
GeoWave
以下部分内容是翻译的。英文太烂,应该是很不准确的。
一、什么是GeoWave
GeoWave是一个开源库,它将数据从分布式数据库摄取进来,以键值对的形式存储,并建立多维度索引,然后提供给GeoServer等外部应用。经过GeoWave的针对性处理,分布式数据库中的数据能够为地理空间信息软件所用,并具有良好的性能。可见GeoWave是一种中间件,将分布式计算框架与现代地理空间软件连接起来,在二者之间架起一道桥梁,提供存储、检索和分析海量的地理空间数据集的服务,就好像PostGIS为PostgreSQL所做的工作一样。从开发人员的角度来看,GeoWave实现了 GeoTools 工具包的矢量数据提供程序,以便从分布式环境中读取特征(几何和属性)。
注:PostGIS是PostgreSQL的空间数据库扩展,它使得地理信息对象可以在sql里面进行检索和操作。
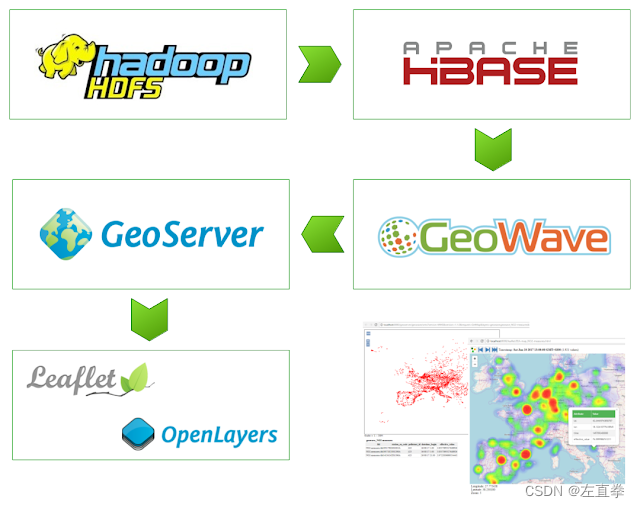
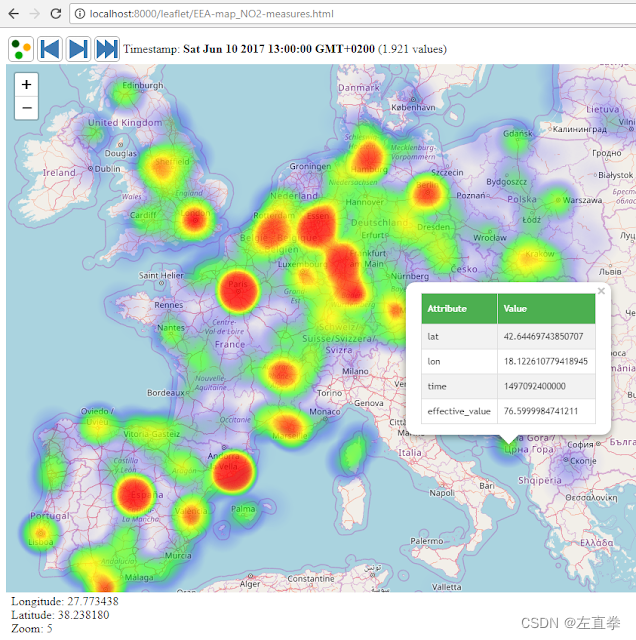
如上图所示,GeoWave在HBase和GeoServer之间充当中间件,将HBase的数据处理后提供给GeoServer,GeoServer发布成地图服务,前端调用该服务绘制出热点图。所谓的处理,是将数据从HBase等分布式数据库中摄取进GeoWave自身的存储库,建立索引,其实就相当于优化过了,然后再提供给GeoServer等外部应用。
注:Hbase是面向列的存储结构,而实际存储单元里存储的都是KeyValue结构。在看Hbase的API中,发现Hbase的API中就有KeyValue类,这个KeyValue类就是Hbase中数据存储的基本类型。
二、为啥要用GeoWave
(一)GeoWave的优势
小可斗胆总结如下:
1、速度快,性能好
如前所述,GeoWave通过摄取,将数据从分布式数据库读取到自身存储库,并建立索引,这些索引是多维的,说明适用性很广;
2、存储结构为键值对,使用起来十分方便;
3、为键/值存储方式添加了对地理对象和地理空间运算符的支持;
4、提供 GeoServer 插件以允许通过 OGC 标准服务共享和可视化来自键/值存储的地理空间数据
5、为地理空间数据的分布式处理和分析提供Map-Reduce输入和输出格式
6、基于GeoTools的扩展模型,能够天然集成兼容GeoTools的系统,如GeoServer和UDi;反过来,也能摄取GeoTools兼容的数据源。
7、是一个开源框架
8、支持多种后端:
Apache Accumulo
Apache Cassandra
Apache HBase
Apache Kudu
Google Cloud Bigtable
Redis
RocksDB
Apache Accumulo® 是一种排序的分布式键/值存储,可提供强大、可扩展的数据存储和检索。
(二)GeoServer需要中间件连接地理空间信息存储库
GeoServer是地图服务器,简而言之,就是对外提供地图服务,好比ArcgisServer。那么,既然ArcgisServer可以直接连oracle等数据库,为何GeoServer不能直接连接HBase,偏偏要在中间通过GeoWave充当中间件?
从我查找的资料看,GeoServer还真不能直接连HBase。它不通过GeoWave连接,也要通过其他中间件,比如GeoServer也可以通过一个叫GeoMesa的插件与HBase连接,总之是要有中间件。事实上,oracle其实也并不天然支持空间数据,需要附加Arcgis的空间数据类库才可以。这个类库,其实也相当于一个中间件。中间件的作用很好理解,在应用与数据库或操作系统之间架起一道桥梁,屏蔽底层大量细节,提供数据适配和转换,减轻应用复杂度等。正因为有了GeoWave等中间件,GeoServer才能读取HBase里的数据,然后通过地图服务的形式供外部访问和使用。
(三)GeoWave与GeoMesa的比较
既然GeoWave和GeoMesa都是GeoServer与分布式数据库之间的中间连接件,它们相比究竟如何?
二者都是开源的地理空间大数据框架。在性能表现方面:
1、GeoMesa查找大结果集的表现较好,GeoWave查找小结果集表现更佳;
2、GeoMesa查找时空小范围表现较好(如两周或者更短的时间范围),GeoWave查找时空大范围表现较好;
3、GeoMesa在处理非点(则应该是线、面)数据集的案例中表现较好,而GeoWave则对点数据处理得很好?
4、GeoWave 在多租户用例中优于 GeoMesa。
结论就是,GeoWave和GeoMesa都是处理地理空间大数据的框架,二者都可以选用作为处理地理空间大数据解决方案。如果是要搞一个项目,需要用到许多查询,那建议你使用GeoWave。在许多查询的情况下,GeoMesa有较为严重的性能问题。不过,GeoMesa在开源方面比GeoWave成熟,尽管相差并不太大。GeoWave和GeoMesa可以协作、共用,不是非此即彼的关系。实际上,我们可以将 GeoMesa 和 GeoWave 迭代器安装在同一个 Accumulo 集群上,并将某些数据保存在 GeoMesa 表中,同时将其他数据保存在 GeoWave 表中。 这些技术都是兼容的。
三、GeoWave的技术点
(一)特点
1、伸缩性
GeoWave设计成既可以在单个节点上运行,也可以根据需要扩展成多个数据或资源处理节点。利用分布式计算集群和服务器端细粒度过滤,GeoWave在包含数十亿空间特征值(feature)的数据集中进行交互处理或特定查询性能超卓,准确度百分百。
2、可插拔后端
GeoWave致力于成为一个多维度的索引层,放置于任意排序的键值对存储库之上。最初选用Accumulo作为目标架构,之后陆续增加了其他一些服务器后端。实际上,所有允许前置范围搜索的存储库都可以直接作为GeoWave的扩展插件。
3、模块化框架
GeoWave的架构设计成通过接口定义,特别容易使用函数式单元进行扩展。GeoWave提供了涵盖大部分情况的接口的默认实现,但也容许轻松扩展和平台集成,弥合分布式技术之间的鸿沟,降低程序员学习成本。意图很明显,一方面90%的功能都已经具备,开箱即用;但也可以轻松扩展,方便集成其他平台。
4、自描述数据
GeoWave将操作数据所需的信息,比如配置和格式,存储在自身的数据库中。这使得软件可以编程去查询单个或一组GeoWave实例的所有数据,不需要客户端、应用服务器,或其他扩展存储库配置。
(二)架构
1、键结构(Key Structure)
GeoWave采用键值对形式存储数据。

键结构由两个接口描述:GeoWaveKey 和 GeoWaveValue。 如何使用这些结构存储 GeoWave 数据,取决于数据存储如何实现,因此最终结构可能因实现而异。
2、数据存储(Data Stores)
数据存储是GeoWave功能的集中体现。其中包括元数据,统计信息,索引和适配器。GeoWave数据存储通常使用一组配置参数来访问,这些参数定义了如何连接底层的键值对存储库。使用命令行界面工具(Command-Line Interface,CLI)时,配置好的这些参数可以起一个名字,在本地保存下来,方便之后继续使用。
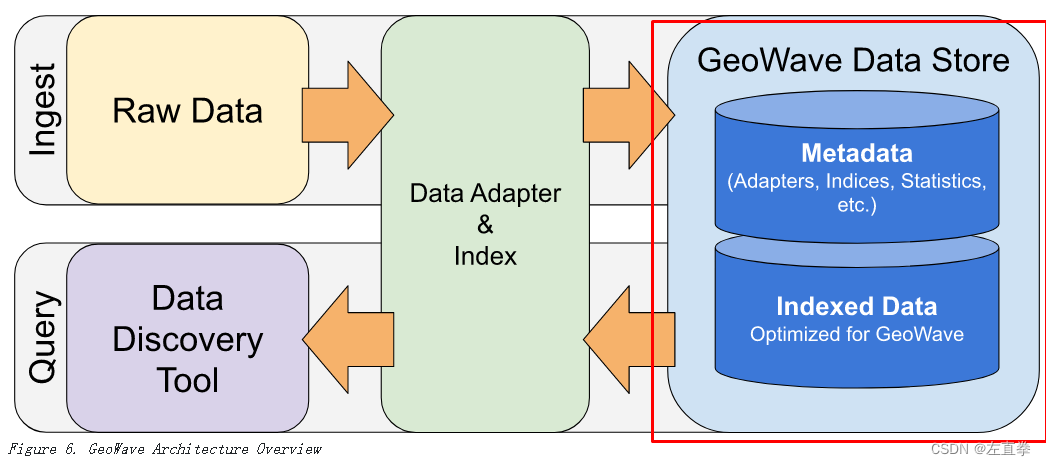
GeoWave 数据存储由几个不同的组件组成,每个组件管理系统的不同方面,例如适配器存储、索引存储、统计存储等。大多数时候,直接使用这些组件不是必需的,因为大多数 GeoWave 任务 可以通过使用 DataStore 接口来完成。
3、索引(Indices)
GeoWave查询性能很快,是因为数据建立了索引。索引使用一组给定的维度来确定数据的存储顺序。索引由两部分组成:通用索引模型和索引策略。其中通用索引模型定义维度数,索引策略则规定这些维度如何用于构建数据的存储。比如,一个时空索引可能会有3个维度:纬度、经度和时间,则通用索引模型就包含这3个维度。数据适配器负责将原始数据的属性与通用索引模型中的维度相关联。当数据添加到 GeoWave 时,系统会应用索引策略来确定数据的 Partition Key 和 Sort Key。 确定使用哪种索引策略取决于数据的性质和将要执行的查询类型。
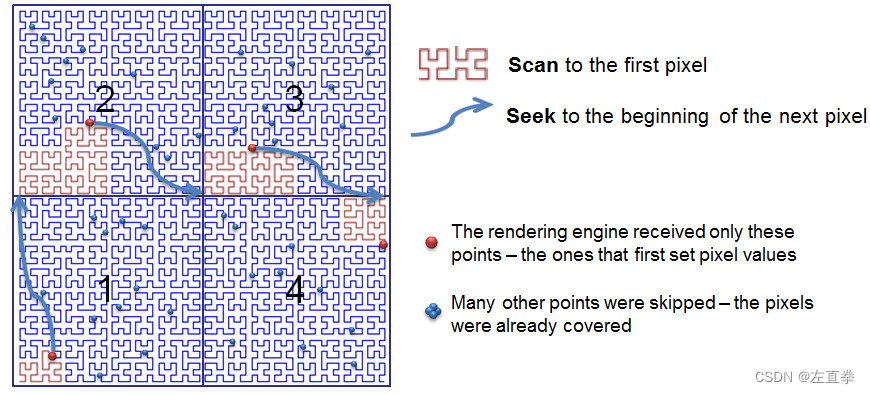
不知为何,介绍GeoWave的索引的图,无一例外地都是弯弯曲曲的,这是什么鬼?可能是地理空间数据的一种特征吧。上图所示,感觉这些索引很像链和指针。
4、适配器/数据类型
为了处理多种输入数据类型,适配器需要描述输入数据类型,以便转换成GeoWave可以理解的格式。除此之外,GeoWave提供默认支持SimpleFeatures的数据适配器实现,范围覆盖大部分的矢量数据。
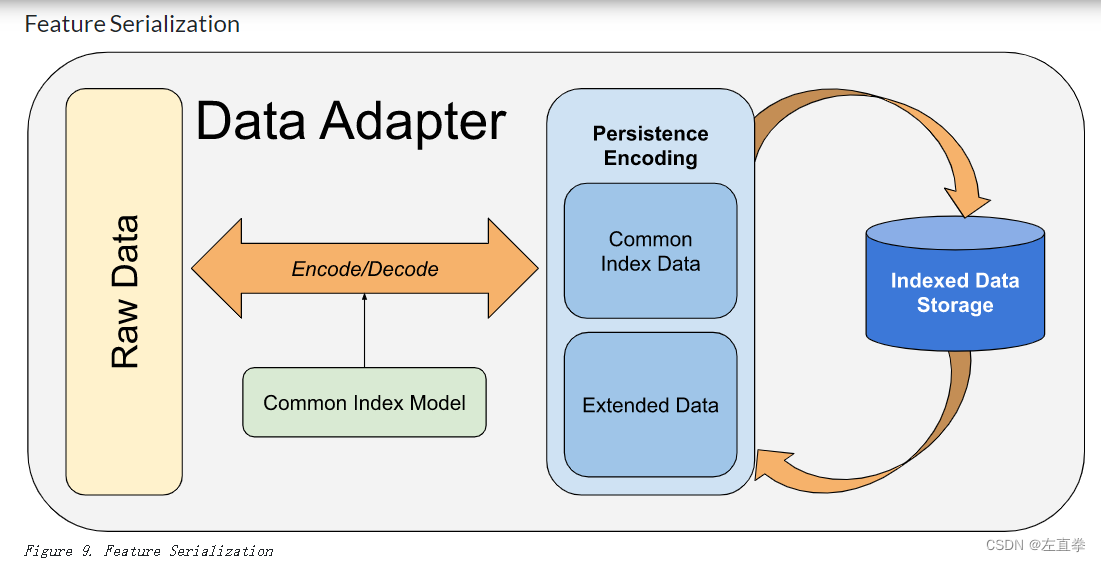
一个例子是从shapefile文件摄取数据到GeoWave。在摄取过程中,会创建适配器描述和转换shapefile文件中所有的feature,使得GeoWave能够以优化的格式索引并存储这些数据。当这些数据将来被用户读取,适配器再将它们转换回SimpleFeature数据。
已经添加到GeoWave的数据,拥有相应的适配器,常被视为一种类型(type)。每种类型都有一个名称,方便与数据交互。本文约定,这个名称就称为类型名称(type name)。
在GeoWave,适配器和类型经常是等同或可以互换的。
(三)统计
由于GeoWave经常处理大量的数据,会导致成本高昂地计算数据集统计信息。为了解决这个问题,GeoWave有一个统计存储功能,可通过配置,保持对索引、数据类型和字段的统计信息进行跟踪,查找时无须遍历整个数据集。GeoWave提供了一系列开箱即用的功能,足以应付大部分情况。其中包括:
1)属性范围,包括时间
2)囊括所有几何体的边界框
3)存储项目数量的基数
4)属性值范围直方图
5)属性的离散值基数
统计信息通常在摄取和删除时更新。然而,天然地,范围和边界统计在删除期间并不更新,也许需要重新计算。以下是需要重复计算统计时推荐的情景:
1)当从索引去除项目时,如果这些项目包含了一些用于代表群体最小或最大值的属性,则范围和外部可能会失去准确性;
2)当统计算法被改变,已有的统计数据对新算法来说也许是不准确的。
这个统计依我看也不是啥新鲜事物,像sql server这类关系型数据库,系统会自动建立一些统计信息,以提高性能,比如记录数之类?,但随着不断修改又删除又新增,碎片日渐增多,这个统计信息就不准了,往往要重建索引来纠正这个统计信息。
(四)摄取(Ingest)
数据摄取是任何现代数据栈的一个重要步骤。其核心是将数据从各种数据源转移到最终目的地的过程,在那里它可以被存储用于分析目的。这些数据可以以多种不同的格式出现,并从各种外部来源产生(例如,网站数据、应用程序数据、数据库、SaaS工具等)。
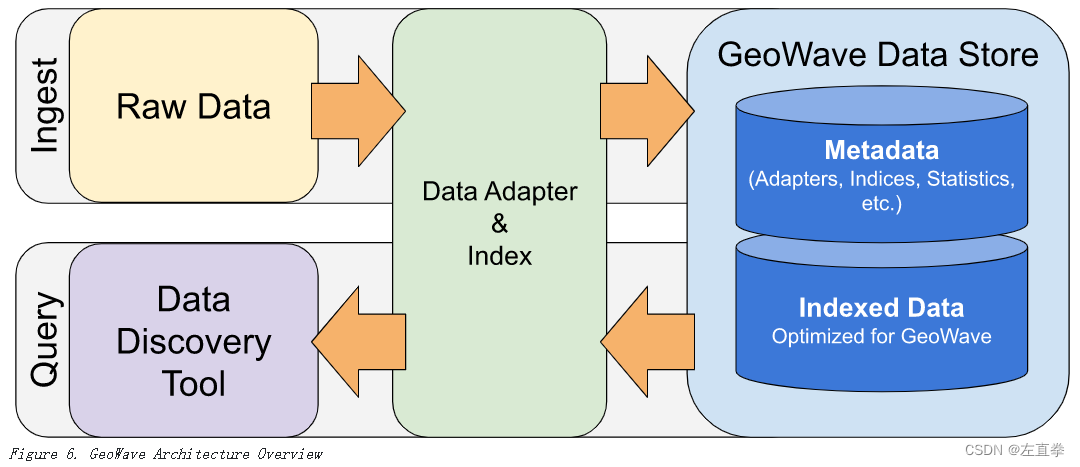
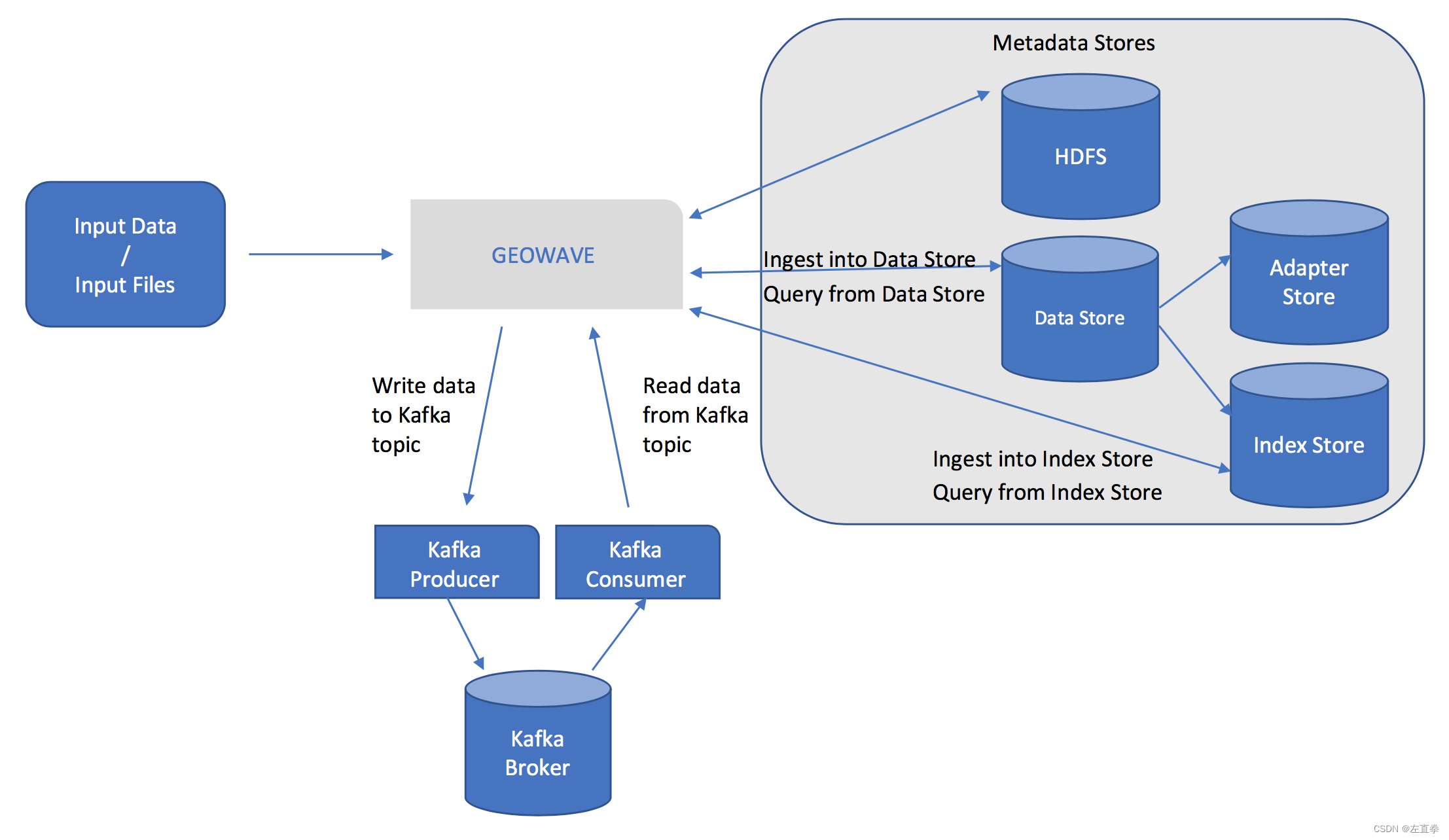
除了原始数据之外,摄取过程还需要一个适配器将本机数据转换为可以持久保存到数据存储中的格式,并需要一个索引来指示应该如何组织摄取的数据。 下图显示了摄取过程的概览:
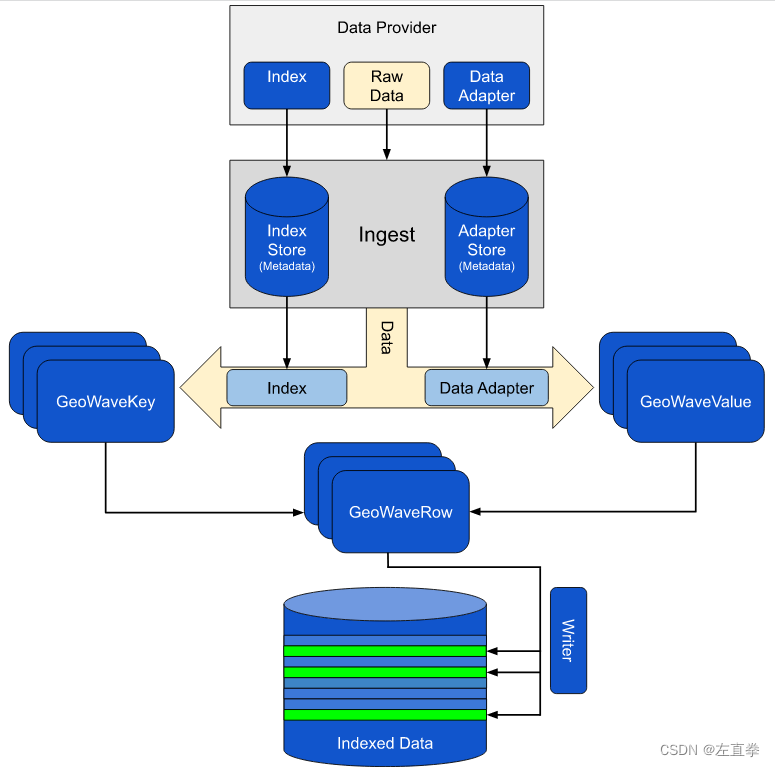
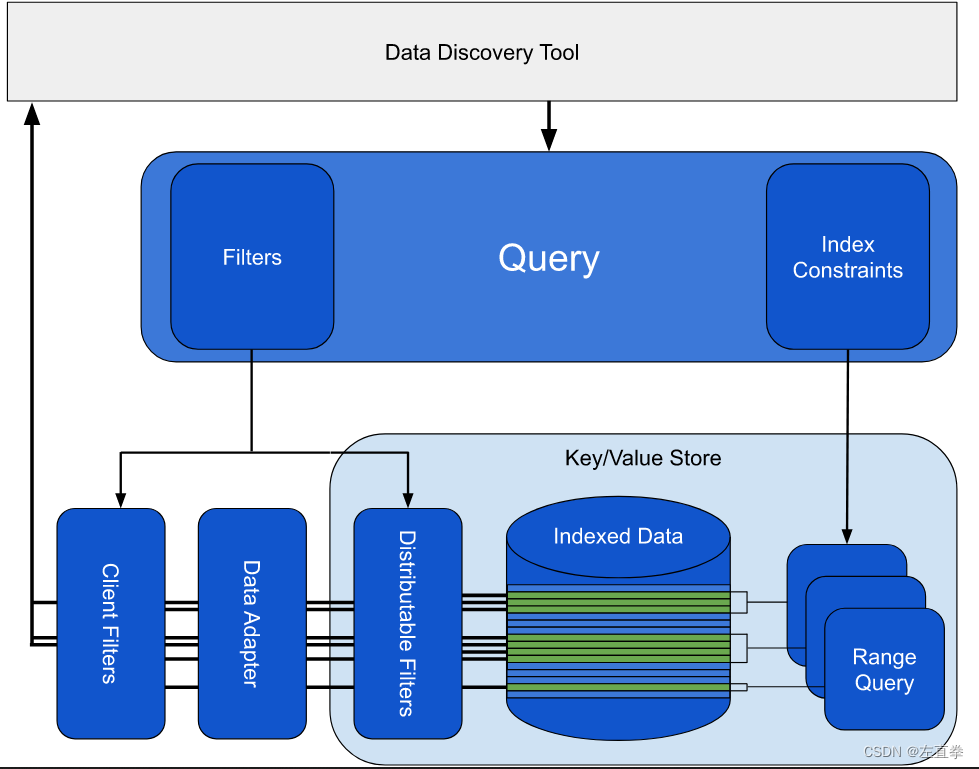
(五)查询(Query)
四、如何应用GeoWave
洒家没用过,还不知道。

参考文章:
官网
应用实例
简述
关于数据摄取的详细指南
GeoWave与GeoMesa的比较。
https://www.youtube.com/watch?v=eb5zka8iJTs