
PyTorch入门(七)TensorBoard入门
PyTorch模型的可视化工具:
- Visdom
- TensorBoard
- Pytorchviz
- Netron
TensorBoard简介
TensorBoard是TensorFlow自带的一个强大的可视化工具,也是一个Web应用程序套件,可以记录训练过程的数字、图像等内容,以方便研究人员观察神经网络训练过程。
对于PyTorch等其它深度学习框架来说,目前还没有功能像TensorBoard一样全面的类似工具,一些已有的工具功能也有限,或使用起来比较困难。
TensorBoard提供的机器学习实验所需的可视化功能和工具如下:
- 跟踪和可视化损失及准确率等指标
- 可视化模型图
- 查看权重、偏差或其它张量随时间变化的直方图
- 将嵌入向量投影到较低维度空间
- 显示图片、文字和音频数据
- 剖析TensorFlow程序
如果要使用TensorBoard,首先需要安装tensorflow, tensorboard, tensorboardX, 代码如下:
pip3 install tensorflow
pip3 install tensorboard
pip3 install tensorboardX
其中,tensorboardX这个工具可使得TensorFlow外的其它深度学习框架也可以使用TensorBoard的便捷功能。
TensorBoard目前支持7种可视化,包括Scalars, Images, Audio, Graphs, Distributions, Histograms, Embeddings, 主要功能如下:
- Scalars: 展示训练过程中的准确率、损失值、权重/偏差的变化情况
- Images: 展示训练过程中记录的图像
- Audio: 展示训练过程中记录的音频
- Graphs: 展示模型的数据流图,以及训练在各个设备上消耗的内存和时间
- Distributions: 展示训练过程中记录的数据的分布图
- Histograms: 展示训练过程中记录的数据的柱状图
- Embeddings: 展示词向量的投影分布
启动TensorBoard:
tonsorboard --logdir=./run/
TensorBoard基础操作
- 可视化数值
使用add_scalar方法来记录数字常量,一般使用add_scalar方法来记录训练过程中的loss, arrcuracy, learning rate等数值的变化,直观地监控训练过程。
示例代码:
# import modules
from tensorboardX import SummaryWriter
# add_scalar
writer = SummaryWriter('run/scalar')for i in range(10):writer.add_scalar('指数', 3**i, global_step=i)
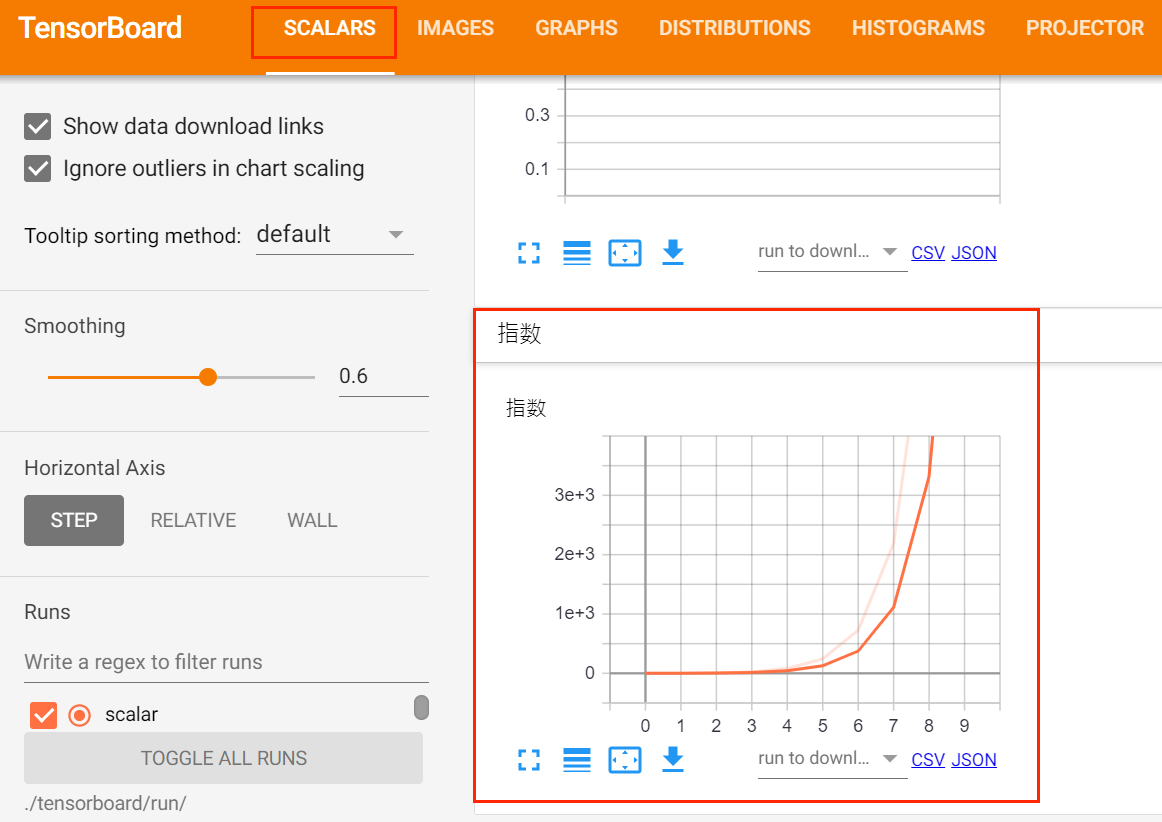
- 可视化图片
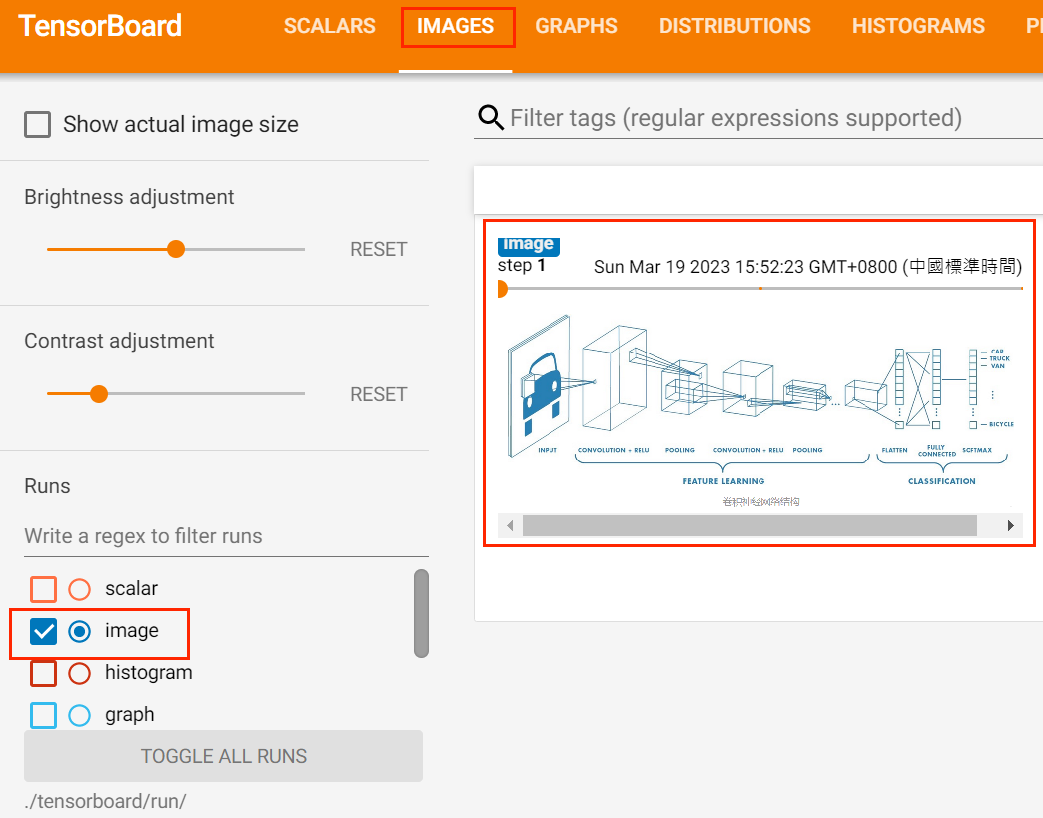
使用add_images方法来记录图像数据,一般会使用add_images来实时观察模型的生成效果,或者可视化分割、目标检测的结果,帮助调试模型。
示例代码:
# add_images
import cv2writer = SummaryWriter('run/image')for i in range(1, 4):writer.add_images('', cv2.cvtColor(cv2.imread('./image/image{}.png'.format(i)), cv2.COLOR_BGR2RGB), global_step=i, dataformats='HWC')
- 可视化统计图
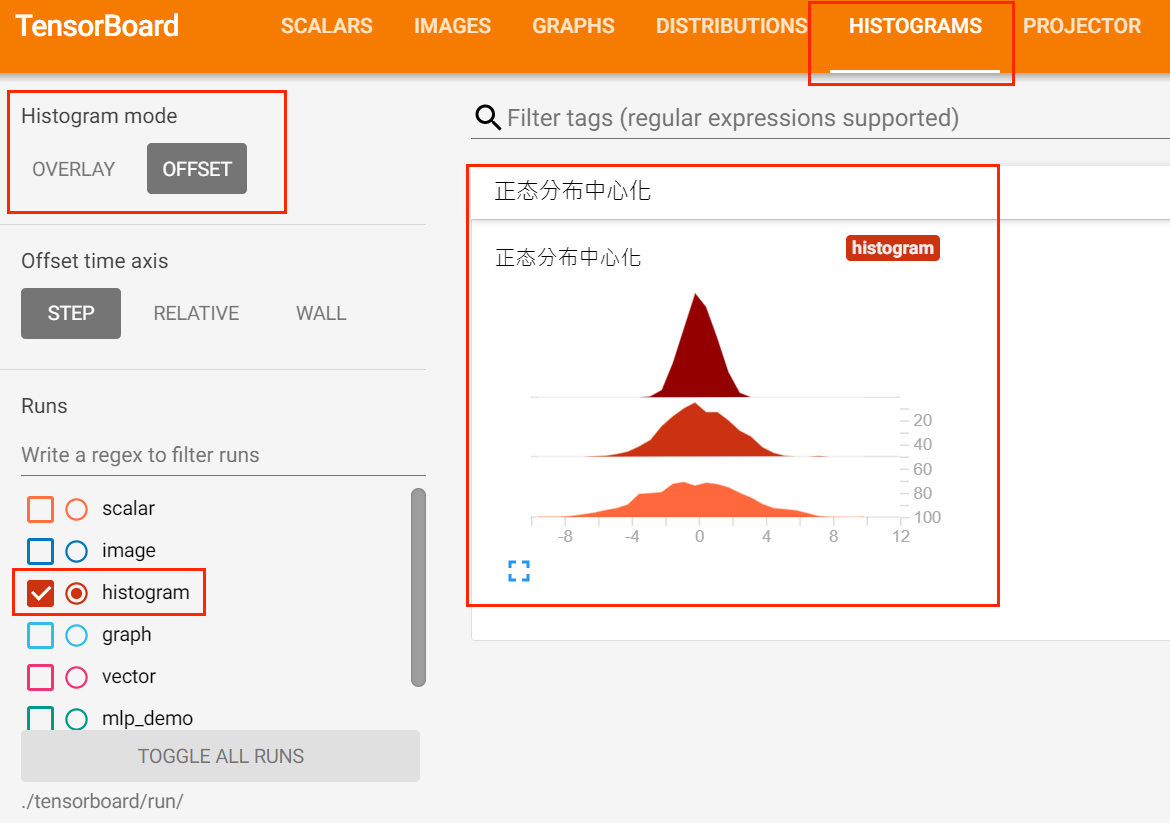
使用add_histogram方法来记录一组数据的直方图。可以通过观察数据、训练参数、特征的直方图了解到它们大致的分布情况,辅助神经网络的训练过程。
示例代码:
# add_histogram
import numpy as npwriter = SummaryWriter('run/histogram')
writer.add_histogram('正态分布中心化', np.random.normal(0, 1, 1000), global_step=1)
writer.add_histogram('正态分布中心化', np.random.normal(0, 2, 1000), global_step=50)
writer.add_histogram('正态分布中心化', np.random.normal(0, 3, 1000), global_step=100)
在TensorBoard可视化界面中,我们会发现DISTRIBUTIONS和HISTOGRAMS两栏,它们都是用来观察数据分布的。在HISTOGRAMS中,同一数据不同步数的直方图可以上下错位排布(OFFSET)也可以重叠排布(OVERLAY)。
4. 可视化模型图
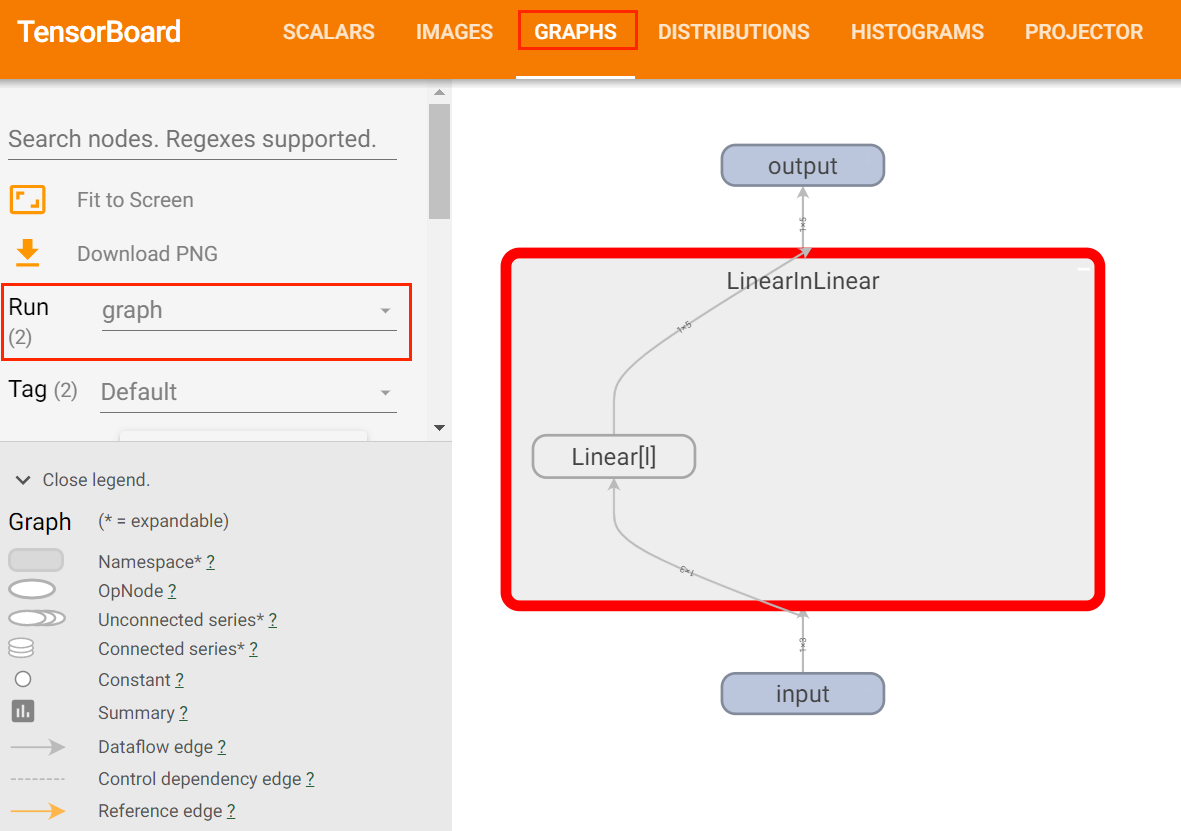
使用add_graph方法来可视化一个神经网络。该方法可以将神经网络模型可视化,显示模型中的操作和网络层。
示例代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as Fdummy_input = (torch.zeros(1, 3),)
writer = SummaryWriter('run/graph')# simple MLP model
class LinearInLinear(nn.Module):def __init__(self):super(LinearInLinear, self).__init__()self.l = nn.Linear(3, 5)def forward(self, x):return self.l(x)writer.add_graph(LinearInLinear(), dummy_input)
- 可视化向量
使用add_embedding方法可以在二维或三维空间可视化Embedding向量。add_embedding方法是一个很实用的方法,不仅可以将高维特征使用PCA, T-SNE等方法降维至二维平面或三维空间,还可以观察每一个数据点在降维前的特征空间的K近邻情况。
下面的例子中我们取MNIST训练集中的前30个数据,将图像展开成一维向量作为Embedding,使用TensorBoardX进行可视化。
示例代码如下:
# add_embedding
import torchvisionwriter = SummaryWriter('run/vector')
mnist = torchvision.datasets.MNIST('./', download=False)
writer.add_embedding(mnist.data.reshape((-1, 28*28))[:30, :],metadata=mnist.targets[:30],label_img = mnist.data[:30, :, :].reshape((-1, 1, 28, 28)).float()/255,global_step=0)
可以发现,虽然还没有做任何特征提取工作,但MNIST数据已经呈现出聚类的效果,相同数字之间距离更近一些。
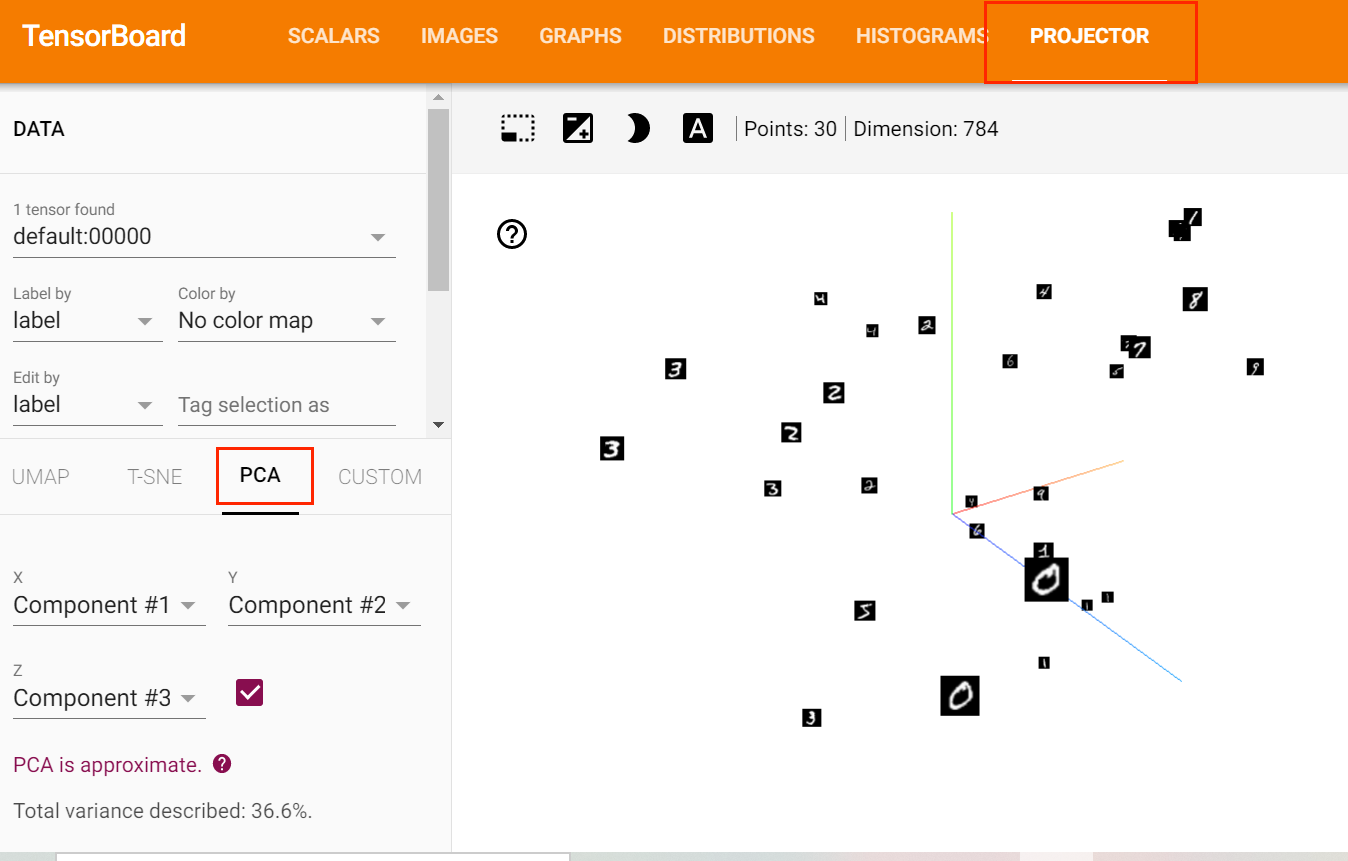
TensorBoard实战
- 例子1:在模型训练过程中记录loss和accuracy. Python示例代码如下:
# -*- coding: utf-8 -*-
import torch
from numpy import vstack
from numpy import argmax
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder, LabelBinarizer
from sklearn.metrics import accuracy_score
from torch.optim import SGD, Adam
from torch.utils.data import Dataset, DataLoader, random_split
from torch.nn import Linear, ReLU, Softmax, Module, CrossEntropyLoss
from torch.nn.init import kaiming_uniform_, xavier_uniform_from tensorboardX import SummaryWriter# dataset definition
class CSVDataset(Dataset):# load the datasetdef __init__(self, path):# load the csv file as a dataframedf = read_csv(path, header=None)# store the inputs and outputsself.X = df.values[:, :-1]self.y = df.values[:, -1]# ensure input data is floatsself.X = self.X.astype('float32')# label encode target and ensure the values are floatsself.y = LabelEncoder().fit_transform(self.y)# number of rows in the datasetdef __len__(self):return len(self.X)# get a row at an indexdef __getitem__(self, idx):return [self.X[idx], self.y[idx]]# get indexes for train and test rowsdef get_splits(self, n_test=0.3):# determine sizestest_size = round(n_test * len(self.X))train_size = len(self.X) - test_size# calculate the splitreturn random_split(self, [train_size, test_size])# model definition
class MLP(Module):# define model elementsdef __init__(self, n_inputs):super(MLP, self).__init__()# input to first hidden layerself.hidden1 = Linear(n_inputs, 5)kaiming_uniform_(self.hidden1.weight, nonlinearity='relu')self.act1 = ReLU()# second hidden layerself.hidden2 = Linear(5, 6)kaiming_uniform_(self.hidden2.weight, nonlinearity='relu')self.act2 = ReLU()# third hidden layer and outputself.hidden3 = Linear(6, 3)xavier_uniform_(self.hidden3.weight)# forward propagate inputdef forward(self, X):# input to first hidden layerX = self.hidden1(X)X = self.act1(X)# second hidden layerX = self.hidden2(X)X = self.act2(X)# output layerX = self.hidden3(X)return Xclass Model(object):def __init__(self, file_path, model):self.writer = SummaryWriter('./run/mlp_demo')# load the datasetdataset = CSVDataset(file_path)# calculate splittrain, test = dataset.get_splits()# prepare data loadersself.train_dl = DataLoader(train, batch_size=4, shuffle=True)self.test_dl = DataLoader(test, batch_size=1024, shuffle=False)# modelself.model = model# train the modeldef train(self):criterion = CrossEntropyLoss()optimizer = Adam(self.model.parameters())# enumerate epochsfor epoch in range(100):init_loss = torch.Tensor([0.0])# enumerate mini batchesfor i, (inputs, targets) in enumerate(self.train_dl):targets = targets.long()# clear the gradientsoptimizer.zero_grad()# compute the model outputyhat = self.model(inputs)# calculate lossloss = criterion(yhat, targets)# credit assignmentloss.backward()print("epoch: {}, batch: {}, loss: {}".format(epoch, i, loss.data))init_loss += loss.data# update model weightsoptimizer.step()self.writer.add_scalar('Loss/Train', init_loss/(i+1), epoch)test_accuracy = self.evaluate_model()self.writer.add_scalar('Accuracy/Test', test_accuracy, epoch)# evaluate the modeldef evaluate_model(self):predictions, actuals = [], []for i, (inputs, targets) in enumerate(self.test_dl):# evaluate the model on the test setyhat = self.model(inputs)# retrieve numpy arrayyhat = yhat.detach().numpy()actual = targets.numpy()# convert to class labelsyhat = argmax(yhat, axis=1)# reshape for stackingactual = actual.reshape((len(actual), 1))yhat = yhat.reshape((len(yhat), 1))# storepredictions.append(yhat)actuals.append(actual)predictions, actuals = vstack(predictions), vstack(actuals)# calculate accuracyacc = accuracy_score(actuals, predictions)return accif __name__ == '__main__':# train the modelModel('iris.csv', MLP(4)).train()
在训练过程中的训练集的损失值以及验证集的准确率如下:
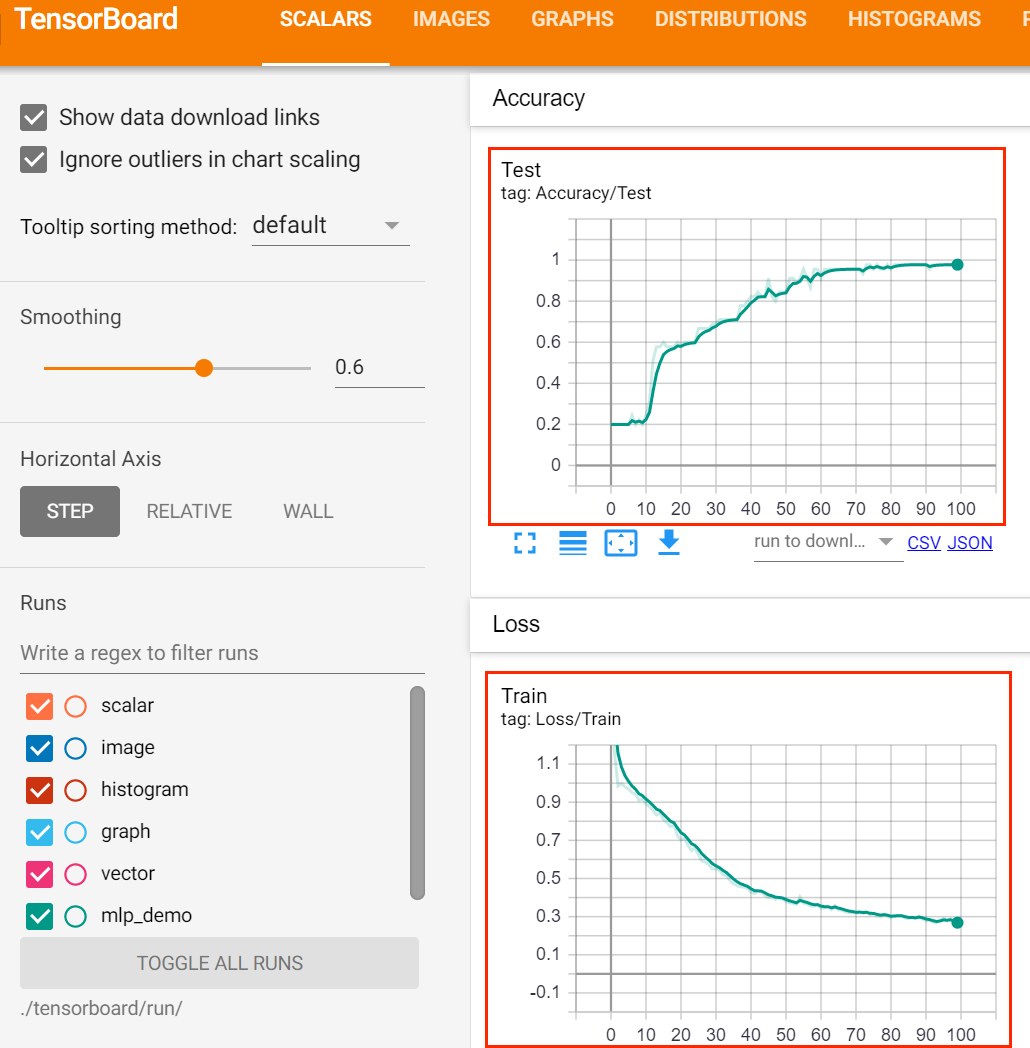
- 例子2: 利用TensorBoard查看ONNX文件
需安装Python第三方模块onnx, Python代码如下:
# -*- coding: utf-8 -*-
from tensorboardX import SummaryWriterwith SummaryWriter('./run/onnx') as w:w.add_onnx_graph('iris.onnx')
在TensorBoard中选择Graphs, Run选项选择onnx,模型图如下:
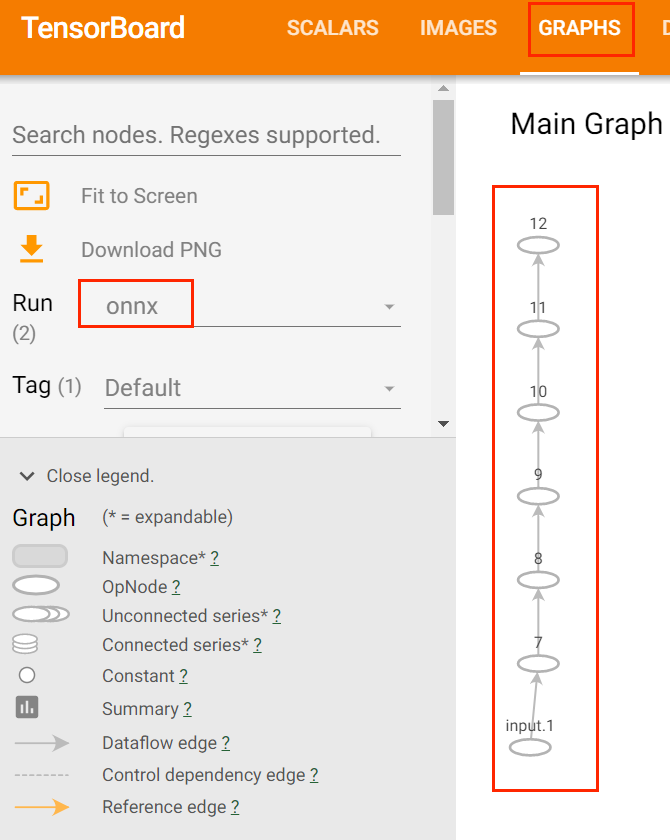
从中可以看出,TensorBoard对于ONNX模型文件支持不是太好,可以尝试使用Netron.
参考文献
- tensorboardX Tutorials: https://tensorboardx.readthedocs.io/en/latest/tutorial.html#tutorials
- 动手学PyTorch深度学习建模与应用,王国平著
- PyTorch 使用 TensorboardX 进行网络可视化:https://www.pytorchtutorial.com/pytorch-tensorboardx/