
5. 使用Antlr4的Listener模式实现一个简单的整数计算器
1. 为什么是Listener模式 ?
- 学习完如何使用Antlr4的visitor模式实现一个简单的整数计算器后,发现其本质:
- 使用visitor模式实现对parse tree的DFS
- 其中,visitor的visitCtx()方法定义了对ParserRuleContext(简称Ctx)的具体操作
- 对parse tree中每个Ctx的的遍历,其实包含两个动作:
- 进入Ctx对应的rule,以向下递归遍历子节点
- 递归遍历完子节点后、返回父节点前,需要退出Ctx对应的rule
- 若将进入/退出rule看做事件,则可以使用listener对事件进行监听,然后按需对事件做出响应
- 笔者想,这就是为什么Antrl4会支持通过Listener模式遍历parse tree的原因
2. 实战前的理论学习
2.1 Listener
- 与visitor模式一样,Antrl4也为listener模式生成了以Listener为结尾的Java文件:
CalculatorListener接口,及其默认的、空实现类CalculatorBaseListener
CalculatorListener接口
-
CalculatorListener接口的代码如下:
- 继承antlr-runtime提供的
ParseTreeListener接口 - 为每个Ctx创建对应的监听器方法enterCtx()、exitCtx()
public interface CalculatorListener extends ParseTreeListener {// 进入由CalculatorParser.prog()方法生成的parse tree// 向下递归遍历ProgContext的子节点前,将调用该方法void enterProg(CalculatorParser.ProgContext ctx);// 退出由alculatorParser.prog()方法生成的parse tree// 完成子节点的递归遍历后、退出ProgContext前,将调用该方法void exitProg(CalculatorParser.ProgContext ctx);void enterPrintExpr(CalculatorParser.PrintExprContext ctx);void exitPrintExpr(CalculatorParser.PrintExprContext ctx);... // 其他的enterCtx()和exitCtx()方法,与上面的含义相似,不过多展示 } - 继承antlr-runtime提供的
ParseTreeListener接口
- 根据源码注释,ParseTreeListener描述了以listener模式遍历parse tree时,被
ParseTreeWalker触发的方法的最小核心 - 在笔者看来,就是遍历过程中,一定会使用到的监听器方法
public interface ParseTreeListener {// 定义访问叶子节点和ErrorNode时需要执行的操作void visitTerminal(TerminalNode node);void visitErrorNode(ErrorNode node);// 定义进入或退出每个rule都需要执行的通用操作void enterEveryRule(ParserRuleContext ctx);void exitEveryRule(ParserRuleContext ctx); }
为什么叶子节点和ErrorNode没有enter、exit方法?
-
叶子节点作为最底层节点,没有子节点可以向下递归遍历,更别提递归后的退出
-
因此,对叶子节点的遍历没有enter和exit事件,只有一个访问操作
-
至于ErrorNode,看源码定义,它应该是一种典型的叶子节点,所以只有一个访问操作
public class ErrorNodeImpl extends TerminalNodeImpl implements ErrorNode {
CalculatorBaseListener类
- CalculatorBaseListener类的代码如下,它为CalculatorListener接口中的所有方法提供一个默认的空实现
- 自定义的Listener可以继承CalculatorBaseListener,并有选择地重写这些方法
@SuppressWarnings("CheckReturnValue") public class CalculatorBaseListener implements CalculatorListener {// CalculatorListener中为Ctx定义的监听器方法,只展示部分@Override public void enterProg(CalculatorParser.ProgContext ctx) { }@Override public void exitProg(CalculatorParser.ProgContext ctx) { }... // 其他方法省略// CalculatorListener从ParseTreeListener接口继承来的通用方法@Override public void enterEveryRule(ParserRuleContext ctx) { }@Override public void exitEveryRule(ParserRuleContext ctx) { }@Override public void visitTerminal(TerminalNode node) { }@Override public void visitErrorNode(ErrorNode node) { } }
2.2 如何监听enter和exit?
Ctx的enterRule()、exitRule()方法
-
从对Parser的学习可知,parser rule或者添加了label的rule element都将对应一个Ctx,且它们都将直接或间接继承ParserRuleContext类
-
ParserRuleContext类中有两个与listener模式有关的空方法:
public void enterRule(ParseTreeListener listener) { } public void exitRule(ParseTreeListener listener) { } -
以ProgContext为例,它重写了上述两个方法:调用listener的监听器方法对enter和exit事件进行处理
public static class ProgContext extends ParserRuleContext {... // 其他代码省略@Overridepublic void enterRule(ParseTreeListener listener) {if ( listener instanceof CalculatorListener ) ((CalculatorListener)listener).enterProg(this);}@Overridepublic void exitRule(ParseTreeListener listener) {if ( listener instanceof CalculatorListener ) ((CalculatorListener)listener).exitProg(this);} }
ParseTreeWalker:触发事件并调用listener处理事件
-
listener本身并不负责parse tree的遍历,parse tree的遍历由
ParseTreeWalker.walk()方法实现 -
以listener模式遍历parse tree,触发遍历的核心代码如下:
ParseTreeWalker walker = new ParseTreeWalker(); walker.walk(listener, parseTree); -
walk()方法会在遍历parse tree的过程中,主动地、间接地触发每个Ctx对应的监听器方法
public void walk(ParseTreeListener listener, ParseTree t) {if ( t instanceof ErrorNode) {listener.visitErrorNode((ErrorNode)t);return;}else if ( t instanceof TerminalNode) {listener.visitTerminal((TerminalNode)t);return;}RuleNode r = (RuleNode)t;// 触发enter事件,最终将调用listener.enterCtx()方法处理enter事件 enterRule(listener, r); int n = r.getChildCount();for (int i = 0; i -
enterRule()方法的实现如下:
protected void enterRule(ParseTreeListener listener, RuleNode r) {ParserRuleContext ctx = (ParserRuleContext)r.getRuleContext();// 若进入每个parser rule都需要执行一些通用操作,则可以在自定义的listener中重写该方法listener.enterEveryRule(ctx); // 实际将调用listener.enterCtx()方法ctx.enterRule(listener); } -
至此,触发并监听enter事件的调用链正式形成:
walker.walk()→\rightarrow→walker.enterRule(listener, r)→\rightarrow→ctx.enterRule(listener)→\rightarrow→listener.enterCtx() -
同样的,触发并监听exit事件的调用链为:
walker.walk()→\rightarrow→walker.exitRule(listener, r)→\rightarrow→ctx.exitRule(listener)→\rightarrow→listener.exitCtx()
3. 代码实战
3.1 定义Listenser
3.1.1 一般只需重写exitCtx()方法
- 遍历parse tree中parser rule对应的节点时,会触发enter rule和exit rule两个事件,但我们一般只需要重写exit rule对应的exitCtx()方法
- 笔者认为,这是因为对parse tree进行DFS,只有完成了子节点的访问并获取到所需信息,才能完成当前节点的操作
- 以语法规则stat解析
4 - 3,得到的parse tree如下:
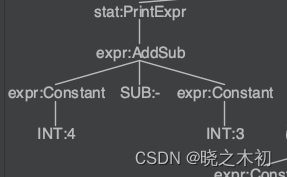
- 按照listener模式下parse tree的访问规则,对AddSubContext的访问顺序为:
enterRule(listener, addSubCtx)→\rightarrow→walk(listener, constantLeft)→\rightarrow→walk(listener, subTerminalNode)→\rightarrow→walk(listener, constantRight)→\rightarrow→exitRule(listener, addSubCtx)
- 从访问顺序可以看出,获得左右操作数的值是在
enterAddSub()之后,因此要想进行4 - 3的计算,就必须放在exitAddSub()中进行
3.1.2 自定义listener的代码实现
-
继承Antlr4编译得到的
CalculatorBaseListener类,按需重写某些方法,主要是exitCtx()方法,以实现一个简单整数计算器public class CalculatorListenerImpl extends CalculatorBaseListener {// 记录每个ctx对应的属性,这里的属性是double类型的数值,可以用于实现表达式的计算private final ParseTreePropertyctxs = new ParseTreeProperty<>();// 存储变量名和对应的值,若存储ctx会导致变量的值在后续表达式中无法获取private final HashMap -
从实现代码可以看出:
- 除无
ProgContext和AssignContext外,其他Ctx都是在exitCtx()方法中得到当前节点的属性,并存入ParseTreeProperty中 - ParseTreeProperty是antlr-runtime提供的,专门用来存储parse tree节点与其属性的哈希表
protected Map - 除无
3.1.3 对变量的操作
对变量的操作是比较特殊且容易出错的地方,这里特别做一下分析
- 对变量的赋值操作:
- 这里的变量是一个TerminalNode而非VariableContext,因此无法使用ParseTreeProperty存储其属性
- 其次,变量可能在后续的expr中被使用,只要变量名相同,则应该获取到赋值操作后的变量值,或者未经历赋值操作的默认值
0 - 因此,应该单独开辟一块内存,并在赋值操作时缓存变量名和对应的值
- 访问变量,即访问VariableContext
- 可以根据变量名,从内存中获取变量的值或默认值
0,并将VariableContext及其值存入ParseTreeProperty中 - 以便父节点能在需要时,从ParseTreeProperty中获取变量的值
- 可以根据变量名,从内存中获取变量的值或默认值
- 疑问:为什么不直接从内存中,根据变量名获取变量的值?
- 以AddSubContext,如果想根据变量名获取变量的值,则需要在遍历子节点时,判断子节点是否为VariableContext类型
- 与直接从ParseTreeProperty获取左右操作数的值相比,上述方案会使代码变得复杂且失去通用性
Integer left = ctxs.get(ctx.expr(0)); Integer right = ctxs.get(ctx.expr(1));
3.2 使用自定义的Listener遍历parse tree
-
与visitor模式一样,首先需要将输入字符流,通过词法分析、语法分析转化为一棵parse tree
-
与visitor模式不同的是,listener模式对parse tree进行遍历的入口方法是
ParseTreeWalker.walk() -
使用自定义的Listener遍历parse tree的代码如下:
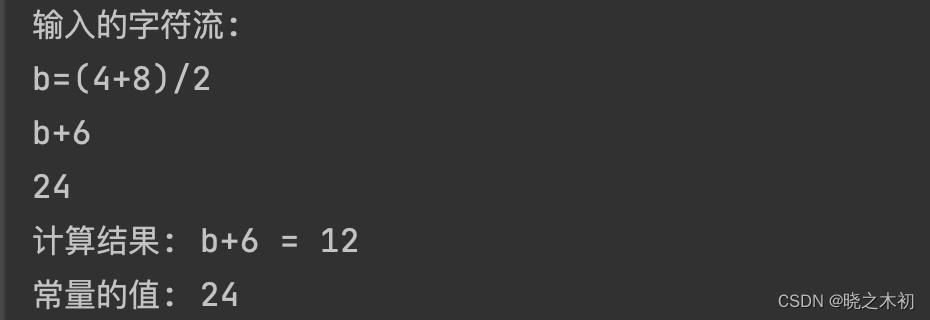
public static void main(String[] args) {String input = "b=(4+8)/2\n"+ "b+6\n"+ "24";System.out.println("输入的字符流:\n" + input);// 词法分析,获取tokenCharStream charStream = CharStreams.fromString(input);CalculatorLexer lexer = new CalculatorLexer(charStream);CommonTokenStream tokens = new CommonTokenStream(lexer);// 语法分析,获取parse treeCalculatorParser parser = new CalculatorParser(tokens);ParseTree parseTree = parser.prog();// 使用自定义的Listener访问parse treeParseTreeWalker walker = new ParseTreeWalker();walker.walk(new CalculatorListenerImpl(), parseTree); } -
最终执行结果如下,符合预期:
3.3 listener模式的遍历过程详解
-
以
4+8/2为例,得到的parse tree如下:
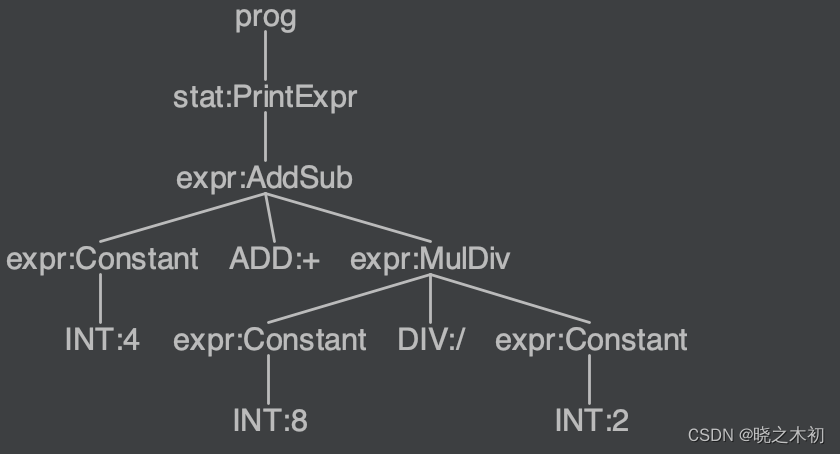
-
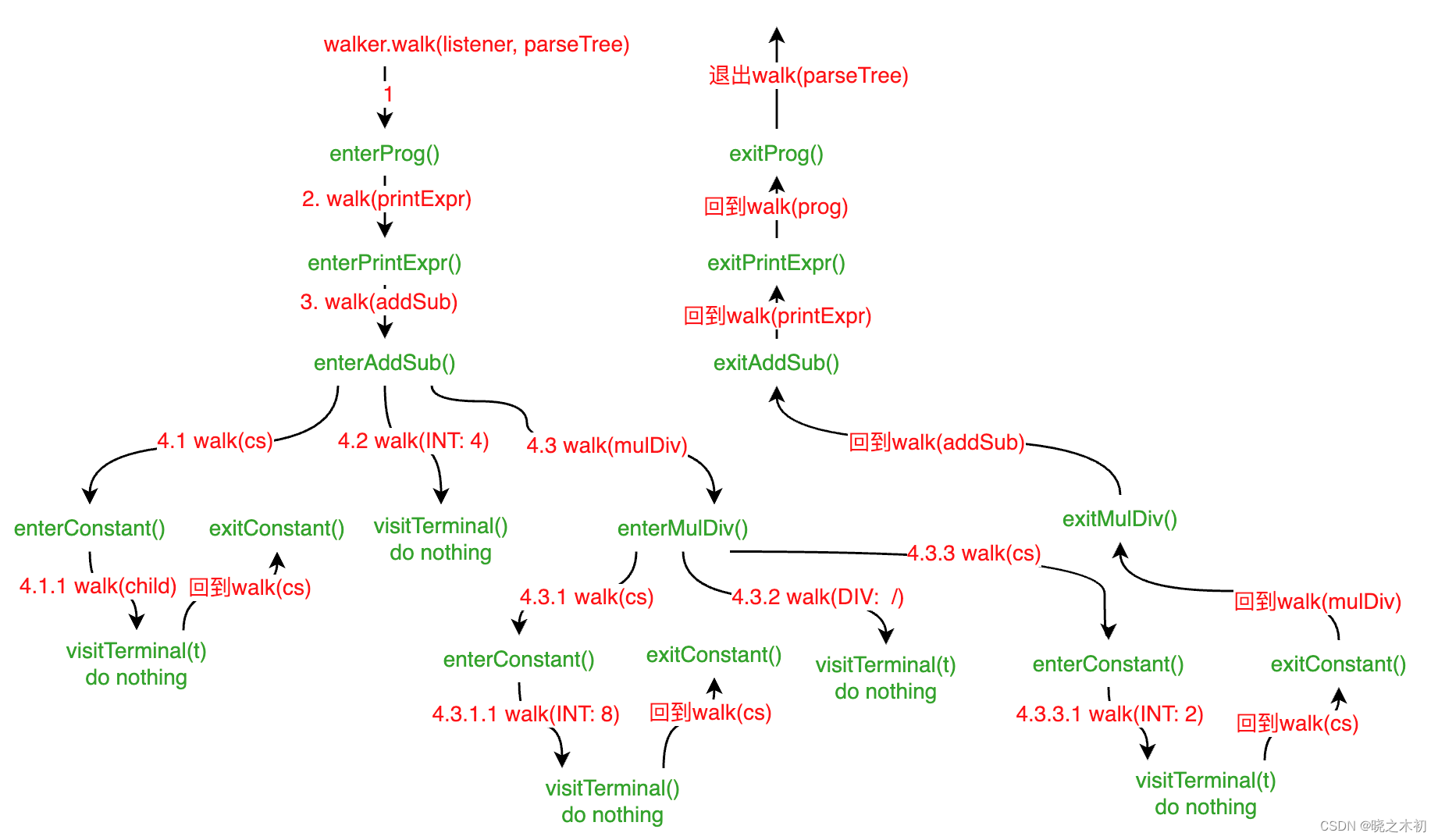
debug跟踪代码的执行流程,发现listener模式对parse tree的遍历过程大致如下:
4. Visitor模式 vs Listener模式
- visitor模式 vs listener模式,笔者有以下节点体会:
- 二者都是在parse tree的DFS过程中,对节点执行某些操作
- 最直观的差异: visitor模式有返回值,listener模式没有返回值,需要借助ParseTreeProperty存储Ctx的属性
- visitor模式中,parse tree的DFS需要开发人员自己掌控,可以借助
visit()或visitChildern()方法递归遍历子节点。listener模式中,parse tree的DFS由antlr-runtime提供的ParseTreeWalker.walk()方法实现,开发人员只需要关注enter/exit rule事件的处理逻辑 - 个人更喜欢visitor模式,无需考虑Ctx属性的存储,直接使用递归调用的返回值即可,整个代码逻辑更加简单易懂
- 官网对二者差异的描述如下:
The biggest difference between the listener and visitor mechanisms is that listener methods are called independently by an ANTLR-provided walker object, whereas visitor methods must walk their children with explicit visit calls. Forgetting to invoke visitor methods on a node’s children, means those subtrees don’t get visited.
- 大意:
- listener模式中,Antlr提供的walker对象(
ParseTreeWalker.walk())负责调用监听器方法,以实现节点的递归遍历;而visitor模式中,必须由开发者显式调用visit方法才能实现节点的递归遍历 - visitor模式下,一旦忘记对子节点使用visit方法,则对应的子树将不会被遍历
- listener模式中,Antlr提供的walker对象(
- 换个角度看:在visitor模式中,开发人员可以控制parse tree的遍历。而listener模式中,开发人员只能对树的遍历做出发应
In visitor pattern you have the ability to direct tree walking while in listener you are only reacting to the tree walker.
5. 后记
- 至此,除了缺少对Antlr4语法的总结之外,笔者觉得对Antlr4的学习可以暂告一个段落
- 语法的学习,笔者更喜欢边用边学,在实践中加深对Antlr4语法的理解
- 后续的话,将结合Presto的SQL语法,学习Antlr4在大数据开源组件中的使用