说明有线程持有写锁// 写锁的持有者不是当前线程,则获取读锁失败,【写锁允许降级】if (exclusiveCount(c) != 0 && getExclusiveOwnerThread() != current)return -1;// 高 16 位,代表读锁的 state,共享锁分配出去的总次数int r = sharedCount(c);// 读锁是否应该阻塞if (!readerShouldBlock() && r < MAX_COUNT &&compareAndSetState(c, c + SHARED_UNIT)) { // 尝试增加读锁计数// 加锁成功// 加锁之前读锁为 0,说明当前线程是第一个读锁线程if (r == 0) {firstReader = current;firstReaderHoldCount = 1;// 第一个读锁线程是自己就发生了读锁重入} else if (firstReader == current) {firstReaderHoldCount++;} else {// cachedHoldCounter 设置为当前线程的 holdCounter 对象,即最后一个获取读锁的线程HoldCounter rh = cachedHoldCounter;// 说明还没设置 rhif (rh == null || rh.tid != getThreadId(current))// 获取当前线程的锁重入的对象,赋值给 cachedHoldCountercachedHoldCounter = rh = readHolds.get();// 还没重入else if (rh.count == 0)readHolds.set(rh);// 重入 + 1rh.count++;}// 读锁加锁成功return 1;}// 逻辑到这 应该阻塞,或者 cas 加锁失败// 会不断尝试 for (;;) 获取读锁, 执行过程中无阻塞return fullTryAcquireShared(current); } // 非公平锁 readerShouldBlock 偏向写锁一些,看 AQS 阻塞队列中第一个节点是否是写锁,是则阻塞,反之不阻塞 // 防止一直有读锁线程,导致写锁线程饥饿 // true 则该阻塞, false 则不阻塞 final boolean readerShouldBlock() {return apparentlyFirstQueuedIsExclusive(); } final boolean readerShouldBlock() {return hasQueuedPredecessors(); }final int fullTryAcquireShared(Thread current) {// 当前读锁线程持有的读锁次数对象HoldCounter rh = null;for (;;) {int c = getState();// 说明有线程持有写锁if (exclusiveCount(c) != 0) {// 写锁不是自己则获取锁失败if (getExclusiveOwnerThread() != current)return -1;} else if (readerShouldBlock()) {// 条件成立说明当前线程是 firstReader,当前锁是读忙碌状态,而且当前线程也是读锁重入if (firstReader == current) {// assert firstReaderHoldCount > 0;} else {if (rh == null) {// 最后一个读锁的 HoldCounterrh = cachedHoldCounter;// 说明当前线程也不是最后一个读锁if (rh == null || rh.tid != getThreadId(current)) {// 获取当前线程的 HoldCounterrh = readHolds.get();// 条件成立说明 HoldCounter 对象是上一步代码新建的// 当前线程不是锁重入,在 readerShouldBlock() 返回 true 时需要去排队if (rh.count == 0)// 防止内存泄漏readHolds.remove();}}if (rh.count == 0)return -1;}}// 越界判断if (sharedCount(c) == MAX_COUNT)throw new Error("Maximum lock count exceeded");// 读锁加锁,条件内的逻辑与 tryAcquireShared 相同if (compareAndSetState(c, c + SHARED_UNIT)) {if (sharedCount(c) == 0) {firstReader = current;firstReaderHoldCount = 1;} else if (firstReader == current) {firstReaderHoldCount++;} else {if (rh == null)rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current))rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh);rh.count++;cachedHoldCounter = rh; // cache for release}return 1;}} } -
获取读锁失败,进入 sync.doAcquireShared(1) 流程开始阻塞,首先也是调用 addWaiter 添加节点,不同之处在于节点被设置为 Node.SHARED 模式而非 Node.EXCLUSIVE 模式,注意此时 t2 仍处于活跃状态
private void doAcquireShared(int arg) {// 将当前线程关联到一个 Node 对象上, 模式为共享模式final Node node = addWaiter(Node.SHARED);boolean failed = true;try {boolean interrupted = false;for (;;) {// 获取前驱节点final Node p = node.predecessor();// 如果前驱节点就头节点就去尝试获取锁if (p == head) {// 再一次尝试获取读锁int r = tryAcquireShared(arg);// r >= 0 表示获取成功if (r >= 0) {//【这里会设置自己为头节点,唤醒相连的后序的共享节点】setHeadAndPropagate(node, r);p.next = null; // help GCif (interrupted)selfInterrupt();failed = false;return;}}// 是否在获取读锁失败时阻塞 park 当前线程if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);} }如果没有成功,在 doAcquireShared 内 for (;😉 循环一次,shouldParkAfterFailedAcquire 内把前驱节点的 waitStatus 改为 -1,再 for (;😉 循环一次尝试 tryAcquireShared,不成功在 parkAndCheckInterrupt() 处 park
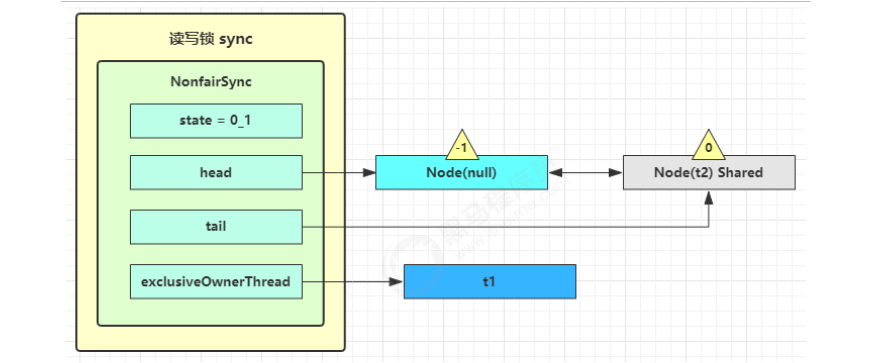
-
这种状态下,假设又有 t3 r.lock,t4 w.lock,这期间 t1 仍然持有锁,就变成了下面的样子
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M0Q6LiFj-1679358011070)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ReentrantReadWriteLock加锁2.png)]
解锁原理
-
t1 w.unlock, 写锁解锁
public void unlock() {// 释放锁sync.release(1); } public final boolean release(int arg) {// 尝试释放锁if (tryRelease(arg)) {Node h = head;// 头节点不为空并且不是等待状态不是 0,唤醒后继的非取消节点if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false; } protected final boolean tryRelease(int releases) {if (!isHeldExclusively())throw new IllegalMonitorStateException();int nextc = getState() - releases;// 因为可重入的原因, 写锁计数为 0, 才算释放成功boolean free = exclusiveCount(nextc) == 0;if (free)setExclusiveOwnerThread(null);setState(nextc);return free; } -
唤醒流程 sync.unparkSuccessor,这时 t2 在 doAcquireShared 的 parkAndCheckInterrupt() 处恢复运行,继续循环,执行 tryAcquireShared 成功则让读锁计数加一
-
接下来 t2 调用 setHeadAndPropagate(node, 1),它原本所在节点被置为头节点;还会检查下一个节点是否是 shared,如果是则调用 doReleaseShared() 将 head 的状态从 -1 改为 0 并唤醒下一个节点,这时 t3 在 doAcquireShared 内 parkAndCheckInterrupt() 处恢复运行,唤醒连续的所有的共享节点
private void setHeadAndPropagate(Node node, int propagate) {Node h = head; // 设置自己为 head 节点setHead(node);// propagate 表示有共享资源(例如共享读锁或信号量),为 0 就没有资源if (propagate > 0 || h == null || h.waitStatus < 0 ||(h = head) == null || h.waitStatus < 0) {// 获取下一个节点Node s = node.next;// 如果当前是最后一个节点,或者下一个节点是【等待共享读锁的节点】if (s == null || s.isShared())// 唤醒后继节点doReleaseShared();} }private void doReleaseShared() {// 如果 head.waitStatus == Node.SIGNAL ==> 0 成功, 下一个节点 unpark// 如果 head.waitStatus == 0 ==> Node.PROPAGATEfor (;;) {Node h = head;if (h != null && h != tail) {int ws = h.waitStatus;// SIGNAL 唤醒后继if (ws == Node.SIGNAL) {// 因为读锁共享,如果其它线程也在释放读锁,那么需要将 waitStatus 先改为 0// 防止 unparkSuccessor 被多次执行if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))continue; // 唤醒后继节点unparkSuccessor(h);}// 如果已经是 0 了,改为 -3,用来解决传播性else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))continue; }// 条件不成立说明被唤醒的节点非常积极,直接将自己设置为了新的 head,// 此时唤醒它的节点(前驱)执行 h == head 不成立,所以不会跳出循环,会继续唤醒新的 head 节点的后继节点if (h == head) break;} }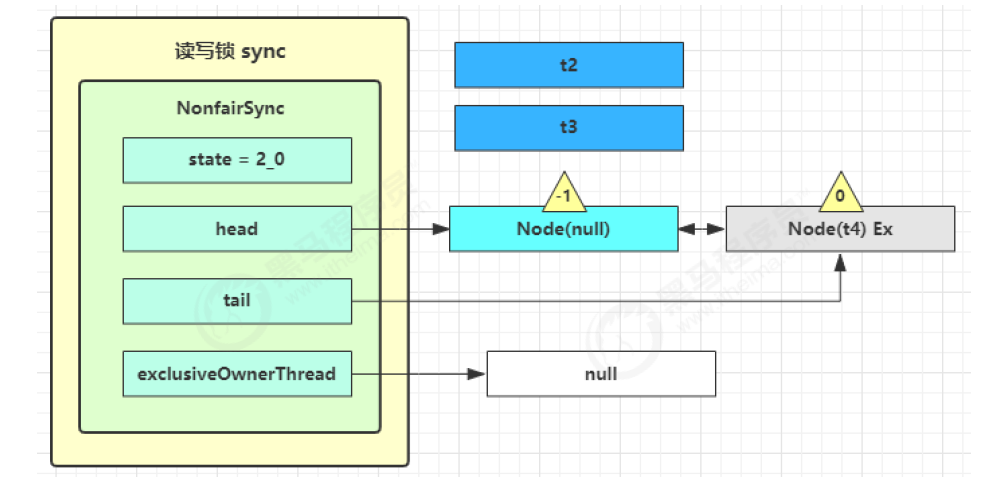
-
下一个节点不是 shared 了,因此不会继续唤醒 t4 所在节点
-
t2 读锁解锁,进入 sync.releaseShared(1) 中,调用 tryReleaseShared(1) 让计数减一,但计数还不为零,t3 同样让计数减一,计数为零,进入doReleaseShared() 将头节点从 -1 改为 0 并唤醒下一个节点
public void unlock() {sync.releaseShared(1); } public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {doReleaseShared();return true;}return false; }protected final boolean tryReleaseShared(int unused) {for (;;) {int c = getState();int nextc = c - SHARED_UNIT;// 读锁的计数不会影响其它获取读锁线程, 但会影响其它获取写锁线程,计数为 0 才是真正释放if (compareAndSetState(c, nextc))// 返回是否已经完全释放了 return nextc == 0;} } -
t4 在 acquireQueued 中 parkAndCheckInterrupt 处恢复运行,再次 for (;😉 这次自己是头节点的临节点,并且没有其他节点竞争,tryAcquire(1) 成功,修改头结点,流程结束
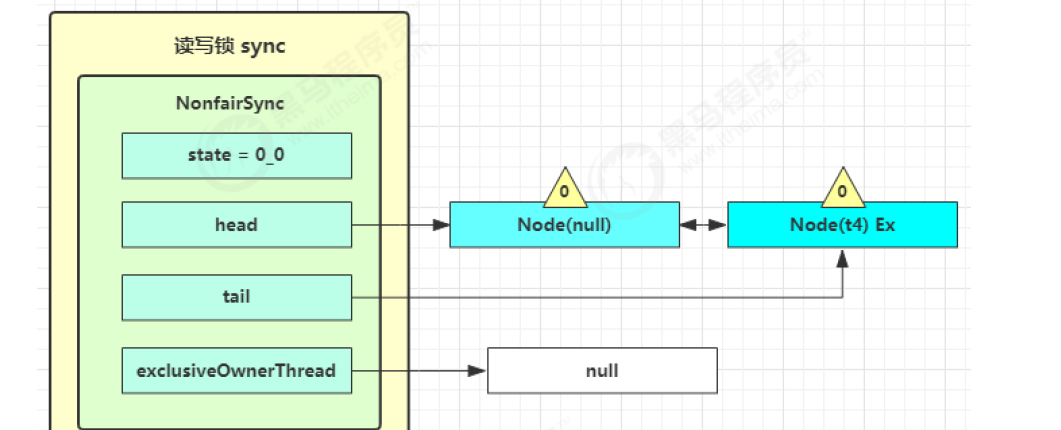
Stamped
StampedLock:读写锁,该类自 JDK 8 加入,是为了进一步优化读性能
特点:
-
在使用读锁、写锁时都必须配合戳使用
-
StampedLock 不支持条件变量
-
StampedLock 不支持重入
基本用法
-
加解读锁:
long stamp = lock.readLock(); lock.unlockRead(stamp); // 类似于 unpark,解指定的锁 -
加解写锁:
long stamp = lock.writeLock(); lock.unlockWrite(stamp); -
乐观读,StampedLock 支持
tryOptimisticRead()方法,读取完毕后做一次戳校验,如果校验通过,表示这期间没有其他线程的写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据一致性long stamp = lock.tryOptimisticRead(); // 验戳 if(!lock.validate(stamp)){// 锁升级 }
提供一个数据容器类内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法:
- 读-读可以优化
- 读-写优化读,补加读锁
public static void main(String[] args) throws InterruptedException {DataContainerStamped dataContainer = new DataContainerStamped(1);new Thread(() -> {dataContainer.read(1000);},"t1").start();Thread.sleep(500);new Thread(() -> {dataContainer.write(1000);},"t2").start();
}class DataContainerStamped {private int data;private final StampedLock lock = new StampedLock();public int read(int readTime) throws InterruptedException {long stamp = lock.tryOptimisticRead();System.out.println(new Date() + " optimistic read locking" + stamp);Thread.sleep(readTime);// 戳有效,直接返回数据if (lock.validate(stamp)) {Sout(new Date() + " optimistic read finish..." + stamp);return data;}// 说明其他线程更改了戳,需要锁升级了,从乐观读升级到读锁System.out.println(new Date() + " updating to read lock" + stamp);try {stamp = lock.readLock();System.out.println(new Date() + " read lock" + stamp);Thread.sleep(readTime);System.out.println(new Date() + " read finish..." + stamp);return data;} finally {System.out.println(new Date() + " read unlock " + stamp);lock.unlockRead(stamp);}}public void write(int newData) {long stamp = lock.writeLock();System.out.println(new Date() + " write lock " + stamp);try {Thread.sleep(2000);this.data = newData;} catch (InterruptedException e) {e.printStackTrace();} finally {System.out.println(new Date() + " write unlock " + stamp);lock.unlockWrite(stamp);}}
}
CountDown
基本使用
CountDownLatch:计数器,用来进行线程同步协作,等待所有线程完成
构造器:
public CountDownLatch(int count):初始化唤醒需要的 down 几步
常用API:
public void await():让当前线程等待,必须 down 完初始化的数字才可以被唤醒,否则进入无限等待public void countDown():计数器进行减 1(down 1)
应用:同步等待多个 Rest 远程调用结束
// LOL 10人进入游戏倒计时
public static void main(String[] args) throws InterruptedException {CountDownLatch latch = new CountDownLatch(10);ExecutorService service = Executors.newFixedThreadPool(10);String[] all = new String[10];Random random = new Random();for (int j = 0; j < 10; j++) {int finalJ = j;//常量service.submit(() -> {for (int i = 0; i <= 100; i++) {Thread.sleep(random.nextInt(100)); //随机休眠all[finalJ] = i + "%";System.out.print("\r" + Arrays.toString(all)); // \r代表覆盖}latch.countDown();});}latch.await();System.out.println("\n游戏开始");service.shutdown();
}
/*
[100%, 100%, 100%, 100%, 100%, 100%, 100%, 100%, 100%, 100%]
游戏开始
实现原理
阻塞等待:
-
线程调用 await() 等待其他线程完成任务:支持打断
public void await() throws InterruptedException {sync.acquireSharedInterruptibly(1); } // AbstractQueuedSynchronizer#acquireSharedInterruptibly public final void acquireSharedInterruptibly(int arg) throws InterruptedException {// 判断线程是否被打断,抛出打断异常if (Thread.interrupted())throw new InterruptedException();// 尝试获取共享锁,条件成立说明 state > 0,此时线程入队阻塞等待,等待其他线程获取共享资源// 条件不成立说明 state = 0,此时不需要阻塞线程,直接结束函数调用if (tryAcquireShared(arg) < 0)doAcquireSharedInterruptibly(arg); } // CountDownLatch.Sync#tryAcquireShared protected int tryAcquireShared(int acquires) {return (getState() == 0) ? 1 : -1; } -
线程进入 AbstractQueuedSynchronizer#doAcquireSharedInterruptibly 函数阻塞挂起,等待 latch 变为 0:
private void doAcquireSharedInterruptibly(int arg) throws InterruptedException {// 将调用latch.await()方法的线程 包装成 SHARED 类型的 node 加入到 AQS 的阻塞队列中final Node node = addWaiter(Node.SHARED);boolean failed = true;try {for (;;) {// 获取当前节点的前驱节点final Node p = node.predecessor();// 前驱节点时头节点就可以尝试获取锁if (p == head) {// 再次尝试获取锁,获取成功返回 1int r = tryAcquireShared(arg);if (r >= 0) {// 获取锁成功,设置当前节点为 head 节点,并且向后传播setHeadAndPropagate(node, r);p.next = null; // help GCfailed = false;return;}}// 阻塞在这里if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())throw new InterruptedException();}} finally {// 阻塞线程被中断后抛出异常,进入取消节点的逻辑if (failed)cancelAcquire(node);} } -
获取共享锁成功,进入唤醒阻塞队列中与头节点相连的 SHARED 模式的节点:
private void setHeadAndPropagate(Node node, int propagate) {Node h = head;// 将当前节点设置为新的 head 节点,前驱节点和持有线程置为 nullsetHead(node);// propagate = 1,条件一成立if (propagate > 0 || h == null || h.waitStatus < 0 || (h = head) == null || h.waitStatus < 0) {// 获取当前节点的后继节点Node s = node.next;// 当前节点是尾节点时 next 为 null,或者后继节点是 SHARED 共享模式if (s == null || s.isShared())// 唤醒所有的等待共享锁的节点doReleaseShared();} }
计数减一:
-
线程进入 countDown() 完成计数器减一(释放锁)的操作
public void countDown() {sync.releaseShared(1); } public final boolean releaseShared(int arg) {// 尝试释放共享锁if (tryReleaseShared(arg)) {// 释放锁成功开始唤醒阻塞节点doReleaseShared();return true;}return false; } -
更新 state 值,每调用一次,state 值减一,当 state -1 正好为 0 时,返回 true
protected boolean tryReleaseShared(int releases) {for (;;) {int c = getState();// 条件成立说明前面【已经有线程触发唤醒操作】了,这里返回 falseif (c == 0)return false;// 计数器减一int nextc = c-1;if (compareAndSetState(c, nextc))// 计数器为 0 时返回 truereturn nextc == 0;} } -
state = 0 时,当前线程需要执行唤醒阻塞节点的任务
private void doReleaseShared() {for (;;) {Node h = head;// 判断队列是否是空队列if (h != null && h != tail) {int ws = h.waitStatus;// 头节点的状态为 signal,说明后继节点没有被唤醒过if (ws == Node.SIGNAL) {// cas 设置头节点的状态为 0,设置失败继续自旋if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))continue;// 唤醒后继节点unparkSuccessor(h);}// 如果有其他线程已经设置了头节点的状态,重新设置为 PROPAGATE 传播属性else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))continue;}// 条件不成立说明被唤醒的节点非常积极,直接将自己设置为了新的head,// 此时唤醒它的节点(前驱)执行 h == head 不成立,所以不会跳出循环,会继续唤醒新的 head 节点的后继节点if (h == head)break;} }
CyclicBarrier
基本使用
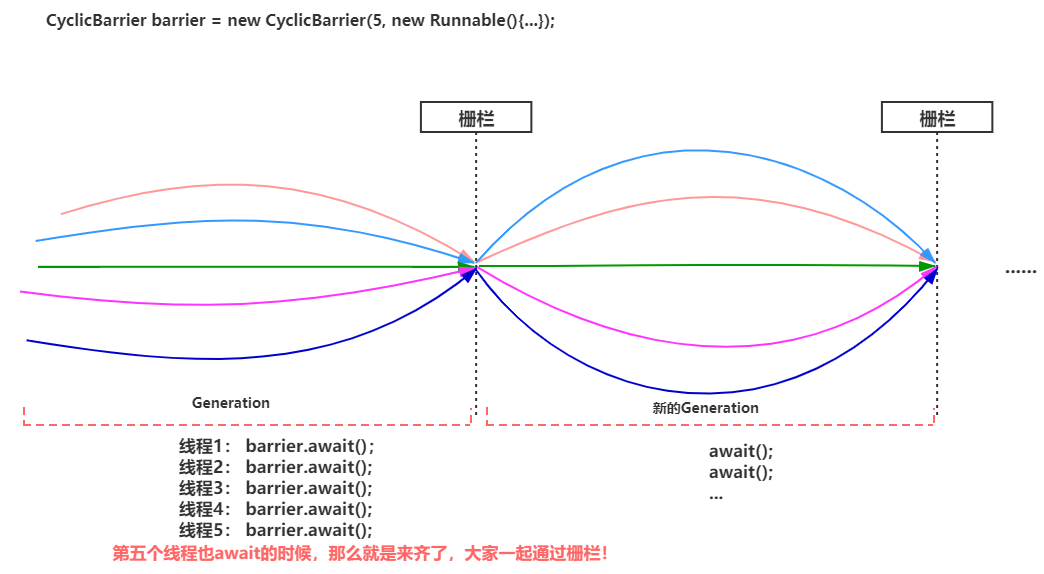
CyclicBarrier:循环屏障,用来进行线程协作,等待线程满足某个计数,才能触发自己执行
常用方法:
public CyclicBarrier(int parties, Runnable barrierAction):用于在线程到达屏障 parties 时,执行 barrierAction- parties:代表多少个线程到达屏障开始触发线程任务
- barrierAction:线程任务
public int await():线程调用 await 方法通知 CyclicBarrier 本线程已经到达屏障
与 CountDownLatch 的区别:CyclicBarrier 是可以重用的
应用:可以实现多线程中,某个任务在等待其他线程执行完毕以后触发
public static void main(String[] args) {ExecutorService service = Executors.newFixedThreadPool(2);CyclicBarrier barrier = new CyclicBarrier(2, () -> {System.out.println("task1 task2 finish...");});for (int i = 0; i < 3; i++) { // 循环重用service.submit(() -> {System.out.println("task1 begin...");try {Thread.sleep(1000);barrier.await(); // 2 - 1 = 1} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();}});service.submit(() -> {System.out.println("task2 begin...");try {Thread.sleep(2000);barrier.await(); // 1 - 1 = 0} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();}});}service.shutdown();
}
实现原理
成员属性
-
全局锁:利用可重入锁实现的工具类
// barrier 实现是依赖于Condition条件队列,condition 条件队列必须依赖lock才能使用 private final ReentrantLock lock = new ReentrantLock(); // 线程挂起实现使用的 condition 队列,当前代所有线程到位,这个条件队列内的线程才会被唤醒 private final Condition trip = lock.newCondition(); -
线程数量:
private final int parties; // 代表多少个线程到达屏障开始触发线程任务 private int count; // 表示当前“代”还有多少个线程未到位,初始值为 parties -
当前代中最后一个线程到位后要执行的事件:
private final Runnable barrierCommand; -
代:
// 表示 barrier 对象当前 代 private Generation generation = new Generation(); private static class Generation {// 表示当前“代”是否被打破,如果被打破再来到这一代的线程 就会直接抛出 BrokenException 异常// 且在这一代挂起的线程都会被唤醒,然后抛出 BrokerException 异常。boolean broken = false; } -
构造方法:
public CyclicBarrie(int parties, Runnable barrierAction) {// 因为小于等于 0 的 barrier 没有任何意义if (parties <= 0) throw new IllegalArgumentException();this.parties = parties;this.count = parties;// 可以为 nullthis.barrierCommand = barrierAction; }
成员方法
-
await():阻塞等待所有线程到位
public int await() throws InterruptedException, BrokenBarrierException {try {return dowait(false, 0L);} catch (TimeoutException toe) {throw new Error(toe); // cannot happen} }// timed:表示当前调用await方法的线程是否指定了超时时长,如果 true 表示线程是响应超时的 // nanos:线程等待超时时长,单位是纳秒 private int dowait(boolean timed, long nanos) {final ReentrantLock lock = this.lock;// 加锁lock.lock();try {// 获取当前代final Generation g = generation;// 【如果当前代是已经被打破状态,则当前调用await方法的线程,直接抛出Broken异常】if (g.broken)throw new BrokenBarrierException();// 如果当前线程被中断了,则打破当前代,然后当前线程抛出中断异常if (Thread.interrupted()) {// 设置当前代的状态为 broken 状态,唤醒在 trip 条件队列内的线程breakBarrier();throw new InterruptedException();}// 逻辑到这说明,当前线程中断状态是 false, 当前代的 broken 为 false(未打破状态)// 假设 parties 给的是 5,那么index对应的值为 4,3,2,1,0int index = --count;// 条件成立说明当前线程是最后一个到达 barrier 的线程,【需要开启新代,唤醒阻塞线程】if (index == 0) {// 栅栏任务启动标记boolean ranAction = false;try {final Runnable command = barrierCommand;if (command != null)// 启动触发的任务command.run();// run()未抛出异常的话,启动标记设置为 trueranAction = true;// 开启新的一代,这里会【唤醒所有的阻塞队列】nextGeneration();// 返回 0 因为当前线程是此代最后一个到达的线程,index == 0return 0;} finally {// 如果 command.run() 执行抛出异常的话,会进入到这里if (!ranAction)breakBarrier();}}// 自旋,一直到条件满足、当前代被打破、线程被中断,等待超时for (;;) {try {// 根据是否需要超时等待选择阻塞方法if (!timed)// 当前线程释放掉 lock,【进入到 trip 条件队列的尾部挂起自己】,等待被唤醒trip.await();else if (nanos > 0L)nanos = trip.awaitNanos(nanos);} catch (InterruptedException ie) {// 被中断后来到这里的逻辑// 当前代没有变化并且没有被打破if (g == generation && !g.broken) {// 打破屏障breakBarrier();// node 节点在【条件队列】内收到中断信号时 会抛出中断异常throw ie;} else {// 等待过程中代变化了,完成一次自我打断Thread.currentThread().interrupt();}}// 唤醒后的线程,【判断当前代已经被打破,线程唤醒后依次抛出 BrokenBarrier 异常】if (g.broken)throw new BrokenBarrierException();// 当前线程挂起期间,最后一个线程到位了,然后触发了开启新的一代的逻辑if (g != generation)return index;// 当前线程 trip 中等待超时,然后主动转移到阻塞队列if (timed && nanos <= 0L) {breakBarrier();// 抛出超时异常throw new TimeoutException();}}} finally {// 解锁lock.unlock();} } -
breakBarrier():打破 Barrier 屏障
private void breakBarrier() {// 将代中的 broken 设置为 true,表示这一代是被打破了,再来到这一代的线程,直接抛出异常generation.broken = true;// 重置 count 为 partiescount = parties;// 将在trip条件队列内挂起的线程全部唤醒,唤醒后的线程会检查当前是否是打破的,然后抛出异常trip.signalAll(); } -
nextGeneration():开启新的下一代
private void nextGeneration() {// 将在 trip 条件队列内挂起的线程全部唤醒trip.signalAll();// 重置 count 为 partiescount = parties;// 开启新的一代,使用一个新的generation对象,表示新的一代,新的一代和上一代【没有任何关系】generation = new Generation(); }
参考视频:https://space.bilibili.com/457326371/
Semaphore
基本使用
synchronized 可以起到锁的作用,但某个时间段内,只能有一个线程允许执行
Semaphore(信号量)用来限制能同时访问共享资源的线程上限,非重入锁
构造方法:
public Semaphore(int permits):permits 表示许可线程的数量(state)public Semaphore(int permits, boolean fair):fair 表示公平性,如果设为 true,下次执行的线程会是等待最久的线程
常用API:
public void acquire():表示获取许可public void release():表示释放许可,acquire() 和 release() 方法之间的代码为同步代码
public static void main(String[] args) {// 1.创建Semaphore对象Semaphore semaphore = new Semaphore(3);// 2. 10个线程同时运行for (int i = 0; i < 10; i++) {new Thread(() -> {try {// 3. 获取许可semaphore.acquire();sout(Thread.currentThread().getName() + " running...");Thread.sleep(1000);sout(Thread.currentThread().getName() + " end...");} catch (InterruptedException e) {e.printStackTrace();} finally {// 4. 释放许可semaphore.release();}}).start();}
}
实现原理
加锁流程:
-
Semaphore 的 permits(state)为 3,这时 5 个线程来获取资源
Sync(int permits) {setState(permits); }假设其中 Thread-1,Thread-2,Thread-4 CAS 竞争成功,permits 变为 0,而 Thread-0 和 Thread-3 竞争失败,进入 AQS 队列park 阻塞
// acquire() -> sync.acquireSharedInterruptibly(1),可中断 public final void acquireSharedInterruptibly(int arg) {if (Thread.interrupted())throw new InterruptedException();// 尝试获取通行证,获取成功返回 >= 0的值if (tryAcquireShared(arg) < 0)// 获取许可证失败,进入阻塞doAcquireSharedInterruptibly(arg); }// tryAcquireShared() -> nonfairTryAcquireShared() // 非公平,公平锁会在循环内 hasQueuedPredecessors()方法判断阻塞队列是否有临头节点(第二个节点) final int nonfairTryAcquireShared(int acquires) {for (;;) {// 获取 state ,state 这里【表示通行证】int available = getState();// 计算当前线程获取通行证完成之后,通行证还剩余数量int remaining = available - acquires;// 如果许可已经用完, 返回负数, 表示获取失败,if (remaining < 0 ||// 许可证足够分配的,如果 cas 重试成功, 返回正数, 表示获取成功compareAndSetState(available, remaining))return remaining;} }private void doAcquireSharedInterruptibly(int arg) {// 将调用 Semaphore.aquire 方法的线程,包装成 node 加入到 AQS 的阻塞队列中final Node node = addWaiter(Node.SHARED);// 获取标记boolean failed = true;try {for (;;) {final Node p = node.predecessor();// 前驱节点是头节点可以再次获取许可if (p == head) {// 再次尝试获取许可,【返回剩余的许可证数量】int r = tryAcquireShared(arg);if (r >= 0) {// 成功后本线程出队(AQS), 所在 Node设置为 head// r 表示【可用资源数】, 为 0 则不会继续传播setHeadAndPropagate(node, r); p.next = null; // help GCfailed = false;return;}}// 不成功, 设置上一个节点 waitStatus = Node.SIGNAL, 下轮进入 park 阻塞if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())throw new InterruptedException();}} finally {// 被打断后进入该逻辑if (failed)cancelAcquire(node);} }private void setHeadAndPropagate(Node node, int propagate) { Node h = head;// 设置自己为 head 节点setHead(node);// propagate 表示有【共享资源】(例如共享读锁或信号量)// head waitStatus == Node.SIGNAL 或 Node.PROPAGATE,doReleaseShared 函数中设置的if (propagate > 0 || h == null || h.waitStatus < 0 ||(h = head) == null || h.waitStatus < 0) {Node s = node.next;// 如果是最后一个节点或者是等待共享读锁的节点,做一次唤醒if (s == null || s.isShared())doReleaseShared();} }[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WrbhE0UI-1679358011070)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-Semaphore工作流程1.png)]
-
这时 Thread-4 释放了 permits,状态如下
// release() -> releaseShared() public final boolean releaseShared(int arg) {// 尝试释放锁if (tryReleaseShared(arg)) {doReleaseShared();return true;} return false; } protected final boolean tryReleaseShared(int releases) { for (;;) {// 获取当前锁资源的可用许可证数量int current = getState();int next = current + releases;// 索引越界判断if (next < current) throw new Error("Maximum permit count exceeded"); // 释放锁if (compareAndSetState(current, next)) return true; } } private void doReleaseShared() { // PROPAGATE 详解 // 如果 head.waitStatus == Node.SIGNAL ==> 0 成功, 下一个节点 unpark // 如果 head.waitStatus == 0 ==> Node.PROPAGATE }[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x0H5rvkj-1679358011070)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-Semaphore工作流程2.png)]
-
接下来 Thread-0 竞争成功,permits 再次设置为 0,设置自己为 head 节点,并且 unpark 接下来的共享状态的 Thread-3 节点,但由于 permits 是 0,因此 Thread-3 在尝试不成功后再次进入 park 状态
PROPAGATE
假设存在某次循环中队列里排队的结点情况为 head(-1) → t1(-1) → t2(0),存在将要释放信号量的 T3 和 T4,释放顺序为先 T3 后 T4
// 老版本代码
private void setHeadAndPropagate(Node node, int propagate) { setHead(node); // 有空闲资源 if (propagate > 0 && node.waitStatus != 0) { Node s = node.next; // 下一个 if (s == null || s.isShared()) unparkSuccessor(node); }
}
正常流程:
- T3 调用 releaseShared(1),直接调用了 unparkSuccessor(head),head.waitStatus 从 -1 变为 0
- T1 由于 T3 释放信号量被唤醒,然后 T4 释放,唤醒 T2
BUG 流程:
- T3 调用 releaseShared(1),直接调用了 unparkSuccessor(head),head.waitStatus 从 -1 变为 0
- T1 由于 T3 释放信号量被唤醒,调用 tryAcquireShared,返回值为 0(获取锁成功,但没有剩余资源量)
- T1 还没调用 setHeadAndPropagate 方法,T4 调用 releaseShared(1),此时 head.waitStatus 为 0(此时读到的 head 和 1 中为同一个 head),不满足条件,因此不调用 unparkSuccessor(head)
- T1 获取信号量成功,调用 setHeadAndPropagate(t1.node, 0) 时,因为不满足 propagate > 0(剩余资源量 == 0),从而不会唤醒后继结点, T2 线程得不到唤醒
更新后流程:
-
T3 调用 releaseShared(1),直接调用了 unparkSuccessor(head),head.waitStatus 从 -1 变为 0
-
T1 由于 T3 释放信号量被唤醒,调用 tryAcquireShared,返回值为 0(获取锁成功,但没有剩余资源量)
-
T1 还没调用 setHeadAndPropagate 方法,T4 调用 releaseShared(),此时 head.waitStatus 为 0(此时读到的 head 和 1 中为同一个 head),调用 doReleaseShared() 将等待状态置为 PROPAGATE(-3)
-
T1 获取信号量成功,调用 setHeadAndPropagate 时,读到 h.waitStatus < 0,从而调用 doReleaseShared() 唤醒 T2
private void setHeadAndPropagate(Node node, int propagate) { Node h = head;// 设置自己为 head 节点setHead(node);// propagate 表示有共享资源(例如共享读锁或信号量)// head waitStatus == Node.SIGNAL 或 Node.PROPAGATEif (propagate > 0 || h == null || h.waitStatus < 0 ||(h = head) == null || h.waitStatus < 0) {Node s = node.next;// 如果是最后一个节点或者是等待共享读锁的节点,做一次唤醒if (s == null || s.isShared())doReleaseShared();}
}
// 唤醒
private void doReleaseShared() {// 如果 head.waitStatus == Node.SIGNAL ==> 0 成功, 下一个节点 unpark // 如果 head.waitStatus == 0 ==> Node.PROPAGATE for (;;) {Node h = head;if (h != null && h != tail) {int ws = h.waitStatus;if (ws == Node.SIGNAL) {// 防止 unparkSuccessor 被多次执行if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))continue;// 唤醒后继节点unparkSuccessor(h);}// 如果已经是 0 了,改为 -3,用来解决传播性else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))continue;}if (h == head)break;}
}
Exchanger
Exchanger:交换器,是一个用于线程间协作的工具类,用于进行线程间的数据交换
工作流程:两个线程通过 exchange 方法交换数据,如果第一个线程先执行 exchange() 方法,它会一直等待第二个线程也执行 exchange 方法,当两个线程都到达同步点时,这两个线程就可以交换数据
常用方法:
public Exchanger():创建一个新的交换器public V exchange(V x):等待另一个线程到达此交换点public V exchange(V x, long timeout, TimeUnit unit):等待一定的时间
public class ExchangerDemo {public static void main(String[] args) {// 创建交换对象(信使)Exchanger exchanger = new Exchanger<>();new ThreadA(exchanger).start();new ThreadB(exchanger).start();}
}
class ThreadA extends Thread{private Exchanger exchanger();public ThreadA(Exchanger exchanger){this.exchanger = exchanger;}@Overridepublic void run() {try{sout("线程A,做好了礼物A,等待线程B送来的礼物B");//如果等待了5s还没有交换就死亡(抛出异常)!String s = exchanger.exchange("礼物A",5,TimeUnit.SECONDS);sout("线程A收到线程B的礼物:" + s);} catch (Exception e) {System.out.println("线程A等待了5s,没有收到礼物,最终就执行结束了!");}}
}
class ThreadB extends Thread{private Exchanger exchanger;public ThreadB(Exchanger exchanger) {this.exchanger = exchanger;}@Overridepublic void run() {try {sout("线程B,做好了礼物B,等待线程A送来的礼物A.....");// 开始交换礼物。参数是送给其他线程的礼物!sout("线程B收到线程A的礼物:" + exchanger.exchange("礼物B"));} catch (Exception e) {e.printStackTrace();}}
}
并发包
ConHashMap
并发集合
集合对比
三种集合:
- HashMap 是线程不安全的,性能好
- Hashtable 线程安全基于 synchronized,综合性能差,已经被淘汰
- ConcurrentHashMap 保证了线程安全,综合性能较好,不止线程安全,而且效率高,性能好
集合对比:
- Hashtable 继承 Dictionary 类,HashMap、ConcurrentHashMap 继承 AbstractMap,均实现 Map 接口
- Hashtable 底层是数组 + 链表,JDK8 以后 HashMap 和 ConcurrentHashMap 底层是数组 + 链表 + 红黑树
- HashMap 线程非安全,Hashtable 线程安全,Hashtable 的方法都加了 synchronized 关来确保线程同步
- ConcurrentHashMap、Hashtable 不允许 null 值,HashMap 允许 null 值
- ConcurrentHashMap、HashMap 的初始容量为 16,Hashtable 初始容量为11,填充因子默认都是 0.75,两种 Map 扩容是当前容量翻倍:capacity * 2,Hashtable 扩容时是容量翻倍 + 1:capacity*2 + 1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IpLtKn7N-1679358011071)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/ConcurrentHashMap数据结构.png)]
工作步骤:
-
初始化,使用 cas 来保证并发安全,懒惰初始化 table
-
树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程会用 synchronized 锁住链表头
说明:锁住某个槽位的对象头,是一种很好的细粒度的加锁方式,类似 MySQL 中的行锁
-
put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put 操作,元素添加至 bin 的尾部
-
get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 会让 get 操作在新 table 进行搜索
-
扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时其它竞争线程也不是无事可做,它们会帮助把其它 bin 进行扩容
-
size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中,最后统计数量时累加
//需求:多个线程同时往HashMap容器中存入数据会出现安全问题
public class ConcurrentHashMapDemo{public static Map map = new ConcurrentHashMap();public static void main(String[] args){new AddMapDataThread().start();new AddMapDataThread().start();Thread.sleep(1000 * 5);//休息5秒,确保两个线程执行完毕System.out.println("Map大小:" + map.size());//20万}
}public class AddMapDataThread extends Thread{@Overridepublic void run() {for(int i = 0 ; i < 1000000 ; i++ ){ConcurrentHashMapDemo.map.put("键:"+i , "值"+i);}}
}
并发死链
JDK1.7 的 HashMap 采用的头插法(拉链法)进行节点的添加,HashMap 的扩容长度为原来的 2 倍
resize() 中节点(Entry)转移的源代码:
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;//得到新数组的长度 // 遍历整个数组对应下标下的链表,e代表一个节点for (Entry e : table) { // 当e == null时,则该链表遍历完了,继续遍历下一数组下标的链表 while(null != e) { // 先把e节点的下一节点存起来Entry next = e.next; if (rehash) { //得到新的hash值e.hash = null == e.key ? 0 : hash(e.key); }// 在新数组下得到新的数组下标int i = indexFor(e.hash, newCapacity); // 将e的next指针指向新数组下标的位置e.next = newTable[i]; // 将该数组下标的节点变为e节点newTable[i] = e; // 遍历链表的下一节点e = next; }}
}
JDK 8 虽然将扩容算法做了调整,改用了尾插法,但仍不意味着能够在多线程环境下能够安全扩容,还会出现其它问题(如扩容丢数据)
B站视频解析:https://www.bilibili.com/video/BV1n541177Ea
成员属性
变量
-
存储数组:
transient volatile Node -
散列表的长度:
private static final int MAXIMUM_CAPACITY = 1 << 30; // 最大长度 private static final int DEFAULT_CAPACITY = 16; // 默认长度 -
并发级别,JDK7 遗留下来,1.8 中不代表并发级别:
private static final int DEFAULT_CONCURRENCY_LEVEL = 16; -
负载因子,JDK1.8 的 ConcurrentHashMap 中是固定值:
private static final float LOAD_FACTOR = 0.75f; -
阈值:
static final int TREEIFY_THRESHOLD = 8; // 链表树化的阈值 static final int UNTREEIFY_THRESHOLD = 6; // 红黑树转化为链表的阈值 static final int MIN_TREEIFY_CAPACITY = 64; // 当数组长度达到64且某个桶位中的链表长度超过8,才会真正树化 -
扩容相关:
private static final int MIN_TRANSFER_STRIDE = 16; // 线程迁移数据【最小步长】,控制线程迁移任务的最小区间 private static int RESIZE_STAMP_BITS = 16; // 用来计算扩容时生成的【标识戳】 private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;// 65535-1并发扩容最多线程数 private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; // 扩容时使用 -
节点哈希值:
static final int MOVED = -1; // 表示当前节点是 FWD 节点 static final int TREEBIN = -2; // 表示当前节点已经树化,且当前节点为 TreeBin 对象 static final int RESERVED = -3; // 表示节点时临时节点 static final int HASH_BITS = 0x7fffffff; // 正常节点的哈希值的可用的位数 -
扩容过程:volatile 修饰保证多线程的可见性
// 扩容过程中,会将扩容中的新 table 赋值给 nextTable 保持引用,扩容结束之后,这里会被设置为 null private transient volatile Node -
累加统计:
// LongAdder 中的 baseCount 未发生竞争时或者当前LongAdder处于加锁状态时,增量累到到 baseCount 中 private transient volatile long baseCount; // LongAdder 中的 cellsBuzy,0 表示当前 LongAdder 对象无锁状态,1 表示当前 LongAdder 对象加锁状态 private transient volatile int cellsBusy; // LongAdder 中的 cells 数组, private transient volatile CounterCell[] counterCells; -
控制变量:
sizeCtl < 0:
-
-1 表示当前 table 正在初始化(有线程在创建 table 数组),当前线程需要自旋等待
-
其他负数表示当前 map 的 table 数组正在进行扩容,高 16 位表示扩容的标识戳;低 16 位表示 (1 + nThread) 当前参与并发扩容的线程数量 + 1
sizeCtl = 0,表示创建 table 数组时使用 DEFAULT_CAPACITY 为数组大小
sizeCtl > 0:
- 如果 table 未初始化,表示初始化大小
- 如果 table 已经初始化,表示下次扩容时的触发条件(阈值,元素个数,不是数组的长度)
private transient volatile int sizeCtl; // volatile 保持可见性 -
内部类
-
Node 节点:
static class Node -
TreeBin 节点:
static final class TreeBin -
TreeNode 节点:
static final class TreeNode -
ForwardingNode 节点:转移节点
static final class ForwardingNode
代码块
-
变量:
// 表示sizeCtl属性在 ConcurrentHashMap 中内存偏移地址 private static final long SIZECTL; // 表示transferIndex属性在 ConcurrentHashMap 中内存偏移地址 private static final long TRANSFERINDEX; // 表示baseCount属性在 ConcurrentHashMap 中内存偏移地址 private static final long BASECOUNT; // 表示cellsBusy属性在 ConcurrentHashMap 中内存偏移地址 private static final long CELLSBUSY; // 表示cellValue属性在 CounterCell 中内存偏移地址 private static final long CELLVALUE; // 表示数组第一个元素的偏移地址 private static final long ABASE; // 用位移运算替代乘法 private static final int ASHIFT; -
赋值方法:
// 表示数组单元所占用空间大小,scale 表示 Node[] 数组中每一个单元所占用空间大小,int 是 4 字节 int scale = U.arrayIndexScale(ak); // 判断一个数是不是 2 的 n 次幂,比如 8:1000 & 0111 = 0000 if ((scale & (scale - 1)) != 0)throw new Error("data type scale not a power of two");// numberOfLeadingZeros(n):返回当前数值转换为二进制后,从高位到低位开始统计,看有多少个0连续在一起 // 8 → 1000 numberOfLeadingZeros(8) = 28 // 4 → 100 numberOfLeadingZeros(4) = 29 int 值就是占4个字节 ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);// ASHIFT = 31 - 29 = 2 ,int 的大小就是 2 的 2 次方,获取次方数 // ABASE + (5 << ASHIFT) 用位移运算替代了乘法,获取 arr[5] 的值
构造方法
-
无参构造, 散列表结构延迟初始化,默认的数组大小是 16:
public ConcurrentHashMap() { } -
有参构造:
public ConcurrentHashMap(int initialCapacity) {// 指定容量初始化if (initialCapacity < 0) throw new IllegalArgumentException();int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?MAXIMUM_CAPACITY :// 假如传入的参数是 16,16 + 8 + 1 ,最后得到 32// 传入 12, 12 + 6 + 1 = 19,最后得到 32,尽可能的大,与 HashMap不一样tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));// sizeCtl > 0,当目前 table 未初始化时,sizeCtl 表示初始化容量this.sizeCtl = cap; }private static final int tableSizeFor(int c) {int n = c - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }HashMap 部分详解了该函数,核心思想就是把最高位是 1 的位以及右边的位全部置 1,结果加 1 后就是 2 的 n 次幂
-
多个参数构造方法:
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();// 初始容量小于并发级别if (initialCapacity < concurrencyLevel) // 把并发级别赋值给初始容量initialCapacity = concurrencyLevel; // loadFactor 默认是 0.75long size = (long)(1.0 + (long)initialCapacity / loadFactor);int cap = (size >= (long)MAXIMUM_CAPACITY) ?MAXIMUM_CAPACITY : tableSizeFor((int)size);// sizeCtl > 0,当目前 table 未初始化时,sizeCtl 表示初始化容量this.sizeCtl = cap; } -
集合构造方法:
public ConcurrentHashMap(Map m) {this.sizeCtl = DEFAULT_CAPACITY; // 默认16putAll(m); } public void putAll(Map m) {// 尝试触发扩容tryPresize(m.size());for (Entry e : m.entrySet())putVal(e.getKey(), e.getValue(), false); }private final void tryPresize(int size) {// 扩容为大于 2 倍的最小的 2 的 n 次幂int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :tableSizeFor(size + (size >>> 1) + 1);int sc;while ((sc = sizeCtl) >= 0) {Node
成员方法
数据访存
-
tabAt():获取数组某个槽位的头节点,类似于数组中的直接寻址 arr[i]
// i 是数组索引 static final -
casTabAt():指定数组索引位置修改原值为指定的值
static final -
setTabAt():指定数组索引位置设置值
static final
添加方法
public V put(K key, V value) {// 第三个参数 onlyIfAbsent 为 false 表示哈希表中存在相同的 key 时【用当前数据覆盖旧数据】return putVal(key, value, false);
}
-
putVal()
final V putVal(K key, V value, boolean onlyIfAbsent) {// 【ConcurrentHashMap 不能存放 null 值】if (key == null || value == null) throw new NullPointerException();// 扰动运算,高低位都参与寻址运算int hash = spread(key.hashCode());// 表示当前 k-v 封装成 node 后插入到指定桶位后,在桶位中的所属链表的下标位置int binCount = 0;// tab 引用当前 map 的数组 table,开始自旋for (Node -
spread():扰动函数
将 hashCode 无符号右移 16 位,高 16bit 和低 16bit 做异或,最后与 HASH_BITS 相与变成正数,与树化节点和转移节点区分,把高低位都利用起来减少哈希冲突,保证散列的均匀性
static final int spread(int h) {return (h ^ (h >>> 16)) & HASH_BITS; // 0111 1111 1111 1111 1111 1111 1111 1111 } -
initTable():初始化数组,延迟初始化
private final Node -
treeifyBin():树化方法
private final void treeifyBin(Node -
addCount():添加计数,代表哈希表中的数据总量
private final void addCount(long x, int check) {// 【上面这部分的逻辑就是 LongAdder 的累加逻辑】CounterCell[] as; long b, s;// 判断累加数组 cells 是否初始化,没有就去累加 base 域,累加失败进入条件内逻辑if ((as = counterCells) != null ||!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {CounterCell a; long v; int m;// true 未竞争,false 发生竞争boolean uncontended = true;// 判断 cells 是否被其他线程初始化if (as == null || (m = as.length - 1) < 0 ||// 前面的条件为 fasle 说明 cells 被其他线程初始化,通过 hash 寻址对应的槽位(a = as[ThreadLocalRandom.getProbe() & m]) == null ||// 尝试去对应的槽位累加,累加失败进入 fullAddCount 进行重试或者扩容!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {// 与 Striped64#longAccumulate 方法相同fullAddCount(x, uncontended);return;}// 表示当前桶位是 null,或者一个链表节点if (check <= 1) return;// 【获取当前散列表元素个数】,这是一个期望值s = sumCount();}// 表示一定 【是一个 put 操作调用的 addCount】if (check >= 0) {Node -
resizeStamp():扩容标识符,每次扩容都会产生一个,不是每个线程都产生,16 扩容到 32 产生一个,32 扩容到 64 产生一个
/*** 扩容的标识符* 16 -> 32 从16扩容到32* numberOfLeadingZeros(16) => 1 0000 => 32 - 5 = 27 => 0000 0000 0001 1011* (1 << (RESIZE_STAMP_BITS - 1)) => 1000 0000 0000 0000 => 32768* ---------------------------------------------------------------* 0000 0000 0001 1011* 1000 0000 0000 0000* 1000 0000 0001 1011* 永远是负数*/ static final int resizeStamp(int n) {// 或运算return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1)); // (16 -1 = 15) }
扩容方法
扩容机制:
- 当链表中元素个数超过 8 个,数组的大小还未超过 64 时,此时进行数组的扩容,如果超过则将链表转化成红黑树
- put 数据后调用 addCount() 方法,判断当前哈希表的容量超过阈值 sizeCtl,超过进行扩容
- 增删改线程发现其他线程正在扩容,帮其扩容
常见方法:
-
transfer():数据转移到新表中,完成扩容
private final void transfer(Node链表处理的 LastRun 机制,可以减少节点的创建
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b29a8U3O-1679358011071)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentHashMap-LastRun机制.png)]
-
helpTransfer():帮助扩容机制
final Node
获取方法
ConcurrentHashMap 使用 get() 方法获取指定 key 的数据
-
get():获取指定数据的方法
public V get(Object key) {Node -
ForwardingNode#find:转移节点的查找方法
Node
删除方法
-
remove():删除指定元素
public V remove(Object key) {return replaceNode(key, null, null); } -
replaceNode():替代指定的元素,会协助扩容,增删改(写)都会协助扩容,查询(读)操作不会,因为读操作不涉及加锁
final V replaceNode(Object key, V value, Object cv) {// 计算 key 扰动运算后的 hashint hash = spread(key.hashCode());// 开始自旋for (Node
参考视频:https://space.bilibili.com/457326371/
JDK7原理
ConcurrentHashMap 对锁粒度进行了优化,分段锁技术,将整张表分成了多个数组(Segment),每个数组又是一个类似 HashMap 数组的结构。允许多个修改操作并发进行,Segment 是一种可重入锁,继承 ReentrantLock,并发时锁住的是每个 Segment,其他 Segment 还是可以操作的,这样不同 Segment 之间就可以实现并发,大大提高效率。
底层结构: Segment 数组 + HashEntry 数组 + 链表(数组 + 链表是 HashMap 的结构)
-
优点:如果多个线程访问不同的 segment,实际是没有冲突的,这与 JDK8 中是类似的
-
缺点:Segments 数组默认大小为16,这个容量初始化指定后就不能改变了,并且不是懒惰初始化
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xsLgOtDd-1679358011071)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentHashMap 1.7底层结构.png)]
CopyOnWrite
原理分析
CopyOnWriteArrayList 采用了写入时拷贝的思想,增删改操作会将底层数组拷贝一份,在新数组上执行操作,不影响其它线程的并发读,读写分离
CopyOnWriteArraySet 底层对 CopyOnWriteArrayList 进行了包装,装饰器模式
public CopyOnWriteArraySet() {al = new CopyOnWriteArrayList();
}
-
存储结构:
private transient volatile Object[] array; // volatile 保证了读写线程之间的可见性 -
全局锁:保证线程的执行安全
final transient ReentrantLock lock = new ReentrantLock(); -
新增数据:需要加锁,创建新的数组操作
public boolean add(E e) {final ReentrantLock lock = this.lock;// 加锁,保证线程安全lock.lock();try {// 获取旧的数组Object[] elements = getArray();int len = elements.length;// 【拷贝新的数组(这里是比较耗时的操作,但不影响其它读线程)】Object[] newElements = Arrays.copyOf(elements, len + 1);// 添加新元素newElements[len] = e;// 替换旧的数组,【这个操作以后,其他线程获取数组就是获取的新数组了】setArray(newElements);return true;} finally {lock.unlock();} } -
读操作:不加锁,在原数组上操作
public E get(int index) {return get(getArray(), index); } private E get(Object[] a, int index) {return (E) a[index]; }适合读多写少的应用场景
-
迭代器:CopyOnWriteArrayList 在返回迭代器时,创建一个内部数组当前的快照(引用),即使其他线程替换了原始数组,迭代器遍历的快照依然引用的是创建快照时的数组,所以这种实现方式也存在一定的数据延迟性,对其他线程并行添加的数据不可见
public Iteratoriterator() {// 获取到数组引用,整个遍历的过程该数组都不会变,一直引用的都是老数组,return new COWIterator (getArray(), 0); }// 迭代器会创建一个底层array的快照,故主类的修改不影响该快照 static final class COWIterator implements ListIterator {// 内部数组快照private final Object[] snapshot;private COWIterator(Object[] elements, int initialCursor) {cursor = initialCursor;// 数组的引用在迭代过程不会改变snapshot = elements;}// 【不支持写操作】,因为是在快照上操作,无法同步回去public void remove() {throw new UnsupportedOperationException();} }
弱一致性
数据一致性就是读到最新更新的数据:
-
强一致性:当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值
-
弱一致性:系统并不保证进程或者线程的访问都会返回最新的更新过的值,也不会承诺多久之后可以读到
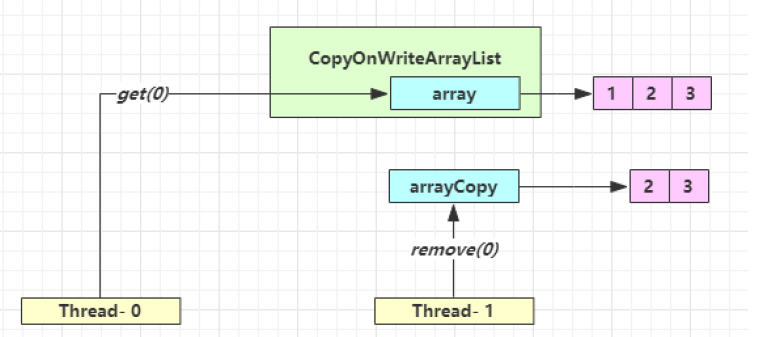
| 时间点 | 操作 |
|---|---|
| 1 | Thread-0 getArray() |
| 2 | Thread-1 getArray() |
| 3 | Thread-1 setArray(arrayCopy) |
| 4 | Thread-0 array[index] |
Thread-0 读到了脏数据
不一定弱一致性就不好
- 数据库的事务隔离级别就是弱一致性的表现
- 并发高和一致性是矛盾的,需要权衡
安全失败
在 java.util 包的集合类就都是快速失败的,而 java.util.concurrent 包下的类都是安全失败
-
快速失败:在 A 线程使用迭代器对集合进行遍历的过程中,此时 B 线程对集合进行修改(增删改),或者 A 线程在遍历过程中对集合进行修改,都会导致 A 线程抛出 ConcurrentModificationException 异常
- AbstractList 类中的成员变量 modCount,用来记录 List 结构发生变化的次数,结构发生变化是指添加或者删除至少一个元素的操作,或者是调整内部数组的大小,仅仅设置元素的值不算结构发生变化
- 在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了抛出 CME 异常
-
安全失败:采用安全失败机制的集合容器,在迭代器遍历时直接在原集合数组内容上访问,但其他线程的增删改都会新建数组进行修改,就算修改了集合底层的数组容器,迭代器依然引用着以前的数组(快照思想),所以不会出现异常
ConcurrentHashMap 不会出现并发时的迭代异常,因为在迭代过程中 CHM 的迭代器并没有判断结构的变化,迭代器还可以根据迭代的节点状态去寻找并发扩容时的新表进行迭代
ConcurrentHashMap map = new ConcurrentHashMap(); // KeyIterator Iterator iterator = map.keySet().iterator();Traverser(Nodepublic final boolean hasNext() { return next != null; } public final K next() {Node
Collections
Collections类是用来操作集合的工具类,提供了集合转换成线程安全的方法:
public static Collection synchronizedCollection(Collection c) {return new SynchronizedCollection<>(c);}
public static Map synchronizedMap(Map m) {return new SynchronizedMap<>(m);
}
源码:底层也是对方法进行加锁
public boolean add(E e) {synchronized (mutex) {return c.add(e);}
}
SkipListMap
底层结构
跳表 SkipList 是一个有序的链表,默认升序,底层是链表加多级索引的结构。跳表可以对元素进行快速查询,类似于平衡树,是一种利用空间换时间的算法
对于单链表,即使链表是有序的,如果查找数据也只能从头到尾遍历链表,所以采用链表上建索引的方式提高效率,跳表的查询时间复杂度是 O(logn),空间复杂度 O(n)
ConcurrentSkipListMap 提供了一种线程安全的并发访问的排序映射表,内部是跳表结构实现,通过 CAS + volatile 保证线程安全
平衡树和跳表的区别:
- 对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整;而对跳表的插入和删除,只需要对整个结构的局部进行操作
- 在高并发的情况下,保证整个平衡树的线程安全需要一个全局锁;对于跳表则只需要部分锁,拥有更好的性能
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4Z7EUMki-1679358011071)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentSkipListMap数据结构.png)]
BaseHeader 存储数据,headIndex 存储索引,纵向上所有索引都指向链表最下面的节点
成员变量
-
标识索引头节点位置
private static final Object BASE_HEADER = new Object(); -
跳表的顶层索引
private transient volatile HeadIndex -
比较器,为 null 则使用自然排序
final Comparator comparator; -
Node 节点
static final class Node -
索引节点 Index,只有向下和向右的指针
static class Index -
头索引节点 HeadIndex
static final class HeadIndex
成员方法
其他方法
-
构造方法:
public ConcurrentSkipListMap() {this.comparator = null; // comparator 为 null,使用 key 的自然序,如字典序initialize(); }private void initialize() {keySet = null;entrySet = null;values = null;descendingMap = null;// 初始化索引头节点,Node 的 key 为 null,value 为 BASE_HEADER 对象,下一个节点为 null// head 的分层索引 down 为 null,链表的后续索引 right 为 null,层级 level 为第 1 层head = new HeadIndex -
cpr:排序
// x 是比较者,y 是被比较者,比较者大于被比较者 返回正数,小于返回负数,相等返回 0 static final int cpr(Comparator c, Object x, Object y) {return (c != null) ? c.compare(x, y) : ((Comparable)x).compareTo(y); }
添加方法
-
findPredecessor():寻找前置节点
从最上层的头索引开始向右查找(链表的后续索引),如果后续索引的节点的 key 大于要查找的 key,则头索引移到下层链表,在下层链表查找,以此反复,一直查找到没有下层的分层索引为止,返回该索引的节点。如果后续索引的节点的 key 小于要查找的 key,则在该层链表中向后查找。由于查找的 key 可能永远大于索引节点的 key,所以只能找到目标的前置索引节点。如果遇到空值索引的存在,通过 CAS 来断开索引
private Node[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bQWNr2xu-1679358011072)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentSkipListMap-Put流程.png)]
-
put():添加数据
public V put(K key, V value) {// 非空判断,value不能为空if (value == null)throw new NullPointerException();return doPut(key, value, false); }private V doPut(K key, V value, boolean onlyIfAbsent) {Node -
findNode()
private Node
获取方法
-
get(key):获取对应的数据
public V get(Object key) {return doGet(key); } -
doGet():扫描过程会对已 value = null 的元素进行删除处理
private V doGet(Object key) {if (key == null)throw new NullPointerException();Comparator cmp = comparator;outer: for (;;) {// 1.找到最底层节点的前置节点for (Node
删除方法
-
remove()
public V remove(Object key) {return doRemove(key, null); } final V doRemove(Object key, Object value) {if (key == null)throw new NullPointerException();Comparator cmp = comparator;outer: for (;;) {// 1.找到最底层目标节点的前置节点,b.key < keyfor (Node经过 findPredecessor() 中的 unlink() 后索引已经被删除
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FgCumuWk-1679358011072)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentSkipListMap-remove流程.png)]
-
appendMarker():添加删除标记节点
boolean appendMarker(Node -
helpDelete():将添加了删除标记的节点清除,参数是该节点的前驱和后继节点
void helpDelete(Node -
tryReduceLevel():删除索引
private void tryReduceLevel() {HeadIndex
参考文章:https://my.oschina.net/u/3768341/blog/3135659
参考视频:https://www.bilibili.com/video/BV1Er4y1P7k1
NoBlocking
非阻塞队列
并发编程中,需要用到安全的队列,实现安全队列可以使用 2 种方式:
- 加锁,这种实现方式是阻塞队列
- 使用循环 CAS 算法实现,这种方式是非阻塞队列
ConcurrentLinkedQueue 是一个基于链接节点的无界线程安全队列,采用先进先出的规则对节点进行排序,当添加一个元素时,会添加到队列的尾部,当获取一个元素时,会返回队列头部的元素
补充:ConcurrentLinkedDeque 是双向链表结构的无界并发队列
ConcurrentLinkedQueue 使用约定:
- 不允许 null 入列
- 队列中所有未删除的节点的 item 都不能为 null 且都能从 head 节点遍历到
- 删除节点是将 item 设置为 null,队列迭代时跳过 item 为 null 节点
- head 节点跟 tail 不一定指向头节点或尾节点,可能存在滞后性
ConcurrentLinkedQueue 由 head 节点和 tail 节点组成,每个节点由节点元素和指向下一个节点的引用组成,组成一张链表结构的队列
private transient volatile Node head;
private transient volatile Node tail;private static class Node {volatile E item;volatile Node next;//.....
}
构造方法
-
无参构造方法:
public ConcurrentLinkedQueue() {// 默认情况下 head 节点存储的元素为空,dummy 节点,tail 节点等于 head 节点head = tail = new Node(null); } -
有参构造方法
public ConcurrentLinkedQueue(Collection c) {Nodeh = null, t = null;// 遍历节点for (E e : c) {checkNotNull(e);Node newNode = new Node (e);if (h == null)h = t = newNode;else {// 单向链表t.lazySetNext(newNode);t = newNode;}}if (h == null)h = t = new Node (null);head = h;tail = t; }
入队方法
与传统的链表不同,单线程入队的工作流程:
- 将入队节点设置成当前队列尾节点的下一个节点
- 更新 tail 节点,如果 tail 节点的 next 节点不为空,则将入队节点设置成 tail 节点;如果 tail 节点的 next 节点为空,则将入队节点设置成 tail 的 next 节点,所以 tail 节点不总是尾节点,存在滞后性
public boolean offer(E e) {checkNotNull(e);// 创建入队节点final Node newNode = new Node(e);// 循环 CAS 直到入队成功for (Node t = tail, p = t;;) {// p 用来表示队列的尾节点,初始情况下等于 tail 节点,q 是 p 的 next 节点Node q = p.next;// 条件成立说明 p 是尾节点if (q == null) {// p 是尾节点,设置 p 节点的下一个节点为新节点// 设置成功则 casNext 返回 true,否则返回 false,说明有其他线程更新过尾节点,继续寻找尾节点,继续 CASif (p.casNext(null, newNode)) {// 首次添加时,p 等于 t,不进行尾节点更新,所以尾节点存在滞后性if (p != t)// 将 tail 设置成新入队的节点,设置失败表示其他线程更新了 tail 节点casTail(t, newNode); return true;}}else if (p == q)// 当 tail 不指向最后节点时,如果执行出列操作,可能将 tail 也移除,tail 不在链表中 // 此时需要对 tail 节点进行复位,复位到 head 节点p = (t != (t = tail)) ? t : head;else// 推动 tail 尾节点往队尾移动p = (p != t && t != (t = tail)) ? t : q;}
}
图解入队:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s3BCBprE-1679358011072)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentLinkedQueue入队操作1.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nrFcGdEF-1679358011072)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentLinkedQueue入队操作2.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ucll35Wx-1679358011073)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentLinkedQueue入队操作3.png)]
当 tail 节点和尾节点的距离大于等于 1 时(每入队两次)更新 tail,可以减少 CAS 更新 tail 节点的次数,提高入队效率
线程安全问题:
- 线程 1 线程 2 同时入队,无论从哪个位置开始并发入队,都可以循环 CAS,直到入队成功,线程安全
- 线程 1 遍历,线程 2 入队,所以造成 ConcurrentLinkedQueue 的 size 是变化,需要加锁保证安全
- 线程 1 线程 2 同时出列,线程也是安全的
出队方法
出队列的就是从队列里返回一个节点元素,并清空该节点对元素的引用,并不是每次出队都更新 head 节点
- 当 head 节点里有元素时,直接弹出 head 节点里的元素,而不会更新 head 节点
- 当 head 节点里没有元素时,出队操作才会更新 head 节点
批处理方式可以减少使用 CAS 更新 head 节点的消耗,从而提高出队效率
public E poll() {restartFromHead:for (;;) {// p 节点表示首节点,即需要出队的节点,FIFOfor (Node h = head, p = h, q;;) {E item = p.item;// 如果 p 节点的元素不为 null,则通过 CAS 来设置 p 节点引用元素为 null,成功返回 itemif (item != null && p.casItem(item, null)) {if (p != h) // 对 head 进行移动updateHead(h, ((q = p.next) != null) ? q : p);return item;}// 逻辑到这说明头节点的元素为空或头节点发生了变化,头节点被另外一个线程修改了// 那么获取 p 节点的下一个节点,如果 p 节点的下一节点也为 null,则表明队列已经空了else if ((q = p.next) == null) {updateHead(h, p);return null;}// 第一轮操作失败,下一轮继续,调回到循环前else if (p == q)continue restartFromHead;// 如果下一个元素不为空,则将头节点的下一个节点设置成头节点elsep = q;}}
}
final void updateHead(Node h, Node p) {if (h != p && casHead(h, p))// 将旧结点 h 的 next 域指向为 h,help gch.lazySetNext(h);
}
在更新完 head 之后,会将旧的头结点 h 的 next 域指向为 h,图中所示的虚线也就表示这个节点的自引用,被移动的节点(item 为 null 的节点)会被 GC 回收
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r37o0vP9-1679358011073)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentLinkedQueue出队操作1.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wFhxw8y7-1679358011073)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentLinkedQueue出队操作2.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gHCFnEI5-1679358011073)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/JUC-ConcurrentLinkedQueue出队操作3.png)]
如果这时,有一个线程来添加元素,通过 tail 获取的 next 节点则仍然是它本身,这就出现了p == q 的情况,出现该种情况之后,则会触发执行 head 的更新,将 p 节点重新指向为 head
参考文章:https://www.jianshu.com/p/231caf90f30b
成员方法
-
peek():会改变 head 指向,执行 peek() 方法后 head 会指向第一个具有非空元素的节点
// 获取链表的首部元素,只读取而不移除 public E peek() {restartFromHead:for (;;) {for (Nodeh = head, p = h, q;;) {E item = p.item;if (item != null || (q = p.next) == null) {// 更改h的位置为非空元素节点updateHead(h, p);return item;}else if (p == q)continue restartFromHead;elsep = q;}} } -
size():用来获取当前队列的元素个数,因为整个过程都没有加锁,在并发环境中从调用 size 方法到返回结果期间有可能增删元素,导致统计的元素个数不精确
public int size() {int count = 0;// first() 获取第一个具有非空元素的节点,若不存在,返回 null// succ(p) 方法获取 p 的后继节点,若 p == p.next,则返回 head// 类似遍历链表for (Nodep = first(); p != null; p = succ(p))if (p.item != null)// 最大返回Integer.MAX_VALUEif (++count == Integer.MAX_VALUE)break;return count; } -
remove():移除元素
public boolean remove(Object o) {// 删除的元素不能为nullif (o != null) {Nodenext, pred = null;for (Node p = first(); p != null; pred = p, p = next) {boolean removed = false;E item = p.item;// 节点元素不为nullif (item != null) {// 若不匹配,则获取next节点继续匹配if (!o.equals(item)) {next = succ(p);continue;}// 若匹配,则通过 CAS 操作将对应节点元素置为 nullremoved = p.casItem(item, null);}// 获取删除节点的后继节点next = succ(p);// 将被删除的节点移除队列if (pred != null && next != null) // unlinkpred.casNext(p, next);if (removed)return true;}}return false; }
NET
DES
网络编程
网络编程,就是在一定的协议下,实现两台计算机的通信的技术
通信一定是基于软件结构实现的:
- C/S 结构 :全称为 Client/Server 结构,是指客户端和服务器结构,常见程序有 QQ、IDEA 等软件
- B/S 结构 :全称为 Browser/Server 结构,是指浏览器和服务器结构
两种架构各有优势,但是无论哪种架构,都离不开网络的支持
网络通信的三要素:
-
协议:计算机网络客户端与服务端通信必须约定和彼此遵守的通信规则,HTTP、FTP、TCP、UDP、SMTP
-
IP 地址:互联网协议地址(Internet Protocol Address),用来给一个网络中的计算机设备做唯一的编号
-
IPv4:4 个字节,32 位组成,192.168.1.1
-
IPv6:可以实现为所有设备分配 IP,128 位
-
ipconfig:查看本机的 IP
- ping 检查本机与某个 IP 指定的机器是否联通,或者说是检测对方是否在线。
- ping 空格 IP地址 :ping 220.181.57.216,ping www.baidu.com
特殊的IP地址: 本机IP地址,127.0.0.1 == localhost,回环测试
-
-
端口:端口号就可以唯一标识设备中的进程(应用程序)。端口号是用两个字节表示的整数,取值范围是 0-65535,0-1023 之间的端口号用于一些知名的网络服务和应用普通的应用程序需要使用 1024 以上的端口号。如果端口号被另外一个服务或应用所占用,会导致当前程序启动失败,报出端口被占用异常
利用协议+IP 地址+端口号三元组合,就可以标识网络中的进程了,那么进程间的通信就可以利用这个标识与其它进程进行交互
参考视频:https://www.bilibili.com/video/BV1kT4y1M7vt
通信协议
网络通信协议:对计算机必须遵守的规则,只有遵守这些规则,计算机之间才能进行通信
通信是进程与进程之间的通信,不是主机与主机之间的通信
TCP/IP协议:传输控制协议 (Transmission Control Protocol)
传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流,每一条 TCP 连接只能是点对点的(一对一)
- 在通信之前必须确定对方在线并且连接成功才可以通信
- 例如下载文件、浏览网页等(要求可靠传输)
用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,不可靠,没有拥塞控制,面向报文,支持一对一、一对多、多对一和多对多的交互通信
- 直接发消息给对方,不管对方是否在线,发消息后也不需要确认
- 无线(视频会议,通话),性能好,可能丢失一些数据
Java模型
相关概念:
- 同步:当前线程要自己进行数据的读写操作(自己去银行取钱)
- 异步:当前线程可以去做其他事情(委托别人拿银行卡到银行取钱,然后给你)
- 阻塞:在数据没有的情况下,还是要继续等待着读(排队等待)
- 非阻塞:在数据没有的情况下,会去做其他事情,一旦有了数据再来获取(柜台取款,取个号,然后坐在椅子上做其它事,等号广播会通知你办理)
Java 中的通信模型:
-
BIO 表示同步阻塞式通信,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,可以通过线程池机制改善
同步阻塞式性能极差:大量线程,大量阻塞
-
伪异步通信:引入线程池,不需要一个客户端一个线程,实现线程复用来处理很多个客户端,线程可控
高并发下性能还是很差:线程数量少,数据依然是阻塞的,数据没有来线程还是要等待
-
NIO 表示同步非阻塞 IO,服务器实现模式为请求对应一个线程,客户端发送的连接会注册到多路复用器上,多路复用器轮询到连接有 I/O 请求时才启动一个线程进行处理
工作原理:1 个主线程专门负责接收客户端,1 个线程轮询所有的客户端,发来了数据才会开启线程处理
同步:线程还要不断的接收客户端连接,以及处理数据
非阻塞:如果一个管道没有数据,不需要等待,可以轮询下一个管道是否有数据
-
AIO 表示异步非阻塞 IO,AIO 引入异步通道的概念,采用了 Proactor 模式,有效的请求才启动线程,特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用
异步:服务端线程接收到了客户端管道以后就交给底层处理 IO 通信,线程可以做其他事情
非阻塞:底层也是客户端有数据才会处理,有了数据以后处理好通知服务器应用来启动线程进行处理
各种模型应用场景:
- BIO 适用于连接数目比较小且固定的架构,该方式对服务器资源要求比较高,并发局限于应用中,程序简单
- NIO 适用于连接数目多且连接比较短(轻操作)的架构,如聊天服务器,并发局限于应用中,编程复杂,JDK 1.4 开始支持
- AIO 适用于连接数目多且连接比较长(重操作)的架构,如相册服务器,充分调用操作系统参与并发操作,JDK 1.7 开始支持
I/O
IO模型
五种模型
对于一个套接字上的输入操作,第一步是等待数据从网络中到达,当数据到达时被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区
Linux 有五种 I/O 模型:
- 阻塞式 I/O
- 非阻塞式 I/O
- I/O 复用(select 和 poll)
- 信号驱动式 I/O(SIGIO)
- 异步 I/O(AIO)
五种模型对比:
- 同步 I/O 包括阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O ,它们的主要区别在第一个阶段,非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞
- 同步 I/O:将数据从内核缓冲区复制到应用进程缓冲区的阶段(第二阶段),应用进程会阻塞
- 异步 I/O:第二阶段应用进程不会阻塞
阻塞式IO
应用进程通过系统调用 recvfrom 接收数据,会被阻塞,直到数据从内核缓冲区复制到应用进程缓冲区中才返回。阻塞不意味着整个操作系统都被阻塞,其它应用进程还可以执行,只是当前阻塞进程不消耗 CPU 时间,这种模型的 CPU 利用率会比较高
recvfrom() 用于接收 Socket 传来的数据,并复制到应用进程的缓冲区 buf 中,把 recvfrom() 当成系统调用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SoQtwB5q-1679358011073)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO模型-阻塞式IO.png)]
非阻塞式
应用进程通过 recvfrom 调用不停的去和内核交互,直到内核准备好数据。如果没有准备好数据,内核返回一个错误码,过一段时间应用进程再执行 recvfrom 系统调用,在两次发送请求的时间段,进程可以进行其他任务,这种方式称为轮询(polling)
由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BAgkxUBb-1679358011074)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO模型-非阻塞式IO.png)]
信号驱动
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,等待数据阶段应用进程是非阻塞的。当内核数据准备就绪时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CsSGRvyu-1679358011074)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO模型-信号驱动IO.png)]
IO 复用
IO 复用模型使用 select 或者 poll 函数等待数据,select 会监听所有注册好的 IO,等待多个套接字中的任何一个变为可读,等待过程会被阻塞,当某个套接字准备好数据变为可读时 select 调用就返回,然后调用 recvfrom 把数据从内核复制到进程中
IO 复用让单个进程具有处理多个 I/O 事件的能力,又被称为 Event Driven I/O,即事件驱动 I/O
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都要创建一个线程去处理,如果同时有几万个连接,就需要创建相同数量的线程。相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dhFbKkRZ-1679358011074)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO模型-IO复用模型.png)]
异步 IO
应用进程执行 aio_read 系统调用会立即返回,给内核传递描述符、缓冲区指针、缓冲区大小等。应用进程可以继续执行不会被阻塞,内核会在所有操作完成之后向应用进程发送信号
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uhNYBPQc-1679358011074)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO模型-异步IO模型.png)]
多路复用
select
函数
Socket 不是文件,只是一个标识符,但是 Unix 操作系统把所有东西都看作是文件,所以 Socket 说成 file descriptor,也就是 fd
select 允许应用程序监视一组文件描述符,等待一个或者多个描述符成为就绪状态,从而完成 I/O 操作。
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
-
fd_set 使用 bitmap 数组实现,数组大小用 FD_SETSIZE 定义,单进程只能监听少于 FD_SETSIZE 数量的描述符,32 位机默认是 1024 个,64 位机默认是 2048,可以对进行修改,然后重新编译内核
-
fd_set 有三种类型的描述符:readset、writeset、exceptset,对应读、写、异常条件的描述符集合
-
n 是监测的 socket 的最大数量
-
timeout 为超时参数,调用 select 会一直阻塞直到有描述符的事件到达或者等待的时间超过 timeout
struct timeval{long tv_sec; //秒long tv_usec; //微秒 }- timeout == null:等待无限长的时间
- tv_sec == 0 && tv_usec == 0:获取后直接返回,不阻塞等待
- tv_sec != 0 || tv_usec != 0:等待指定时间
-
方法成功调用返回结果为就绪的文件描述符个数,出错返回结果为 -1,超时返回结果为 0
Linux 提供了一组宏为 fd_set 进行赋值操作:
int FD_ZERO(fd_set *fdset); // 将一个 fd_set 类型变量的所有值都置为 0
int FD_CLR(int fd, fd_set *fdset); // 将一个 fd_set 类型变量的 fd 位置为 0
int FD_SET(int fd, fd_set *fdset); // 将一个 fd_set 类型变量的 fd 位置为 1
int FD_ISSET(int fd, fd_set *fdset);// 判断 fd 位是否被置为 1
示例:
sockfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&addr, 0, sizeof(addr)));
addr.sin_family = AF_INET;
addr.sin_port = htons(2000);
addr.sin_addr.s_addr = INADDR_ANY;
bind(sockfd, (struct sockaddr*)&addr, sizeof(addr));//绑定连接
listen(sockfd, 5);//监听5个端口
for(i = 0; i < 5; i++) {memset(&client, e, sizeof(client));addrlen = sizeof(client);fds[i] = accept(sockfd, (struct sockaddr*)&client, &addrlen);//将监听的对应的文件描述符fd存入fds:[3,4,5,6,7]if(fds[i] > max)max = fds[i];
}
while(1) {FD_ZERO(&rset);//置为0for(i = 0; i < 5; i++) {FD_SET(fds[i], &rset);//对应位置1 [0001 1111 00.....]}print("round again");select(max + 1, &rset, NULL, NULL, NULL);//监听for(i = 0; i <5; i++) {if(FD_ISSET(fds[i], &rset)) {//判断监听哪一个端口memset(buffer, 0, MAXBUF);read(fds[i], buffer, MAXBUF);//进入内核态读数据print(buffer);}}
}
参考视频:https://www.bilibili.com/video/BV19D4y1o797
流程
select 调用流程图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lzgoQYW2-1679358011074)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO-select调用过程.png)]
- 使用 copy_from_user 从用户空间拷贝 fd_set 到内核空间,进程阻塞
- 注册回调函数 _pollwait
- 遍历所有 fd,调用其对应的 poll 方法判断当前请求是否准备就绪,对于 socket,这个 poll 方法是 sock_poll,sock_poll 根据情况会调用到 tcp_poll、udp_poll 或者 datagram_poll,以 tcp_poll 为例,其核心实现就是 _pollwait
- _pollwait 把 **current(调用 select 的进程)**挂到设备的等待队列,不同设备有不同的等待队列,对于 tcp_poll ,其等待队列是 sk → sk_sleep(把进程挂到等待队列中并不代表进程已经睡眠),在设备收到消息(网络设备)或填写完文件数据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时 current 便被唤醒,进入就绪队列
- poll 方法返回时会返回一个描述读写操作是否就绪的 mask 掩码,根据这个 mask 掩码给 fd_set 赋值
- 如果遍历完所有的 fd,还没有返回一个可读写的 mask 掩码,则会调用 schedule_timeout 让 current 进程进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程,如果超过一定的超时时间(schedule_timeout)没有其他线程唤醒,则调用 select 的进程会重新被唤醒获得 CPU,进而重新遍历 fd,判断有没有就绪的 fd
- 把 fd_set 从内核空间拷贝到用户空间,阻塞进程继续执行
参考文章:https://www.cnblogs.com/anker/p/3265058.html
其他流程图:https://www.processon.com/view/link/5f62b9a6e401fd2ad7e5d6d1
poll
poll 的功能与 select 类似,也是等待一组描述符中的一个成为就绪状态
int poll(struct pollfd *fds, unsigned int nfds, int timeout);
poll 中的描述符是 pollfd 类型的数组,pollfd 的定义如下:
struct pollfd {int fd; /* file descriptor */short events; /* requested events */short revents; /* returned events */
};
select 和 poll 对比:
- select 会修改描述符,而 poll 不会
- select 的描述符类型使用数组实现,有描述符的限制;而 poll 使用链表实现,没有描述符数量的限制
- poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高
- select 和 poll 速度都比较慢,每次调用都需要将全部描述符数组 fd 从应用进程缓冲区复制到内核缓冲区,同时每次都需要在内核遍历传递进来的所有 fd ,这个开销在 fd 很多时会很大
- 几乎所有的系统都支持 select,但是只有比较新的系统支持 poll
- select 和 poll 的时间复杂度 O(n),对 socket 进行扫描时是线性扫描,即采用轮询的方法,效率较低,因为并不知道具体是哪个 socket 具有事件,所以随着 fd 数量的增加会造成遍历速度慢的线性下降性能问题
- poll 还有一个特点是水平触发,如果报告了 fd 后,没有被处理,那么下次 poll 时会再次报告该 fd
- 如果一个线程对某个描述符调用了 select 或者 poll,另一个线程关闭了该描述符,会导致调用结果不确定
参考文章:https://github.com/CyC2018/CS-Notes/blob/master/notes/Socket.md
epoll
函数
epoll 使用事件的就绪通知方式,通过 epoll_ctl() 向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,一旦该 fd 就绪,内核通过 callback 回调函数将 I/O 准备好的描述符加入到一个链表中管理,进程调用 epoll_wait() 便可以得到事件就绪的描述符
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
-
epall_create:一个系统函数,函数将在内核空间内创建一个 epoll 数据结构,可以理解为 epoll 结构空间,返回值为 epoll 的文件描述符编号,以后有 client 连接时,向该 epoll 结构中添加监听,所以 epoll 使用一个文件描述符管理多个描述符
-
epall_ctl:epoll 的事件注册函数,select 函数是调用时指定需要监听的描述符和事件,epoll 先将用户感兴趣的描述符事件注册到 epoll 空间。此函数是非阻塞函数,用来增删改 epoll 空间内的描述符,参数解释:
-
epfd:epoll 结构的进程 fd 编号,函数将依靠该编号找到对应的 epoll 结构
-
op:表示当前请求类型,有三个宏定义:
- EPOLL_CTL_ADD:注册新的 fd 到 epfd 中
- EPOLL_CTL_MOD:修改已经注册的 fd 的监听事件
- EPOLL_CTI_DEL:从 epfd 中删除一个 fd
-
fd:需要监听的文件描述符,一般指 socket_fd
-
event:告诉内核对该 fd 资源感兴趣的事件,epoll_event 的结构:
struct epoll_event {_uint32_t events; /*epoll events*/epoll_data_t data; /*user data variable*/ }events 可以是以下几个宏集合:EPOLLIN、EPOLOUT、EPOLLPRI、EPOLLERR、EPOLLHUP(挂断)、EPOLET(边缘触发)、EPOLLONESHOT(只监听一次,事件触发后自动清除该 fd,从 epoll 列表)
-
-
epoll_wait:等待事件的产生,类似于 select() 调用,返回值为本次就绪的 fd 个数,直接从就绪链表获取,时间复杂度 O(1)
- epfd:指定感兴趣的 epoll 事件列表
- events:指向一个 epoll_event 结构数组,当函数返回时,内核会把就绪状态的数据拷贝到该数组
- maxevents:标明 epoll_event 数组最多能接收的数据量,即本次操作最多能获取多少就绪数据
- timeout:单位为毫秒
- 0:表示立即返回,非阻塞调用
- -1:阻塞调用,直到有用户感兴趣的事件就绪为止
- 大于 0:阻塞调用,阻塞指定时间内如果有事件就绪则提前返回,否则等待指定时间后返回
epoll 的描述符事件有两种触发模式:LT(level trigger)和 ET(edge trigger):
- LT 模式:当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程,是默认的一种模式,并且同时支持 Blocking 和 No-Blocking
- ET 模式:通知之后进程必须立即处理事件,下次再调用 epoll_wait() 时不会再得到事件到达的通知。减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高;只支持 No-Blocking,以避免由于一个 fd 的阻塞读/阻塞写操作把处理多个文件描述符的任务饥饿
// 创建 epoll 描述符,每个应用程序只需要一个,用于监控所有套接字
int pollingfd = epoll_create(0xCAFE);
if ( pollingfd < 0 )// report error
// 初始化 epoll 结构
struct epoll_event ev = { 0 };// 将连接类实例与事件相关联,可以关联任何想要的东西
ev.data.ptr = pConnection1;// 监视输入,并且在事件发生后不自动重新准备描述符
ev.events = EPOLLIN | EPOLLONESHOT;
// 将描述符添加到监控列表中,即使另一个线程在epoll_wait中等待,描述符将被正确添加
if ( epoll_ctl( epollfd, EPOLL_CTL_ADD, pConnection1->getSocket(), &ev) != 0 )// report error// 最多等待 20 个事件
struct epoll_event pevents[20];// 等待10秒,检索20个并存入epoll_event数组
int ready = epoll_wait(pollingfd, pevents, 20, 10000);
// 检查epoll是否成功
if ( ret == -1)// report error and abort
else if ( ret == 0)// timeout; no event detected
else
{for (int i = 0; i < ready; i+ ){if ( pevents[i].events & EPOLLIN ){// 获取连接指针Connection * c = (Connection*) pevents[i].data.ptr;c->handleReadEvent();}}
}
流程图:https://gitee.com/seazean/images/blob/master/Java/IO-epoll%E5%8E%9F%E7%90%86%E5%9B%BE.jpg
参考视频:https://www.bilibili.com/video/BV19D4y1o797
特点
epoll 的特点:
-
epoll 仅适用于 Linux 系统
-
epoll 使用一个文件描述符管理多个描述符,将用户关心的文件描述符的事件存放到内核的一个事件表(个人理解成哑元节点)
-
没有最大描述符数量(并发连接)的限制,打开 fd 的上限远大于1024(1G 内存能监听约 10 万个端口)
-
epoll 的时间复杂度 O(1),epoll 理解为 event poll,不同于忙轮询和无差别轮询,调用 epoll_wait 只是轮询就绪链表。当监听列表有设备就绪时调用回调函数,把就绪 fd 放入就绪链表中,并唤醒在 epoll_wait 中阻塞的进程,所以 epoll 实际上是事件驱动(每个事件关联上fd)的,降低了 system call 的时间复杂度
-
epoll 内核中根据每个 fd 上的 callback 函数来实现,只有活跃的 socket 才会主动调用 callback,所以使用 epoll 没有前面两者的线性下降的性能问题,效率提高
-
epoll 注册新的事件是注册到到内核中 epoll 句柄中,不需要每次调用 epoll_wait 时重复拷贝,对比前面两种只需要将描述符从进程缓冲区向内核缓冲区拷贝一次,也可以利用 mmap() 文件映射内存加速与内核空间的消息传递(只是可以用,并没有用)
-
前面两者要把 current 往设备等待队列中挂一次,epoll 也只把 current 往等待队列上挂一次,但是这里的等待队列并不是设备等待队列,只是一个 epoll 内部定义的等待队列,这样可以节省开销
-
epoll 对多线程编程更有友好,一个线程调用了 epoll_wait() 另一个线程关闭了同一个描述符,也不会产生像 select 和 poll 的不确定情况
参考文章:https://www.jianshu.com/p/dfd940e7fca2
参考文章:https://www.cnblogs.com/anker/p/3265058.html
应用
应用场景:
-
select 应用场景:
- select 的 timeout 参数精度为微秒,poll 和 epoll 为毫秒,因此 select 适用实时性要求比较高的场景,比如核反应堆的控制
- select 可移植性更好,几乎被所有主流平台所支持
-
poll 应用场景:poll 没有最大描述符数量的限制,适用于平台支持并且对实时性要求不高的情况
-
epoll 应用场景:
- 运行在 Linux 平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接
- 需要同时监控小于 1000 个描述符,没必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势
- 需要监控的描述符状态变化多,而且是非常短暂的,就没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,每次对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率,并且 epoll 的描述符存储在内核,不容易调试
参考文章:https://github.com/CyC2018/CS-Notes/blob/master/notes/Socket.md
系统调用
内核态
用户空间:用户代码、用户堆栈
内核空间:内核代码、内核调度程序、进程描述符(内核堆栈、thread_info 进程描述符)
- 进程描述符和用户的进程是一一对应的
- SYS_API 系统调用:如 read、write,系统调用就是 0X80 中断
- 进程描述符 pd:进程从用户态切换到内核态时,需要保存用户态时的上下文信息在 PCB 中
- 线程上下文:用户程序基地址,程序计数器、cpu cache、寄存器等,方便程序切回用户态时恢复现场
- 内核堆栈:**系统调用函数也是要创建变量的,**这些变量在内核堆栈上分配
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bxp1TExQ-1679358011075)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO-用户态和内核态.png)]
80中断
在用户程序中调用操作系统提供的核心态级别的子功能,为了系统安全需要进行用户态和内核态转换,状态的转换需要进行 CPU 中断,中断分为硬中断和软中断:
- 硬中断:如网络传输中,数据到达网卡后,网卡经过一系列操作后发起硬件中断
- 软中断:如程序运行过程中本身产生的一些中断
- 发起
0X80中断 - 程序执行碰到除 0 异常
- 发起
系统调用 system_call 函数所对应的中断指令编号是 0X80(十进制是 8×16=128),而该指令编号对应的就是系统调用程序的入口,所以称系统调用为 80 中断
系统调用的流程:
- 在 CPU 寄存器里存一个系统调用号,表示哪个系统函数,比如 read
- 将 CPU 的临时数据都保存到 thread_info 中
- 执行 80 中断处理程序,找到刚刚存的系统调用号(read),先检查缓存中有没有对应的数据,没有就去磁盘中加载到内核缓冲区,然后从内核缓冲区拷贝到用户空间
- 最后恢复到用户态,通过 thread_info 恢复现场,用户态继续执行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-suV5KVRO-1679358011075)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO-系统调用的过程.jpg)]
参考视频:https://www.bilibili.com/video/BV19D4y1o797
零拷贝
DMA
DMA (Direct Memory Access) :直接存储器访问,让外部设备不通过 CPU 直接与系统内存交换数据的接口技术
作用:可以解决批量数据的输入/输出问题,使数据的传送速度取决于存储器和外设的工作速度
把内存数据传输到网卡然后发送:
- 没有 DMA:CPU 读内存数据到 CPU 高速缓存,再写到网卡,这样就把 CPU 的速度拉低到和网卡一个速度
- 使用 DMA:把数据读到 Socket 内核缓存区(CPU 复制),CPU 分配给 DMA 开始异步操作,DMA 读取 Socket 缓冲区到 DMA 缓冲区,然后写到网卡。DMA 执行完后中断(就是通知) CPU,这时 Socket 内核缓冲区为空,CPU 从用户态切换到内核态,执行中断处理程序,将需要使用 Socket 缓冲区的阻塞进程移到就绪队列
一个完整的 DMA 传输过程必须经历 DMA 请求、DMA 响应、DMA 传输、DMA 结束四个步骤:

DMA 方式是一种完全由硬件进行信息传送的控制方式,通常系统总线由 CPU 管理,在 DMA 方式中,CPU 的主存控制信号被禁止使用,CPU 把总线(地址总线、数据总线、控制总线)让出来由 DMA 控制器接管,用来控制传送的字节数、判断 DMA 是否结束、以及发出 DMA 结束信号,所以 DMA 控制器必须有以下功能:
- 接受外设发出的 DMA 请求,并向 CPU 发出总线接管请求
- 当 CPU 发出允许接管信号后,进入 DMA 操作周期
- 确定传送数据的主存单元地址及长度,并自动修改主存地址计数和传送长度计数
- 规定数据在主存和外设间的传送方向,发出读写等控制信号,执行数据传送操作
- 判断 DMA 传送是否结束,发出 DMA 结束信号,使 CPU 恢复正常工作状态(中断)
BIO
传统的 I/O 操作进行了 4 次用户空间与内核空间的上下文切换,以及 4 次数据拷贝:
- JVM 发出 read 系统调用,OS 上下文切换到内核模式(切换 1)并将数据从网卡或硬盘等设备通过 DMA 读取到内核空间缓冲区(拷贝 1),内核缓冲区实际上是磁盘高速缓存(PageCache)
- OS 内核将数据复制到用户空间缓冲区(拷贝 2),然后 read 系统调用返回,又会导致一次内核空间到用户空间的上下文切换(切换 2)
- JVM 处理代码逻辑并发送 write() 系统调用,OS 上下文切换到内核模式(切换3)并从用户空间缓冲区复制数据到内核空间缓冲区(拷贝3)
- 将内核空间缓冲区中的数据写到 hardware(拷贝4),write 系统调用返回,导致内核空间到用户空间的再次上下文切换(切换4)
流程图中的箭头反过来也成立,可以从网卡获取数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ox35anM5-1679358011075)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO-BIO工作流程.png)]
read 调用图示:read、write 都是系统调用指令
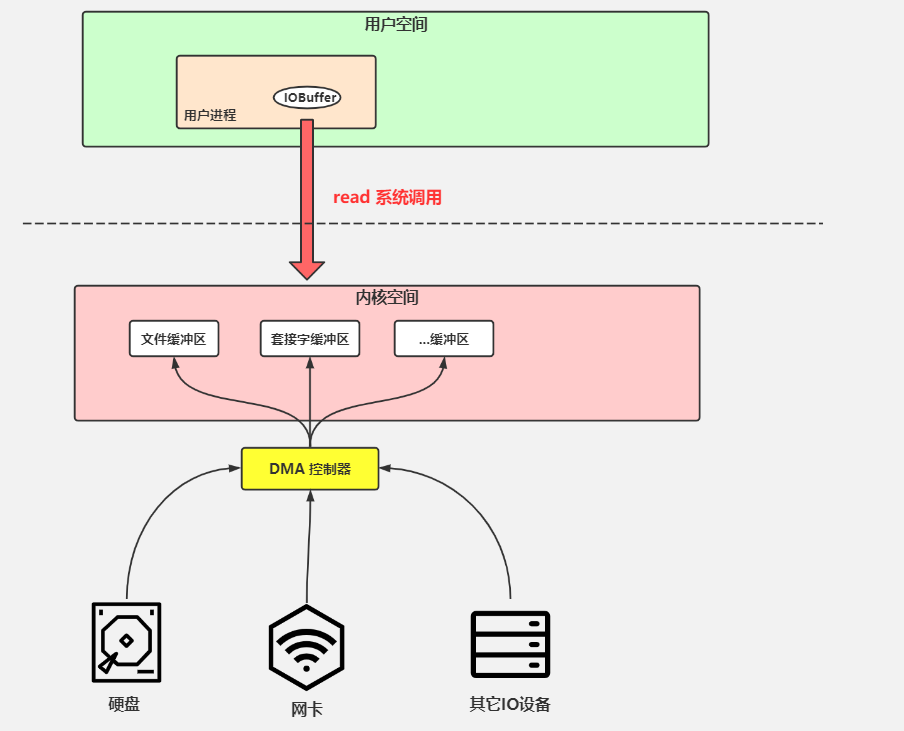
mmap
mmap(Memory Mapped Files)内存映射加 write 实现零拷贝,零拷贝就是没有数据从内核空间复制到用户空间
用户空间和内核空间都使用内存,所以可以共享同一块物理内存地址,省去用户态和内核态之间的拷贝。写网卡时,共享空间的内容拷贝到 Socket 缓冲区,然后交给 DMA 发送到网卡,只需要 3 次复制
进行了 4 次用户空间与内核空间的上下文切换,以及 3 次数据拷贝(2 次 DMA,一次 CPU 复制):
- 发出 mmap 系统调用,DMA 拷贝到内核缓冲区,映射到共享缓冲区;mmap 系统调用返回,无需拷贝
- 发出 write 系统调用,将数据从内核缓冲区拷贝到内核 Socket 缓冲区;write 系统调用返回,DMA 将内核空间 Socket 缓冲区中的数据传递到协议引擎
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZYtFN7YX-1679358011075)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO-mmap工作流程.png)]
原理:利用操作系统的 Page 来实现文件到物理内存的直接映射,完成映射后对物理内存的操作会被同步到硬盘上
缺点:不可靠,写到 mmap 中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘
Java NIO 提供了 MappedByteBuffer 类可以用来实现 mmap 内存映射,MappedByteBuffer 类对象只能通过调用 FileChannel.map() 获取
sendfile
sendfile 实现零拷贝,打开文件的文件描述符 fd 和 socket 的 fd 传递给 sendfile,然后经过 3 次复制和 2 次用户态和内核态的切换
原理:数据根本不经过用户态,直接从内核缓冲区进入到 Socket Buffer,由于和用户态完全无关,就减少了两次上下文切换
说明:零拷贝技术是不允许进程对文件内容作进一步的加工的,比如压缩数据再发送
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hv7spo1N-1679358011075)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/IO-sendfile工作流程.png)]
sendfile2.4 之后,sendfile 实现了更简单的方式,文件到达内核缓冲区后,不必再将数据全部复制到 socket buffer 缓冲区,而是只将记录数据位置和长度相关等描述符信息保存到 socket buffer,DMA 根据 Socket 缓冲区中描述符提供的位置和偏移量信息直接将内核空间缓冲区中的数据拷贝到协议引擎上(2 次复制 2 次切换)
Java NIO 对 sendfile 的支持是 FileChannel.transferTo()/transferFrom(),把磁盘文件读取 OS 内核缓冲区后的 fileChannel,直接转给 socketChannel 发送,底层就是 sendfile
参考文章:https://blog.csdn.net/hancoder/article/details/112149121
BIO
Inet
一个 InetAddress 类的对象就代表一个 IP 地址对象
成员方法:
static InetAddress getLocalHost():获得本地主机 IP 地址对象static InetAddress getByName(String host):根据 IP 地址字符串或主机名获得对应的 IP 地址对象String getHostName():获取主机名String getHostAddress():获得 IP 地址字符串
public class InetAddressDemo {public static void main(String[] args) throws Exception {// 1.获取本机地址对象InetAddress ip = InetAddress.getLocalHost();System.out.println(ip.getHostName());//DESKTOP-NNMBHQRSystem.out.println(ip.getHostAddress());//192.168.11.1// 2.获取域名ip对象InetAddress ip2 = InetAddress.getByName("www.baidu.com");System.out.println(ip2.getHostName());//www.baidu.comSystem.out.println(ip2.getHostAddress());//14.215.177.38// 3.获取公网IP对象。InetAddress ip3 = InetAddress.getByName("182.61.200.6");System.out.println(ip3.getHostName());//182.61.200.6System.out.println(ip3.getHostAddress());//182.61.200.6// 4.判断是否能通: ping 5s之前测试是否可通System.out.println(ip2.isReachable(5000)); // ping百度}
}
UDP
基本介绍
UDP(User Datagram Protocol)协议的特点:
- 面向无连接的协议,发送端只管发送,不确认对方是否能收到,速度快,但是不可靠,会丢失数据
- 尽最大努力交付,没有拥塞控制
- 基于数据包进行数据传输,发送数据的包的大小限制 64KB 以内
- 支持一对一、一对多、多对一、多对多的交互通信
UDP 协议的使用场景:在线视频、网络语音、电话
实现UDP
UDP 协议相关的两个类:
- DatagramPacket(数据包对象):用来封装要发送或要接收的数据,比如:集装箱
- DatagramSocket(发送对象):用来发送或接收数据包,比如:码头
DatagramPacket:
-
DatagramPacket 类:
public new DatagramPacket(byte[] buf, int length, InetAddress address, int port):创建发送端数据包对象- buf:要发送的内容,字节数组
- length:要发送内容的长度,单位是字节
- address:接收端的IP地址对象
- port:接收端的端口号
public new DatagramPacket(byte[] buf, int length):创建接收端的数据包对象- buf:用来存储接收到内容
- length:能够接收内容的长度
-
DatagramPacket 类常用方法:
public int getLength():获得实际接收到的字节个数public byte[] getData():返回数据缓冲区
DatagramSocket:
- DatagramSocket 类构造方法:
protected DatagramSocket():创建发送端的 Socket 对象,系统会随机分配一个端口号protected DatagramSocket(int port):创建接收端的 Socket 对象并指定端口号
- DatagramSocket 类成员方法:
public void send(DatagramPacket dp):发送数据包public void receive(DatagramPacket p):接收数据包public void close():关闭数据报套接字
public class UDPClientDemo {public static void main(String[] args) throws Exception {System.out.println("===启动客户端===");// 1.创建一个集装箱对象,用于封装需要发送的数据包!byte[] buffer = "我学Java".getBytes();DatagramPacket packet = new DatagramPacket(buffer,bubffer.length,InetAddress.getLoclHost,8000);// 2.创建一个码头对象DatagramSocket socket = new DatagramSocket();// 3.开始发送数据包对象socket.send(packet);socket.close();}
}
public class UDPServerDemo{public static void main(String[] args) throws Exception {System.out.println("==启动服务端程序==");// 1.创建一个接收客户都端的数据包对象(集装箱)byte[] buffer = new byte[1024*64];DatagramPacket packet = new DatagramPacket(buffer, bubffer.length);// 2.创建一个接收端的码头对象DatagramSocket socket = new DatagramSocket(8000);// 3.开始接收socket.receive(packet);// 4.从集装箱中获取本次读取的数据量int len = packet.getLength();// 5.输出数据// String rs = new String(socket.getData(), 0, len)String rs = new String(buffer , 0 , len);System.out.println(rs);// 6.服务端还可以获取发来信息的客户端的IP和端口。String ip = packet.getAddress().getHostAdress();int port = packet.getPort();socket.close();}
}
通讯方式
UDP 通信方式:
-
单播:用于两个主机之间的端对端通信
-
组播:用于对一组特定的主机进行通信
IP : 224.0.1.0
Socket 对象 : MulticastSocket
-
广播:用于一个主机对整个局域网上所有主机上的数据通信
IP : 255.255.255.255
Socket 对象 : DatagramSocket
TCP
基本介绍
TCP/IP (Transfer Control Protocol) 协议,传输控制协议
TCP/IP 协议的特点:
- 面向连接的协议,提供可靠交互,速度慢
- 点对点的全双工通信
- 通过三次握手建立连接,连接成功形成数据传输通道;通过四次挥手断开连接
- 基于字节流进行数据传输,传输数据大小没有限制
TCP 协议的使用场景:文件上传和下载、邮件发送和接收、远程登录
注意:TCP 不会为没有数据的 ACK 超时重传
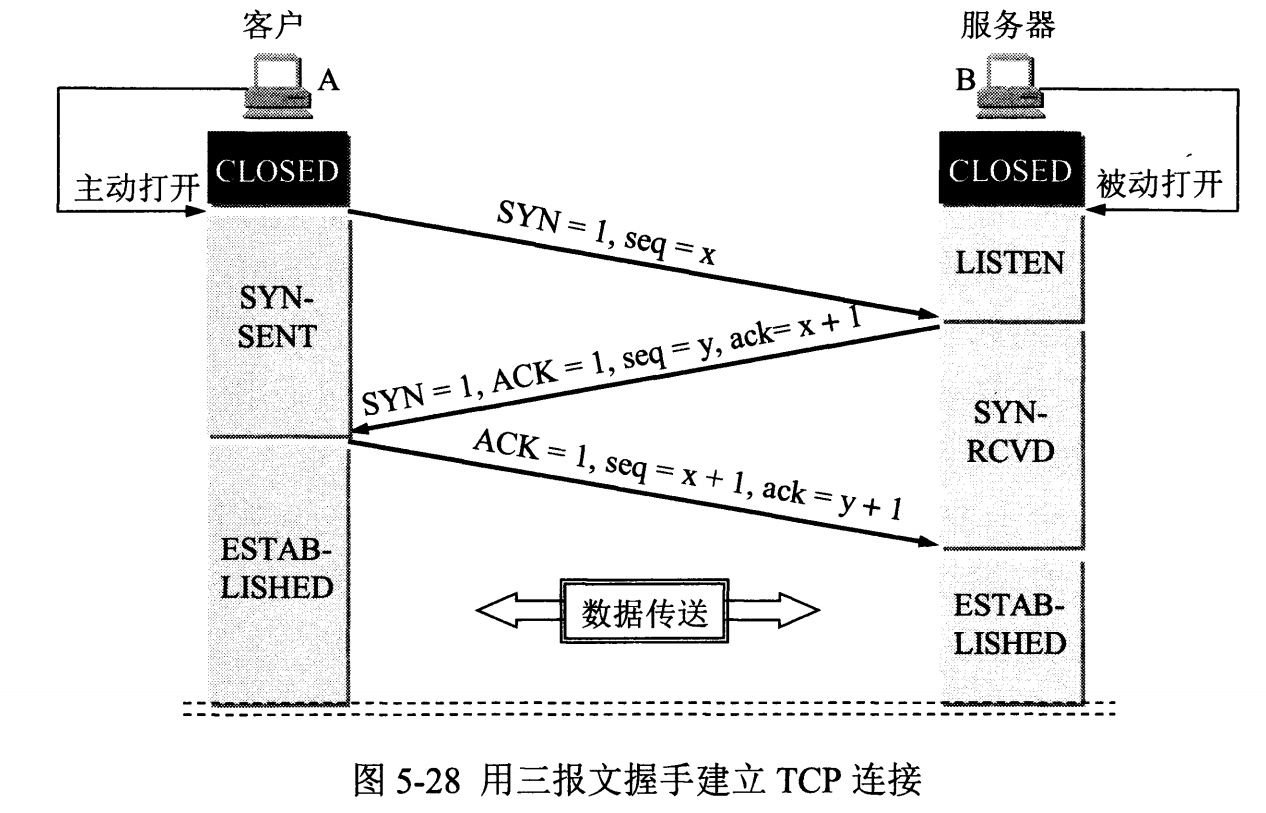
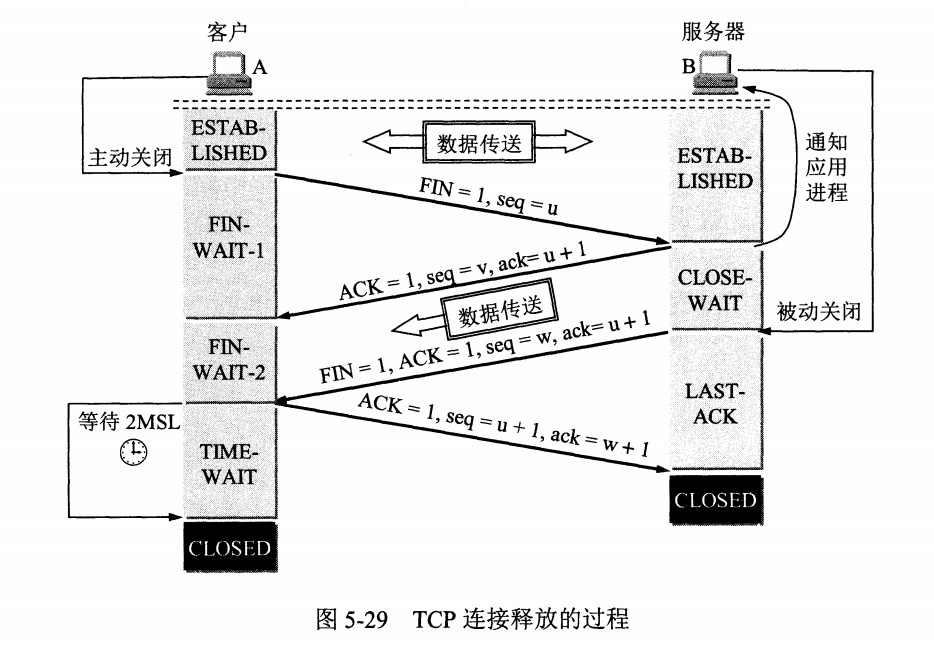
推荐阅读:https://yuanrengu.com/2020/77eef79f.html
Socket
TCP 通信也叫 Socket 网络编程,只要代码基于 Socket 开发,底层就是基于了可靠传输的 TCP 通信
双向通信:Java Socket 是全双工的,在任意时刻,线路上存在 A -> B 和 B -> A 的双向信号传输,即使是阻塞 IO,读和写也是可以同时进行的,只要分别采用读线程和写线程即可,读不会阻塞写、写也不会阻塞读
TCP 协议相关的类:
- Socket:一个该类的对象就代表一个客户端程序。
- ServerSocket:一个该类的对象就代表一个服务器端程序。
Socket 类:
-
构造方法:
-
Socket(InetAddress address,int port):创建流套接字并将其连接到指定 IP 指定端口号 -
Socket(String host, int port):根据 IP 地址字符串和端口号创建客户端 Socket 对象注意事项:执行该方法,就会立即连接指定的服务器,连接成功,则表示三次握手通过,反之抛出异常
-
-
常用 API:
OutputStream getOutputStream():获得字节输出流对象InputStream getInputStream():获得字节输入流对象void shutdownInput():停止接受void shutdownOutput():停止发送数据,终止通信SocketAddress getRemoteSocketAddress():返回套接字连接到的端点的地址,未连接返回 null
ServerSocket 类:
-
构造方法:
public ServerSocket(int port) -
常用 API:
public Socket accept(),阻塞等待接收一个客户端的 Socket 管道连接请求,连接成功返回一个 Socket 对象三次握手后 TCP 连接建立成功,服务器内核会把连接从 SYN 半连接队列(一次握手时在服务端建立的队列)中移出,移入 accept 全连接队列,等待进程调用 accept 函数时把连接取出。如果进程不能及时调用 accept 函数,就会造成 accept 队列溢出,最终导致建立好的 TCP 连接被丢弃
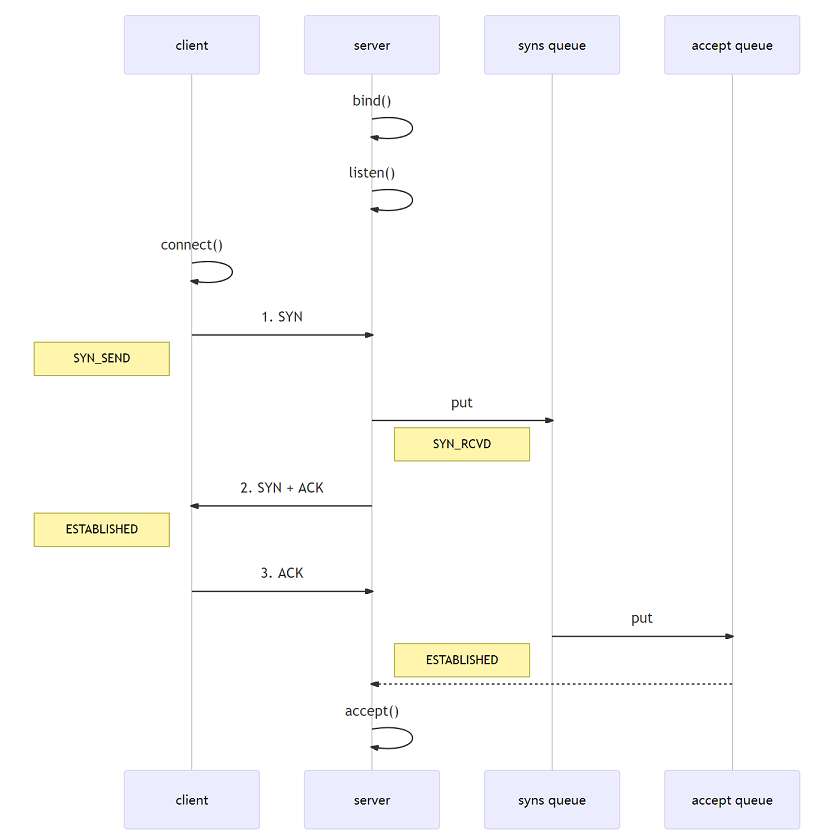
相当于客户端和服务器建立一个数据管道(虚连接,不是真正的物理连接),管道一般不用 close
实现TCP
开发流程
客户端的开发流程:
- 客户端要请求于服务端的 Socket 管道连接
- 从 Socket 通信管道中得到一个字节输出流
- 通过字节输出流给服务端写出数据
服务端的开发流程:
- 用 ServerSocket 注册端口
- 接收客户端的 Socket 管道连接
- 从 Socket 通信管道中得到一个字节输入流
- 从字节输入流中读取客户端发来的数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ndJkerZi-1679358011076)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/BIO工作机制.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C1qu6gZX-1679358011077)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/TCP-工作模型.png)]
- 如果输出缓冲区空间不够存放主机发送的数据,则会被阻塞,输入缓冲区同理
- 缓冲区不属于应用程序,属于内核
- TCP 从输出缓冲区读取数据会加锁阻塞线程
实现通信
需求一:客户端发送一行数据,服务端接收一行数据
public class ClientDemo {public static void main(String[] args) throws Exception {// 1.客户端要请求于服务端的socket管道连接。Socket socket = new Socket("127.0.0.1", 8080);// 2.从socket通信管道中得到一个字节输出流OutputStream os = socket.getOutputStream();// 3.把低级的字节输出流包装成高级的打印流。PrintStream ps = new PrintStream(os);// 4.开始发消息出去ps.println("我是客户端");ps.flush();//一般不关闭IO流System.out.println("客户端发送完毕~~~~");}
}
public class ServerDemo{public static void main(String[] args) throws Exception {System.out.println("----服务端启动----");// 1.注册端口: public ServerSocket(int port)ServerSocket serverSocket = new ServerSocket(8080);// 2.开始等待接收客户端的Socket管道连接。Socket socket = serverSocket.accept();// 3.从socket通信管道中得到一个字节输入流。InputStream is = socket.getInputStream();// 4.把字节输入流转换成字符输入流BufferedReader br = new BufferedReader(new InputStreamReader(is));// 6.按照行读取消息 。String line;if((line = br.readLine()) != null){System.out.println(line);}}
}
需求二:客户端可以反复发送数据,服务端可以反复数据
public class ClientDemo {public static void main(String[] args) throws Exception {// 1.客户端要请求于服务端的socket管道连接。Socket socket = new Socket("127.0.0.1",8080);// 2.从socket通信管道中得到一个字节输出流OutputStream os = socket.getOutputStream();// 3.把低级的字节输出流包装成高级的打印流。PrintStream ps = new PrintStream(os);// 4.开始发消息出去while(true){Scanner sc = new Scanner(System.in);System.out.print("请说:");ps.println(sc.nextLine());ps.flush();}}
}
public class ServerDemo{public static void main(String[] args) throws Exception {System.out.println("----服务端启动----");// 1.注册端口: public ServerSocket(int port)ServerSocket serverSocket = new ServerSocket(8080);// 2.开始等待接收客户端的Socket管道连接。Socket socket = serverSocket.accept();// 3.从socket通信管道中得到一个字节输入流。InputStream is = socket.getInputStream();// 4.把字节输入流转换成字符输入流BufferedReader br = new BufferedReader(new InputStreamReader(is));// 6.按照行读取消息 。String line;while((line = br.readLine()) != null){System.out.println(line);}}
}
需求三:实现一个服务端可以同时接收多个客户端的消息
public class ClientDemo {public static void main(String[] args) throws Exception {Socket socket = new Socket("127.0.0.1",8080);OutputStream os = new socket.getOutputStream();PrintStream ps = new PrintStream(os);while(true){Scanner sc = new Scanner(System.in);System.out.print("请说:");ps.println(sc.nextLine());ps.flush();}}
}
public class ServerDemo{public static void main(String[] args) throws Exception {System.out.println("----服务端启动----");ServerSocket serverSocket = new ServerSocket(8080);while(true){// 开始等待接收客户端的Socket管道连接。Socket socket = serverSocket.accept();// 每接收到一个客户端必须为这个客户端管道分配一个独立的线程来处理与之通信。new ServerReaderThread(socket).start();}}
}
class ServerReaderThread extends Thread{privat Socket socket;public ServerReaderThread(Socket socket){this.socket = socket;}@Overridepublic void run() {try(InputStream is = socket.getInputStream();BufferedReader br = new BufferedReader(new InputStreamReader(is))){String line;while((line = br.readLine()) != null){sout(socket.getRemoteSocketAddress() + ":" + line);}}catch(Exception e){sout(socket.getRemoteSocketAddress() + "下线了~~~~~~");}}
}
伪异步
一个客户端要一个线程,并发越高系统瘫痪的越快,可以在服务端引入线程池,使用线程池来处理与客户端的消息通信
-
优势:不会引起系统的死机,可以控制并发线程的数量
-
劣势:同时可以并发的线程将受到限制
public class BIOServer {public static void main(String[] args) throws Exception {//线程池机制//创建一个线程池,如果有客户端连接,就创建一个线程,与之通讯(单独写一个方法)ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();//创建ServerSocketServerSocket serverSocket = new ServerSocket(6666);System.out.println("服务器启动了");while (true) {System.out.println("线程名字 = " + Thread.currentThread().getName());//监听,等待客户端连接System.out.println("等待连接....");final Socket socket = serverSocket.accept();System.out.println("连接到一个客户端");//创建一个线程,与之通讯newCachedThreadPool.execute(new Runnable() {public void run() {//可以和客户端通讯handler(socket);}});}}//编写一个handler方法,和客户端通讯public static void handler(Socket socket) {try {System.out.println("线程名字 = " + Thread.currentThread().getName());byte[] bytes = new byte[1024];//通过socket获取输入流InputStream inputStream = socket.getInputStream();int len;//循环的读取客户端发送的数据while ((len = inputStream.read(bytes)) != -1) {System.out.println("线程名字 = " + Thread.currentThread().getName());//输出客户端发送的数据System.out.println(new String(bytes, 0, read));}} catch (Exception e) {e.printStackTrace();} finally {System.out.println("关闭和client的连接");try {socket.close();} catch (Exception e) {e.printStackTrace();}}}
}
文件传输
字节流
客户端:本地图片: E:\seazean\图片资源\beautiful.jpg
服务端:服务器路径:E:\seazean\图片服务器
UUID. randomUUID() : 方法生成随机的文件名
socket.shutdownOutput():这个必须执行,不然服务器会一直循环等待数据,最后文件损坏,程序报错
//常量包
public class Constants {public static final String SRC_IMAGE = "D:\\seazean\\图片资源\\beautiful.jpg";public static final String SERVER_DIR = "D:\\seazean\\图片服务器\\";public static final String SERVER_IP = "127.0.0.1";public static final int SERVER_PORT = 8888;}
public class ClientDemo {public static void main(String[] args) throws Exception {Socket socket = new Socket(Constants.ERVER_IP,Constants.SERVER_PORT);BufferedOutputStream bos=new BufferedOutputStream(socket.getOutputStream());//提取本机的图片上传给服务端。Constants.SRC_IMAGEBufferedInputStream bis = new BufferedInputStream(new FileInputStream());byte[] buffer = new byte[1024];int len ;while((len = bis.read(buffer)) != -1) {bos.write(buffer, 0 ,len);}bos.flush();// 刷新图片数据到服务端!!socket.shutdownOutput();// 告诉服务端我的数据已经发送完毕,不要在等我了!bis.close();//等待着服务端的响应数据!!BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream()));System.out.println("收到服务端响应:"+br.readLine());}
}
public class ServerDemo {public static void main(String[] args) throws Exception {System.out.println("----服务端启动----");// 1.注册端口: ServerSocket serverSocket = new ServerSocket(Constants.SERVER_PORT);// 2.定义一个循环不断的接收客户端的连接请求while(true){// 3.开始等待接收客户端的Socket管道连接。Socket socket = serverSocket.accept();// 4.每接收到一个客户端必须为这个客户端管道分配一个独立的线程来处理与之通信。new ServerReaderThread(socket).start();}}
}
class ServerReaderThread extends Thread{private Socket socket ;public ServerReaderThread(Socket socket){this.socket = socket;}@Overridepublic void run() {try{InputStream is = socket.getInputStream();BufferedInputStream bis = new BufferedInputStream(is);BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(Constants.SERVER_DIR+UUID.randomUUID().toString()+".jpg"));byte[] buffer = new byte[1024];int len;while((len = bis.read(buffer)) != -1){bos.write(buffer,0,len);}bos.close();System.out.println("服务端接收完毕了!");// 4.响应数据给客户端PrintStream ps = new PrintStream(socket.getOutputStream());ps.println("您好,已成功接收您上传的图片!");ps.flush();Thread.sleep(10000);}catch (Exception e){sout(socket.getRemoteSocketAddress() + "下线了");}}
}
数据流
构造方法:
DataOutputStream(OutputStream out): 创建一个新的数据输出流,以将数据写入指定的底层输出流DataInputStream(InputStream in): 创建使用指定的底层 InputStream 的 DataInputStream
常用API:
final void writeUTF(String str): 使用机器无关的方式使用 UTF-8 编码将字符串写入底层输出流final String readUTF(): 读取以 modified UTF-8 格式编码的 Unicode 字符串,返回 String 类型
public class Client {public static void main(String[] args) {InputStream is = new FileInputStream("path");// 1、请求与服务端的Socket链接Socket socket = new Socket("127.0.0.1" , 8888);// 2、把字节输出流包装成一个数据输出流DataOutputStream dos = new DataOutputStream(socket.getOutputStream());// 3、先发送上传文件的后缀给服务端dos.writeUTF(".png");// 4、把文件数据发送给服务端进行接收byte[] buffer = new byte[1024];int len;while((len = is.read(buffer)) > 0 ){dos.write(buffer , 0 , len);}dos.flush();Thread.sleep(10000);}
}public class Server {public static void main(String[] args) {ServerSocket ss = new ServerSocket(8888);Socket socket = ss.accept();// 1、得到一个数据输入流读取客户端发送过来的数据DataInputStream dis = new DataInputStream(socket.getInputStream());// 2、读取客户端发送过来的文件类型String suffix = dis.readUTF();// 3、定义一个字节输出管道负责把客户端发来的文件数据写出去OutputStream os = new FileOutputStream("path"+UUID.randomUUID().toString()+suffix);// 4、从数据输入流中读取文件数据,写出到字节输出流中去byte[] buffer = new byte[1024];int len;while((len = dis.read(buffer)) > 0){os.write(buffer,0, len);}os.close();System.out.println("服务端接收文件保存成功!");}
}
NIO
基本介绍
NIO的介绍:
Java NIO(New IO、Java non-blocking IO),从 Java 1.4 版本开始引入的一个新的 IO API,可以替代标准的 Java IO API,NIO 支持面向缓冲区的、基于通道的 IO 操作,以更加高效的方式进行文件的读写操作
- NIO 有三大核心部分:Channel(通道),Buffer(缓冲区),Selector(选择器)
- NIO 是非阻塞 IO,传统 IO 的 read 和 write 只能阻塞执行,线程在读写 IO 期间不能干其他事情,比如调用 socket.accept(),如果服务器没有数据传输过来,线程就一直阻塞,而 NIO 中可以配置 Socket 为非阻塞模式
- NIO 可以做到用一个线程来处理多个操作的。假设有 1000 个请求过来,根据实际情况可以分配 20 或者 80 个线程来处理,不像之前的阻塞 IO 那样分配 1000 个
NIO 和 BIO 的比较:
-
BIO 以流的方式处理数据,而 NIO 以块的方式处理数据,块 I/O 的效率比流 I/O 高很多
-
BIO 是阻塞的,NIO 则是非阻塞的
-
BIO 基于字节流和字符流进行操作,而 NIO 基于 Channel 和 Buffer 进行操作,数据从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector 用于监听多个通道的事件(比如:连接请求,数据到达等),因此使用单个线程就可以监听多个客户端通道
NIO BIO 面向缓冲区(Buffer) 面向流(Stream) 非阻塞(Non Blocking IO) 阻塞IO(Blocking IO) 选择器(Selectors)
实现原理
NIO 三大核心部分:Channel (通道)、Buffer (缓冲区)、Selector (选择器)
-
Buffer 缓冲区
缓冲区本质是一块可以写入数据、读取数据的内存,底层是一个数组,这块内存被包装成 NIO Buffer 对象,并且提供了方法用来操作这块内存,相比较直接对数组的操作,Buffer 的 API 更加容易操作和管理
-
Channel 通道
Java NIO 的通道类似流,不同的是既可以从通道中读取数据,又可以写数据到通道,流的读写通常是单向的,通道可以非阻塞读取和写入通道,支持读取或写入缓冲区,也支持异步地读写
-
Selector 选择器
Selector 是一个 Java NIO 组件,能够检查一个或多个 NIO 通道,并确定哪些通道已经准备好进行读取或写入,这样一个单独的线程可以管理多个 channel,从而管理多个网络连接,提高效率
NIO 的实现框架:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KvyxnWkb-1679358011077)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/NIO框架.png)]
- 每个 Channel 对应一个 Buffer
- 一个线程对应 Selector , 一个 Selector 对应多个 Channel(连接)
- 程序切换到哪个 Channel 是由事件决定的,Event 是一个重要的概念
- Selector 会根据不同的事件,在各个通道上切换
- Buffer 是一个内存块 , 底层是一个数组
- 数据的读取写入是通过 Buffer 完成的 , BIO 中要么是输入流,或者是输出流,不能双向,NIO 的 Buffer 是可以读也可以写, flip() 切换 Buffer 的工作模式
Java NIO 系统的核心在于:通道和缓冲区,通道表示打开的 IO 设备(例如:文件、 套接字)的连接。若要使用 NIO 系统,获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区,然后操作缓冲区,对数据进行处理。简而言之,Channel 负责传输, Buffer 负责存取数据
缓冲区
基本介绍
缓冲区(Buffer):缓冲区本质上是一个可以读写数据的内存块,用于特定基本数据类型的容器,用于与 NIO 通道进行交互,数据是从通道读入缓冲区,从缓冲区写入通道中的
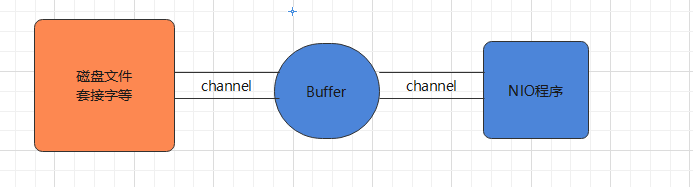
Buffer 底层是一个数组,可以保存多个相同类型的数据,根据数据类型不同 ,有以下 Buffer 常用子类:ByteBuffer、CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer
基本属性
-
容量(capacity):作为一个内存块,Buffer 具有固定大小,缓冲区容量不能为负,并且创建后不能更改
-
限制 (limit):表示缓冲区中可以操作数据的大小(limit 后数据不能进行读写),缓冲区的限制不能为负,并且不能大于其容量。写入模式,limit 等于 buffer 的容量;读取模式下,limit 等于写入的数据量
-
位置(position):下一个要读取或写入的数据的索引,缓冲区的位置不能为负,并且不能大于其限制
-
标记(mark)与重置(reset):标记是一个索引,通过 Buffer 中的 mark() 方法指定 Buffer 中一个特定的位置,可以通过调用 reset() 方法恢复到这个 position
-
位置、限制、容量遵守以下不变式: 0 <= position <= limit <= capacity
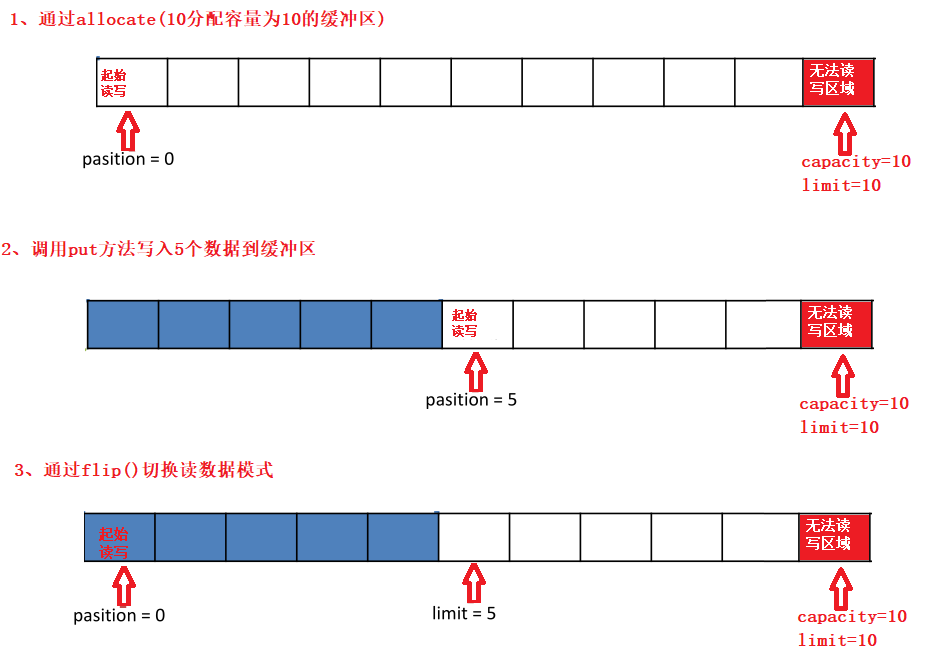
常用API
static XxxBuffer allocate(int capacity):创建一个容量为 capacity 的 XxxBuffer 对象
Buffer 基本操作:
| 方法 | 说明 |
|---|---|
| public Buffer clear() | 清空缓冲区,不清空内容,将位置设置为零,限制设置为容量 |
| public Buffer flip() | 翻转缓冲区,将缓冲区的界限设置为当前位置,position 置 0 |
| public int capacity() | 返回 Buffer的 capacity 大小 |
| public final int limit() | 返回 Buffer 的界限 limit 的位置 |
| public Buffer limit(int n) | 设置缓冲区界限为 n |
| public Buffer mark() | 在此位置对缓冲区设置标记 |
| public final int position() | 返回缓冲区的当前位置 position |
| public Buffer position(int n) | 设置缓冲区的当前位置为n |
| public Buffer reset() | 将位置 position 重置为先前 mark 标记的位置 |
| public Buffer rewind() | 将位置设为为 0,取消设置的 mark |
| public final int remaining() | 返回当前位置 position 和 limit 之间的元素个数 |
| public final boolean hasRemaining() | 判断缓冲区中是否还有元素 |
| public static ByteBuffer wrap(byte[] array) | 将一个字节数组包装到缓冲区中 |
| abstract ByteBuffer asReadOnlyBuffer() | 创建一个新的只读字节缓冲区 |
| public abstract ByteBuffer compact() | 缓冲区当前位置与其限制(如果有)之间的字节被复制到缓冲区的开头 |
Buffer 数据操作:
| 方法 | 说明 |
|---|---|
| public abstract byte get() | 读取该缓冲区当前位置的单个字节,然后位置 + 1 |
| public ByteBuffer get(byte[] dst) | 读取多个字节到字节数组 dst 中 |
| public abstract byte get(int index) | 读取指定索引位置的字节,不移动 position |
| public abstract ByteBuffer put(byte b) | 将给定单个字节写入缓冲区的当前位置,position+1 |
| public final ByteBuffer put(byte[] src) | 将 src 字节数组写入缓冲区的当前位置 |
| public abstract ByteBuffer put(int index, byte b) | 将指定字节写入缓冲区的索引位置,不移动 position |
提示:“\n”,占用两个字节
读写数据
使用 Buffer 读写数据一般遵循以下四个步骤:
- 写入数据到 Buffer
- 调用 flip()方法,转换为读取模式
- 从 Buffer 中读取数据
- 调用 buffer.clear() 方法清除缓冲区(不是清空了数据,只是重置指针)
public class TestBuffer {@Testpublic void test(){String str = "seazean";//1. 分配一个指定大小的缓冲区ByteBuffer buffer = ByteBuffer.allocate(1024);System.out.println("-----------------allocate()----------------");System.out.println(bufferf.position());//0System.out.println(buffer.limit());//1024System.out.println(buffer.capacity());//1024//2. 利用 put() 存入数据到缓冲区中buffer.put(str.getBytes());System.out.println("-----------------put()----------------");System.out.println(bufferf.position());//7System.out.println(buffer.limit());//1024System.out.println(buffer.capacity());//1024//3. 切换读取数据模式buffer.flip();System.out.println("-----------------flip()----------------");System.out.println(buffer.position());//0System.out.println(buffer.limit());//7System.out.println(buffer.capacity());//1024//4. 利用 get() 读取缓冲区中的数据byte[] dst = new byte[buffer.limit()];buffer.get(dst);System.out.println(dst.length);System.out.println(new String(dst, 0, dst.length));System.out.println(buffer.position());//7System.out.println(buffer.limit());//7//5. clear() : 清空缓冲区. 但是缓冲区中的数据依然存在,但是处于“被遗忘”状态System.out.println(buffer.hasRemaining());//truebuffer.clear();System.out.println(buffer.hasRemaining());//trueSystem.out.println("-----------------clear()----------------");System.out.println(buffer.position());//0System.out.println(buffer.limit());//1024System.out.println(buffer.capacity());//1024}
}
粘包拆包
网络上有多条数据发送给服务端,数据之间使用 \n 进行分隔,但这些数据在接收时,被进行了重新组合
// Hello,world\n
// I'm zhangsan\n
// How are you?\n
------ > 黏包,半包
// Hello,world\nI'm zhangsan\nHo
// w are you?\n
public static void main(String[] args) {ByteBuffer source = ByteBuffer.allocate(32);// 11 24source.put("Hello,world\nI'm zhangsan\nHo".getBytes());split(source);source.put("w are you?\nhaha!\n".getBytes());split(source);
}private static void split(ByteBuffer source) {source.flip();int oldLimit = source.limit();for (int i = 0; i < oldLimit; i++) {if (source.get(i) == '\n') {// 根据数据的长度设置缓冲区ByteBuffer target = ByteBuffer.allocate(i + 1 - source.position());// 0 ~ limitsource.limit(i + 1);target.put(source); // 从source 读,向 target 写// debugAll(target); 访问 buffer 的方法source.limit(oldLimit);}}// 访问过的数据复制到开头source.compact();
}
直接内存
基本介绍
Byte Buffer 有两种类型,一种是基于直接内存(也就是非堆内存),另一种是非直接内存(也就是堆内存)
Direct Memory 优点:
- Java 的 NIO 库允许 Java 程序使用直接内存,使用 native 函数直接分配堆外内存
- 读写性能高,读写频繁的场合可能会考虑使用直接内存
- 大大提高 IO 性能,避免了在 Java 堆和 native 堆来回复制数据
直接内存缺点:
- 不能使用内核缓冲区 Page Cache 的缓存优势,无法缓存最近被访问的数据和使用预读功能
- 分配回收成本较高,不受 JVM 内存回收管理
- 可能导致 OutOfMemoryError 异常:OutOfMemoryError: Direct buffer memory
- 回收依赖 System.gc() 的调用,但这个调用 JVM 不保证执行、也不保证何时执行,行为是不可控的。程序一般需要自行管理,成对去调用 malloc、free
应用场景:
- 传输很大的数据文件,数据的生命周期很长,导致 Page Cache 没有起到缓存的作用,一般采用直接 IO 的方式
- 适合频繁的 IO 操作,比如网络并发场景
数据流的角度:
- 非直接内存的作用链:本地 IO → 内核缓冲区→ 用户(JVM)缓冲区 →内核缓冲区 → 本地 IO
- 直接内存是:本地 IO → 直接内存 → 本地 IO
JVM 直接内存图解:
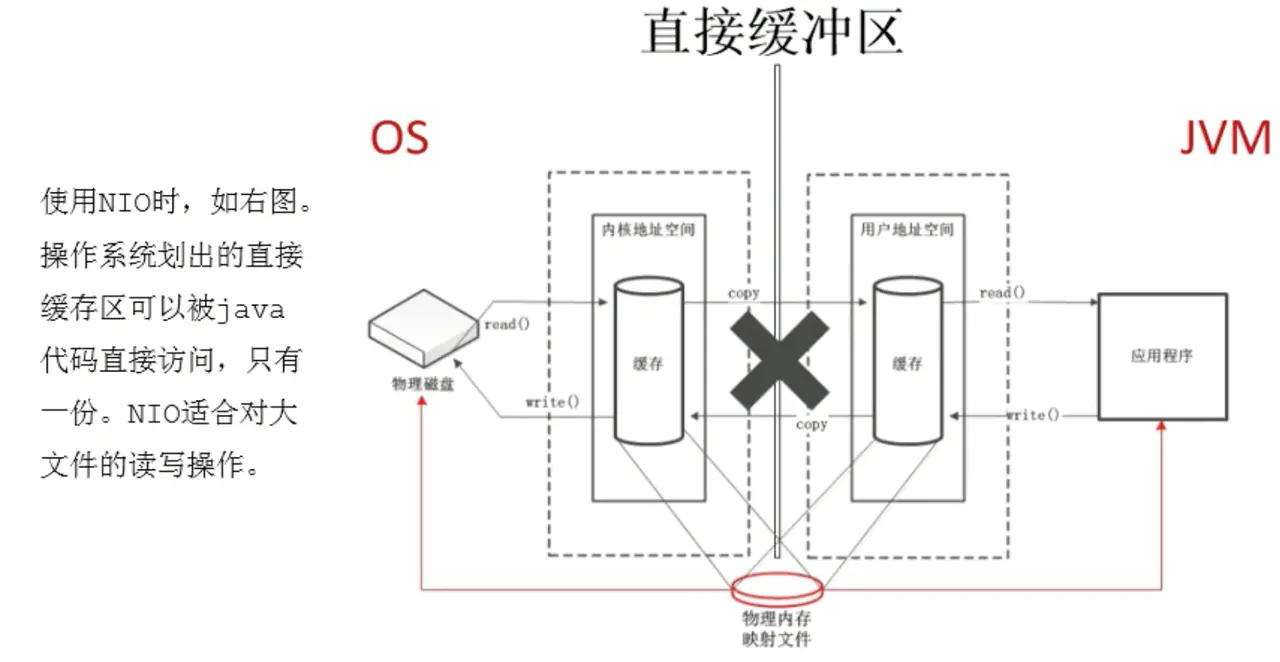
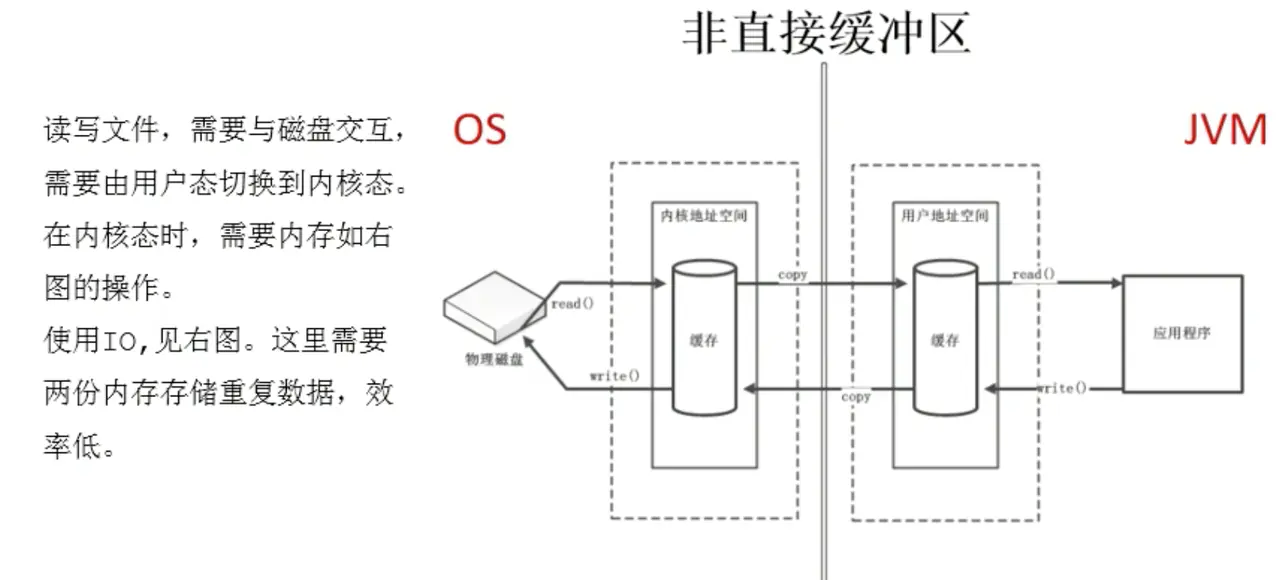
通信原理
堆外内存不受 JVM GC 控制,可以使用堆外内存进行通信,防止 GC 后缓冲区位置发生变化的情况
NIO 使用的 SocketChannel 也是使用的堆外内存,源码解析:
-
SocketChannel#write(java.nio.ByteBuffer) → SocketChannelImpl#write(java.nio.ByteBuffer)
public int write(ByteBuffer var1) throws IOException {do {var3 = IOUtil.write(this.fd, var1, -1L, nd);} while(var3 == -3 && this.isOpen()); } -
IOUtil#write(java.io.FileDescriptor, java.nio.ByteBuffer, long, sun.nio.ch.NativeDispatcher)
static int write(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) {// 【判断是否是直接内存,是则直接写出,不是则封装到直接内存】if (var1 instanceof DirectBuffer) {return writeFromNativeBuffer(var0, var1, var2, var4);} else {//....// 从堆内buffer拷贝到堆外bufferByteBuffer var8 = Util.getTemporaryDirectBuffer(var7);var8.put(var1);//...// 从堆外写到内核缓冲区int var9 = writeFromNativeBuffer(var0, var8, var2, var4);} } -
读操作相同
分配回收
直接内存创建 Buffer 对象:static XxxBuffer allocateDirect(int capacity)
DirectByteBuffer 源码分析:
DirectByteBuffer(int cap) { //....long base = 0;try {// 分配直接内存base = unsafe.allocateMemory(size);}// 内存赋值unsafe.setMemory(base, size, (byte) 0);if (pa && (base % ps != 0)) {address = base + ps - (base & (ps - 1));} else {address = base;}// 创建回收函数cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
}
private static class Deallocator implements Runnable {public void run() {unsafe.freeMemory(address);//...}
}
分配和回收原理:
- 使用了 Unsafe 对象的 allocateMemory 方法完成直接内存的分配,setMemory 方法完成赋值
- ByteBuffer 的实现类内部,使用了 Cleaner(虚引用)来监测 ByteBuffer 对象,一旦 ByteBuffer 对象被垃圾回收,那么 ReferenceHandler 线程通过 Cleaner 的 clean 方法调用 Deallocator 的 run方法,最后通过 freeMemory 来释放直接内存
/*** 直接内存分配的底层原理:Unsafe*/
public class Demo1_27 {static int _1Gb = 1024 * 1024 * 1024;public static void main(String[] args) throws IOException {Unsafe unsafe = getUnsafe();// 分配内存long base = unsafe.allocateMemory(_1Gb);unsafe.setMemory(base, _1Gb, (byte) 0);System.in.read();// 释放内存unsafe.freeMemory(base);System.in.read();}public static Unsafe getUnsafe() {try {Field f = Unsafe.class.getDeclaredField("theUnsafe");f.setAccessible(true);Unsafe unsafe = (Unsafe) f.get(null);return unsafe;} catch (NoSuchFieldException | IllegalAccessException e) {throw new RuntimeException(e);}}
}
共享内存
FileChannel 提供 map 方法返回 MappedByteBuffer 对象,把文件映射到内存,通常情况可以映射整个文件,如果文件比较大,可以进行分段映射,完成映射后对物理内存的操作会被同步到硬盘上
FileChannel 中的成员属性:
-
MapMode.mode:内存映像文件访问的方式,共三种:
MapMode.READ_ONLY:只读,修改得到的缓冲区将导致抛出异常MapMode.READ_WRITE:读/写,对缓冲区的更改最终将写入文件,但此次修改对映射到同一文件的其他程序不一定是可见MapMode.PRIVATE:私用,可读可写,但是修改的内容不会写入文件,只是 buffer 自身的改变
-
public final FileLock lock():获取此文件通道的排他锁
MappedByteBuffer,可以让文件在直接内存(堆外内存)中进行修改,这种方式叫做内存映射,可以直接调用系统底层的缓存,没有 JVM 和 OS 之间的复制操作,提高了传输效率,作用:
- 可以用于进程间的通信,能达到共享内存页的作用,但在高并发下要对文件内存进行加锁,防止出现读写内容混乱和不一致性,Java 提供了文件锁 FileLock,但在父/子进程中锁定后另一进程会一直等待,效率不高
- 读写那些太大而不能放进内存中的文件,分段映射
MappedByteBuffer 较之 ByteBuffer 新增的三个方法:
final MappedByteBuffer force():缓冲区是 READ_WRITE 模式下,对缓冲区内容的修改强制写入文件final MappedByteBuffer load():将缓冲区的内容载入物理内存,并返回该缓冲区的引用final boolean isLoaded():如果缓冲区的内容在物理内存中,则返回真,否则返回假
public class MappedByteBufferTest {public static void main(String[] args) throws Exception {// 读写模式RandomAccessFile ra = new RandomAccessFile("1.txt", "rw");// 获取对应的通道FileChannel channel = ra.getChannel();/*** 参数1 FileChannel.MapMode.READ_WRITE 使用的读写模式* 参数2 0: 文件映射时的起始位置* 参数3 5: 是映射到内存的大小(不是索引位置),即将 1.txt 的多少个字节映射到内存* 可以直接修改的范围就是 0-5* 实际类型 DirectByteBuffer*/MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, 5);buffer.put(0, (byte) 'H');buffer.put(3, (byte) '9');buffer.put(5, (byte) 'Y'); //IndexOutOfBoundsExceptionra.close();System.out.println("修改成功~~");}
}
从硬盘上将文件读入内存,要经过文件系统进行数据拷贝,拷贝操作是由文件系统和硬件驱动实现。通过内存映射的方法访问硬盘上的文件,拷贝数据的效率要比 read 和 write 系统调用高:
- read() 是系统调用,首先将文件从硬盘拷贝到内核空间的一个缓冲区,再将这些数据拷贝到用户空间,实际上进行了两次数据拷贝
- mmap() 也是系统调用,但没有进行数据拷贝,当缺页中断发生时,直接将文件从硬盘拷贝到共享内存,只进行了一次数据拷贝
注意:mmap 的文件映射,在 Full GC 时才会进行释放,如果需要手动清除内存映射文件,可以反射调用 sun.misc.Cleaner 方法
参考文章:https://www.jianshu.com/p/f90866dcbffc
通道
基本介绍
通道(Channel):表示 IO 源与目标打开的连接,Channel 类似于传统的流,只不过 Channel 本身不能直接访问数据,Channel 只能与 Buffer 进行交互
-
NIO 的通道类似于流,但有些区别如下:
- 通道可以同时进行读写,而流只能读或者只能写
- 通道可以实现异步读写数据
- 通道可以从缓冲读数据,也可以写数据到缓冲
-
BIO 中的 Stream 是单向的,NIO 中的 Channel 是双向的,可以读操作,也可以写操作
-
Channel 在 NIO 中是一个接口:
public interface Channel extends Closeable{}
Channel 实现类:
-
FileChannel:用于读取、写入、映射和操作文件的通道,只能工作在阻塞模式下
- 通过 FileInputStream 获取的 Channel 只能读
- 通过 FileOutputStream 获取的 Channel 只能写
- 通过 RandomAccessFile 是否能读写根据构造 RandomAccessFile 时的读写模式决定
-
DatagramChannel:通过 UDP 读写网络中的数据通道
-
SocketChannel:通过 TCP 读写网络中的数据
-
ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel
提示:ServerSocketChanne 类似 ServerSocket、SocketChannel 类似 Socket
常用API
获取 Channel 方式:
- 对支持通道的对象调用
getChannel()方法 - 通过通道的静态方法
open()打开并返回指定通道 - 使用 Files 类的静态方法
newByteChannel()获取字节通道
Channel 基本操作:读写都是相对于内存来看,也就是缓冲区
| 方法 | 说明 |
|---|---|
| public abstract int read(ByteBuffer dst) | 从 Channel 中读取数据到 ByteBuffer,从 position 开始储存 |
| public final long read(ByteBuffer[] dsts) | 将 Channel 中的数据分散到 ByteBuffer[] |
| public abstract int write(ByteBuffer src) | 将 ByteBuffer 中的数据写入 Channel,从 position 开始写出 |
| public final long write(ByteBuffer[] srcs) | 将 ByteBuffer[] 到中的数据聚集到 Channel |
| public abstract long position() | 返回此通道的文件位置 |
| FileChannel position(long newPosition) | 设置此通道的文件位置 |
| public abstract long size() | 返回此通道的文件的当前大小 |
SelectableChannel 的操作 API:
| 方法 | 说明 |
|---|---|
| SocketChannel accept() | 如果通道处于非阻塞模式,没有请求连接时此方法将立即返回 NULL,否则将阻塞直到有新的连接或发生 I/O 错误,通过该方法返回的套接字通道将处于阻塞模式 |
| SelectionKey register(Selector sel, int ops) | 将通道注册到选择器上,并指定监听事件 |
| SelectionKey register(Selector sel, int ops, Object att) | 将通道注册到选择器上,并在当前通道绑定一个附件对象,Object 代表可以是任何类型 |
文件读写
public class ChannelTest {@Testpublic void write() throws Exception{// 1、字节输出流通向目标文件FileOutputStream fos = new FileOutputStream("data01.txt");// 2、得到字节输出流对应的通道 【FileChannel】FileChannel channel = fos.getChannel();// 3、分配缓冲区ByteBuffer buffer = ByteBuffer.allocate(1024);buffer.put("hello,黑马Java程序员!".getBytes());// 4、把缓冲区切换成写出模式buffer.flip();channel.write(buffer);channel.close();System.out.println("写数据到文件中!");}@Testpublic void read() throws Exception {// 1、定义一个文件字节输入流与源文件接通FileInputStream fis = new FileInputStream("data01.txt");// 2、需要得到文件字节输入流的文件通道FileChannel channel = fis.getChannel();// 3、定义一个缓冲区ByteBuffer buffer = ByteBuffer.allocate(1024);// 4、读取数据到缓冲区channel.read(buffer);buffer.flip();// 5、读取出缓冲区中的数据并输出即可String rs = new String(buffer.array(),0,buffer.remaining());System.out.println(rs);}
}
文件复制
Channel 的方法:sendfile 实现零拷贝
-
abstract long transferFrom(ReadableByteChannel src, long position, long count):从给定的可读字节通道将字节传输到该通道的文件中- src:源通道
- position:文件中要进行传输的位置,必须是非负的
- count:要传输的最大字节数,必须是非负的
-
abstract long transferTo(long position, long count, WritableByteChannel target):将该通道文件的字节传输到给定的可写字节通道。- position:传输开始的文件中的位置; 必须是非负的
- count:要传输的最大字节数; 必须是非负的
- target:目标通道
文件复制的两种方式:
- Buffer
- 使用上述两种方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vHQIGv8W-1679358011078)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Java/NIO-复制文件.png)]
public class ChannelTest {@Testpublic void copy1() throws Exception {File srcFile = new File("C:\\壁纸.jpg");File destFile = new File("C:\\Users\\壁纸new.jpg");// 得到一个字节字节输入流FileInputStream fis = new FileInputStream(srcFile);// 得到一个字节输出流FileOutputStream fos = new FileOutputStream(destFile);// 得到的是文件通道FileChannel isChannel = fis.getChannel();FileChannel osChannel = fos.getChannel();// 分配缓冲区ByteBuffer buffer = ByteBuffer.allocate(1024);while(true){// 必须先清空缓冲然后再写入数据到缓冲区buffer.clear();// 开始读取一次数据int flag = isChannel.read(buffer);if(flag == -1){break;}// 已经读取了数据 ,把缓冲区的模式切换成可读模式buffer.flip();// 把数据写出到osChannel.write(buffer);}isChannel.close();osChannel.close();System.out.println("复制完成!");}@Testpublic void copy02() throws Exception {// 1、字节输入管道FileInputStream fis = new FileInputStream("data01.txt");FileChannel isChannel = fis.getChannel();// 2、字节输出流管道FileOutputStream fos = new FileOutputStream("data03.txt");FileChannel osChannel = fos.getChannel();// 3、复制osChannel.transferFrom(isChannel,isChannel.position(),isChannel.size());isChannel.close();osChannel.close();}@Testpublic void copy03() throws Exception {// 1、字节输入管道FileInputStream fis = new FileInputStream("data01.txt");FileChannel isChannel = fis.getChannel();// 2、字节输出流管道FileOutputStream fos = new FileOutputStream("data04.txt");FileChannel osChannel = fos.getChannel();// 3、复制isChannel.transferTo(isChannel.position() , isChannel.size() , osChannel);isChannel.close();osChannel.close();}
}
分散聚集
分散读取(Scatter ):是指把 Channel 通道的数据读入到多个缓冲区中去
聚集写入(Gathering ):是指将多个 Buffer 中的数据聚集到 Channel
public class ChannelTest {@Testpublic void test() throws IOException{// 1、字节输入管道FileInputStream is = new FileInputStream("data01.txt");FileChannel isChannel = is.getChannel();// 2、字节输出流管道FileOutputStream fos = new FileOutputStream("data02.txt");FileChannel osChannel = fos.getChannel();// 3、定义多个缓冲区做数据分散ByteBuffer buffer1 = ByteBuffer.allocate(4);ByteBuffer buffer2 = ByteBuffer.allocate(1024);ByteBuffer[] buffers = {buffer1 , buffer2};// 4、从通道中读取数据分散到各个缓冲区isChannel.read(buffers);// 5、从每个缓冲区中查询是否有数据读取到了for(ByteBuffer buffer : buffers){buffer.flip();// 切换到读数据模式System.out.println(new String(buffer.array() , 0 , buffer.remaining()));}// 6、聚集写入到通道osChannel.write(buffers);isChannel.close();osChannel.close();System.out.println("文件复制~~");}
}
选择器
基本介绍
选择器(Selector) 是 SelectableChannle 对象的多路复用器,Selector 可以同时监控多个通道的状况,利用 Selector 可使一个单独的线程管理多个 Channel,Selector 是非阻塞 IO 的核心
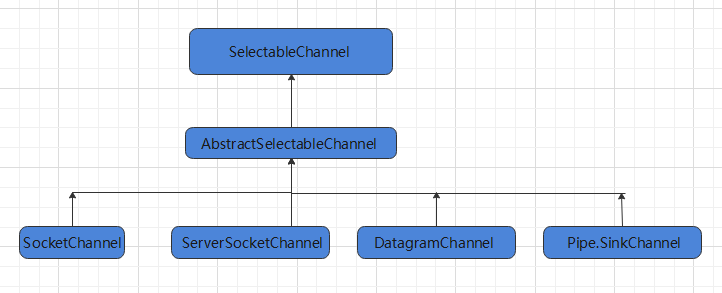
- Selector 能够检测多个注册的通道上是否有事件发生(多个 Channel 以事件的方式可以注册到同一个 Selector),如果有事件发生,就获取事件然后针对每个事件进行相应的处理,就可以只用一个单线程去管理多个通道,也就是管理多个连接和请求
- 只有在连接/通道真正有读写事件发生时,才会进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程
- 避免了多线程之间的上下文切换导致的开销
常用API
创建 Selector:Selector selector = Selector.open();
向选择器注册通道:SelectableChannel.register(Selector sel, int ops, Object att)
- 参数一:选择器,指定当前 Channel 注册到的选择器
- 参数二:选择器对通道的监听事件,监听的事件类型用四个常量表示
- 读 : SelectionKey.OP_READ (1)
- 写 : SelectionKey.OP_WRITE (4)
- 连接 : SelectionKey.OP_CONNECT (8)
- 接收 : SelectionKey.OP_ACCEPT (16)
- 若不止监听一个事件,使用位或操作符连接:
int interest = SelectionKey.OP_READ | SelectionKey.OP_WRITE
- 参数三:可以关联一个附件,可以是任何对象
Selector API:
| 方法 | 说明 |
|---|---|
| public static Selector open() | 打开选择器 |
| public abstract void close() | 关闭此选择器 |
| public abstract int select() | 阻塞选择一组通道准备好进行 I/O 操作的键 |
| public abstract int select(long timeout) | 阻塞等待 timeout 毫秒 |
| public abstract int selectNow() | 获取一下,不阻塞,立刻返回 |
| public abstract Selector wakeup() | 唤醒正在阻塞的 selector |
| public abstract Set selectedKeys() | 返回此选择器的选择键集 |
SelectionKey API:
| 方法 | 说明 |
|---|---|
| public abstract void cancel() | 取消该键的通道与其选择器的注册 |
| public abstract SelectableChannel channel() | 返回创建此键的通道,该方法在取消键之后仍将返回通道 |
| public final Object attachment() | 返回当前 key 关联的附件 |
| public final boolean isAcceptable() | 检测此密钥的通道是否已准备好接受新的套接字连接 |
| public final boolean isConnectable() | 检测此密钥的通道是否已完成或未完成其套接字连接操作 |
| public final boolean isReadable() | 检测此密钥的频道是否可以阅读 |
| public final boolean isWritable() | 检测此密钥的通道是否准备好进行写入 |
基本步骤:
//1.获取通道
ServerSocketChannel ssChannel = ServerSocketChannel.open();
//2.切换非阻塞模式
ssChannel.configureBlocking(false);
//3.绑定连接
ssChannel.bin(new InetSocketAddress(9999));
//4.获取选择器
Selector selector = Selector.open();
//5.将通道注册到选择器上,并且指定“监听接收事件”
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
NIO实现
常用API
-
SelectableChannel_API
方法 说明 public final SelectableChannel configureBlocking(boolean block) 设置此通道的阻塞模式 public final SelectionKey register(Selector sel, int ops) 向给定的选择器注册此通道,并选择关注的的事件 -
SocketChannel_API:
方法 说明 public static SocketChannel open() 打开套接字通道 public static SocketChannel open(SocketAddress remote) 打开套接字通道并连接到远程地址 public abstract boolean connect(SocketAddress remote) 连接此通道的到远程地址 public abstract SocketChannel bind(SocketAddress local) 将通道的套接字绑定到本地地址 public abstract SocketAddress getLocalAddress() 返回套接字绑定的本地套接字地址 public abstract SocketAddress getRemoteAddress() 返回套接字连接的远程套接字地址 -
ServerSocketChannel_API:
方法 说明 public static ServerSocketChannel open() 打开服务器套接字通道 public final ServerSocketChannel bind(SocketAddress local) 将通道的套接字绑定到本地地址,并配置套接字以监听连接 public abstract SocketChannel accept() 接受与此通道套接字的连接,通过此方法返回的套接字通道将处于阻塞模式 - 如果 ServerSocketChannel 处于非阻塞模式,如果没有挂起连接,则此方法将立即返回 null
- 如果通道处于阻塞模式,如果没有挂起连接将无限期地阻塞,直到有新的连接或发生 I/O 错误
代码实现
服务端 :
-
获取通道,当客户端连接服务端时,服务端会通过
ServerSocketChannel.accept得到 SocketChannel -
切换非阻塞模式
-
绑定连接
-
获取选择器
-
将通道注册到选择器上,并且指定监听接收事件
-
轮询式的获取选择器上已经准备就绪的事件
客户端:
- 获取通道:
SocketChannel sc = SocketChannel.open(new InetSocketAddress(HOST, PORT)) - 切换非阻塞模式
- 分配指定大小的缓冲区:
ByteBuffer buffer = ByteBuffer.allocate(1024) - 发送数据给服务端
37 行代码,如果判断条件改为 !=-1,需要客户端 close 一下
public class Server {public static void main(String[] args){// 1、获取通道ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();// 2、切换为非阻塞模式serverSocketChannel.configureBlocking(false);// 3、绑定连接的端口serverSocketChannel.bind(new InetSocketAddress(9999));// 4、获取选择器SelectorSelector selector = Selector.open();// 5、将通道都注册到选择器上去,并且开始指定监听接收事件serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);// 6、使用Selector选择器阻塞等待轮已经就绪好的事件while (selector.select() > 0) {System.out.println("----开始新一轮的时间处理----");// 7、获取选择器中的所有注册的通道中已经就绪好的事件Set selectionKeys = selector.selectedKeys();Iterator it = selectionKeys.iterator();// 8、开始遍历这些准备好的事件while (it.hasNext()) {SelectionKey key = it.next();// 提取当前这个事件// 9、判断这个事件具体是什么if (key.isAcceptable()) {// 10、直接获取当前接入的客户端通道SocketChannel socketChannel = serverSocketChannel.accept();// 11 、切换成非阻塞模式socketChannel.configureBlocking(false);/*ByteBuffer buffer = ByteBuffer.allocate(16);// 将一个 byteBuffer 作为附件【关联】到 selectionKey 上SelectionKey scKey = sc.register(selector, 0, buffer);*/// 12、将本客户端通道注册到选择器socketChannel.register(selector, SelectionKey.OP_READ);} else if (key.isReadable()) {// 13、获取当前选择器上的读就绪事件SelectableChannel channel = key.channel();SocketChannel socketChannel = (SocketChannel) channel;// 14、读取数据ByteBuffer buffer = ByteBuffer.allocate(1024);// 获取关联的附件// ByteBuffer buffer = (ByteBuffer) key.attachment();int len;while ((len = socketChannel.read(buffer)) > 0) {buffer.flip();System.out.println(socketChannel.getRemoteAddress() + ":" + new String(buffer.array(), 0, len));buffer.clear();// 清除之前的数据}}// 删除当前的 selectionKey,防止重复操作it.remove();}}}
}
public class Client {public static void main(String[] args) throws Exception {// 1、获取通道SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("127.0.0.1", 9999));// 2、切换成非阻塞模式socketChannel.configureBlocking(false);// 3、分配指定缓冲区大小ByteBuffer buffer = ByteBuffer.allocate(1024);// 4、发送数据给服务端Scanner sc = new Scanner(System.in);while (true){System.out.print("请说:");String msg = sc.nextLine();buffer.put(("Client:" + msg).getBytes());buffer.flip();socketChannel.write(buffer);buffer.clear();}}
}
AIO
Java AIO(NIO.2) : AsynchronousI/O,异步非阻塞,采用了 Proactor 模式。服务器实现模式为一个有效请求一个线程,客户端的 I/O 请求都是由 OS 先完成了再通知服务器应用去启动线程进行处理
AIO异步非阻塞,基于NIO的,可以称之为NIO2.0BIO NIO AIO
Socket SocketChannel AsynchronousSocketChannel
ServerSocket ServerSocketChannel AsynchronousServerSocketChannel
当进行读写操作时,调用 API 的 read 或 write 方法,这两种方法均为异步的,完成后会主动调用回调函数:
- 对于读操作,当有流可读取时,操作系统会将可读的流传入 read 方法的缓冲区
- 对于写操作,当操作系统将 write 方法传递的流写入完毕时,操作系统主动通知应用程序
在 JDK1.7 中,这部分内容被称作 NIO.2,主要在 Java.nio.channels 包下增加了下面四个异步通道:
AsynchronousSocketChannel、AsynchronousServerSocketChannel、AsynchronousFileChannel、AsynchronousDatagramChannel