
大数据学习(2)
大数据学习(2)
- 0 数据仓库
- 0.0 数据仓库基本概念
- 0.1 数据仓库主要特征
- 0.1.0 面向主题(Subject-Oriented)
- 0.1.1 集成性(Integrated)
- 0.1.2 非易失性(Non-Volatile)
- 0.1.3 时变性(Time-Variant)
- 0.2 数据库和数据仓库的区别
- 0.3 数据仓库分层
- 1 Hive
- 1.0 Hive理论知识
- 1.0.0 Hive概要
- 1.0.1 Hive基本架构
- 1.0.2 Hive的计算引擎
- 1.0.2.0 MapReduce
- 1.0.2.1 Tez
- 1.0.2.2 Spark
- 1.0.3 Hive的数据库和表
- 1.1 Hive操作
- 1.1.-1 mysql的安装
- 1.1.0 Hive的安装和启动
- 1.1.0.0 下载Hive
- 1.1.0.1 安装Hive
- 1.1.0.2 启动Hive
- 1.1.1 Hive可视化客户端
- 1.1.1.0 DataGrip工具的使用
- 1.1.2 Hive的数据库操作
- 1.1.3 Hive的数据表操作
0 数据仓库
0.0 数据仓库基本概念
数据仓库,Data Warehouse,简写成DW或DWH。数据仓库是一个很大的数据存储集合,出于企业的分析性报告和决策支持的目的而创建。为企业提供一定的BI(商业智能)能力,知道业务流程改进、监视时间、成本、质量以及控制。
数据仓库的输入方是各种各样的数据源,最终的输出用于企业的数据分析、数据挖掘、数据报表等方向。
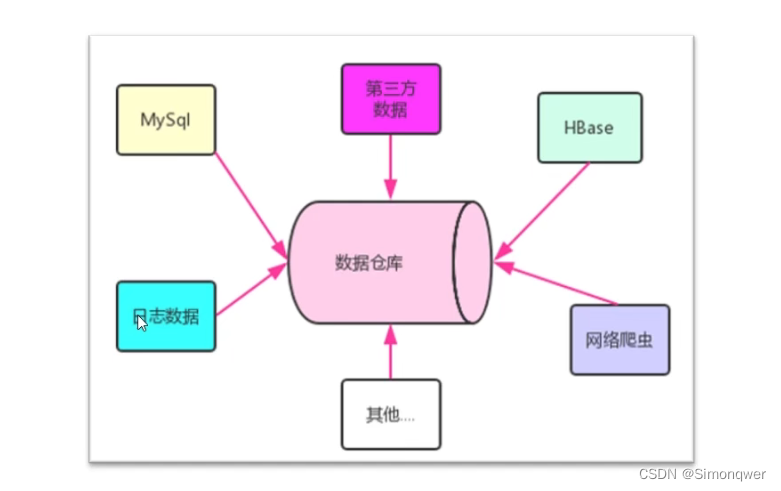
(从这个教程往后的话可能都没有安装的步骤了,因为找到了配套的文件,后期可能会补)
0.1 数据仓库主要特征
0.1.0 面向主题(Subject-Oriented)
主题是一个抽象的概念,是较高层次上
数据综合、归类并进行分析利用的抽象
0.1.1 集成性(Integrated)
主题相关的数据通常会分布在多个操作型
系统中,彼此分散、独立、异构。需要集
成到数仓主题下。
0.1.2 非易失性(Non-Volatile)
也叫非易变性。数据仓库是分析数
据的平台,而不是创造数据的平台。
0.1.3 时变性(Time-Variant)
数据仓库的数据需要随着时间更新,以适
应决策的需要。
0.2 数据库和数据仓库的区别
数据库是面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、并发支持的用户数等问题。
传统的数据库系统作为数据管理的主要手段,主要用于操作型处理,也被称为联机事务处理OLTP(On-Line Transaction Processing)。
数据仓库的出现,并不是要取代数据库。
两者区别:
数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库一般存储业务数据,数据仓库存储的一般是历史数据。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它决不是所谓的“大型数据库”。
0.3 数据仓库分层
按照数据流入流出的过程,数据仓库架构可分为三层——源数据(ODS)、数据仓库(DW)、数据应用(APP)。
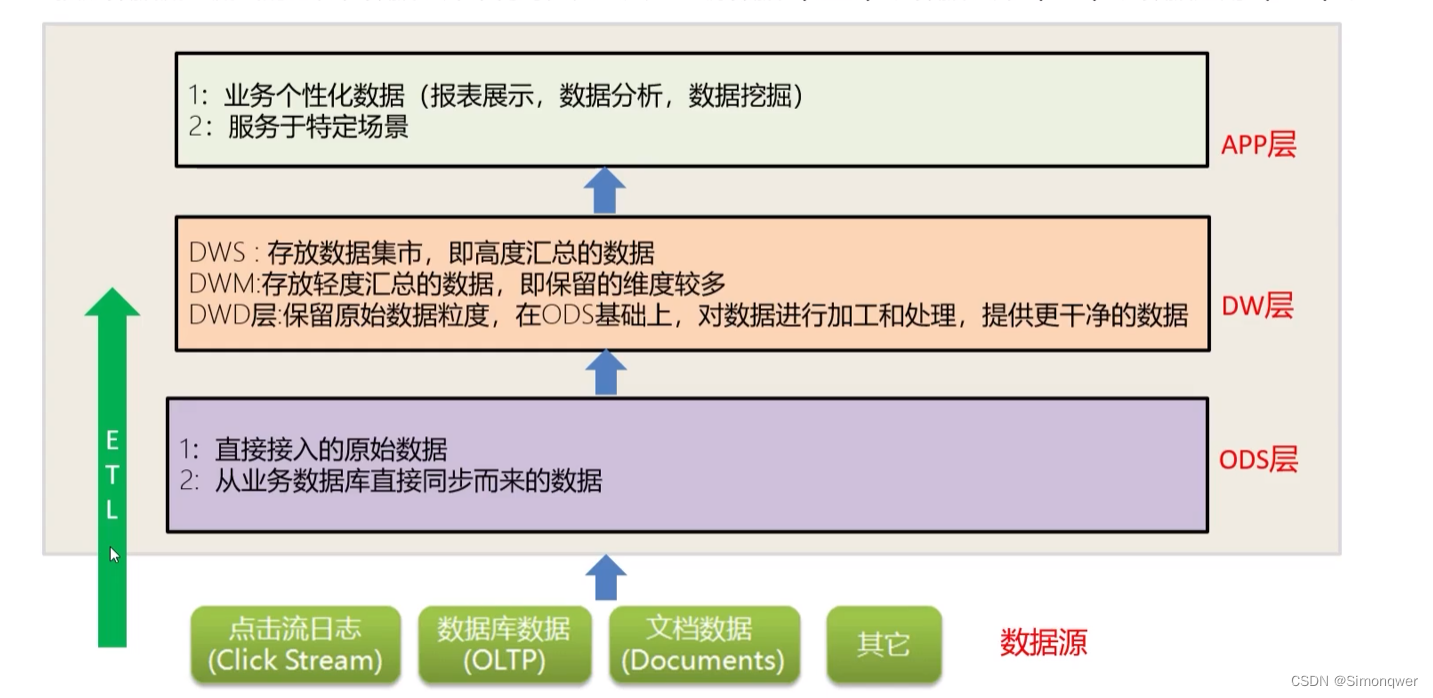
1 Hive
1.0 Hive理论知识
1.0.0 Hive概要
Hive是一个构建在Hadoop上的数据仓库框架。最初,Hive是由Facebook开发,后来移交由Apache软件基金会开发,并作为一个Apache开源项目。
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
- Hive它能够存储很大的数据集,可以直接访问存储在Apache HDFS或其他数据存储系统(如Apache HBase)中的文件。
- Hive支持MapReduce、Spark、Tez这三种分布式计算引擎。
1.0.1 Hive基本架构
Hive是建立在Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以存储、查询和分析存储在分布式存储系统中的大规模数据集。Hive定义了简单的类SQL查询语言,通过底层的计算引擎,将SQL转为具体的计算任务进行执行。
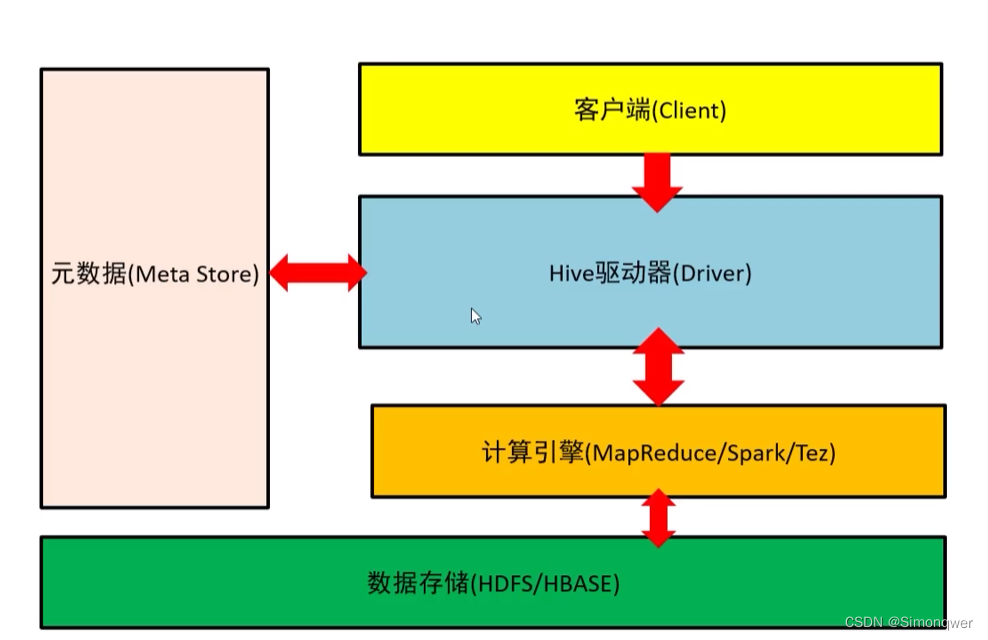
- 客户端:写类SQL语句
- Hive驱动器:解析、优化SQL
- 计算引擎:通过计算引擎来执行SQL
- 数据存储:存储源数据和结果数据
Hive自带的客户端
bin/hive,bin/beeline
hive有两个服务,hive是旧的服务,而beeline是新的服务,旧的服务官方不推荐我们使用,新的服务是使用JDBC来实现服务,也是官方推荐我们来使用。

1.0.2 Hive的计算引擎
1.0.2.0 MapReduce
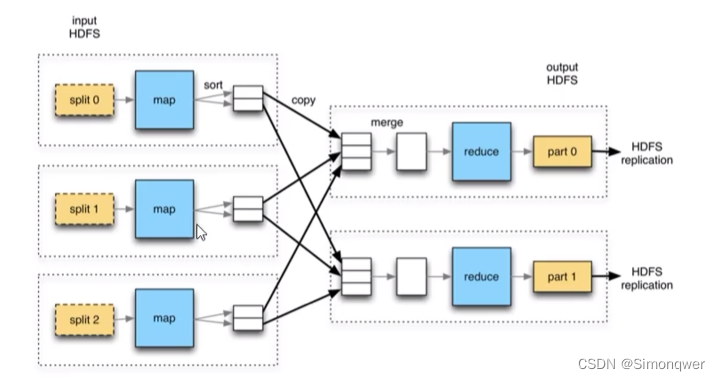
- 它将计算分为两个阶段,分别为Map和Reduce。对于应用来说,需要想方设法将应用拆分成多个map、reduce的作业,以完成一个完整的算法。
- MapReduce整个计算过程会不断重复地往磁盘里读写中间结果,导致计算速度比较慢,效率比较低。
1.0.2.1 Tez
- Tez把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。
1.0.2.2 Spark
- Apache Spark是一个快速的,多用途的集群计算系统,相对于Hadoop MapReduce将中间结果保存在磁盘中,Spark使用了内存保存中间结果,能在数据尚未写入硬盘时在内存中进行运算,同时Spark提供SQL支持。
- Spark实现了一种叫做RDDs的DSG执行引擎,其数据缓存在内存中可以进行迭代处理。
1.0.3 Hive的数据库和表
1.1 Hive操作
1.1.-1 mysql的安装
下面是我的安装过程:
link
1.1.0 Hive的安装和启动
1.1.0.0 下载Hive
这是apache官方下载源:
https://archive.apache.org/dist/hive/
下载了hive-3.1.3版本,在windows上下载的。
1.1.0.1 安装Hive
安装的过程参考了下面博客:
centos7安装hive
基于Hadoop(3.1.3)的数据仓库Hive(3.1.2)
1.1.0.2 启动Hive
首先要安装好hadoop集群,或者是hadoop单机环境。总之一定要保证Hadoop集群健康可用,因为hive是基于hadoop来运行的。
服务器基础环境:
集群时间同步,防火墙关闭,主机Host映射,免密登录,JDK安装
Hadoop集群健康可用
启动Hive之前必须先启动Hadoop集群。特别注意要等待HDFS的安全模式关闭之后再启动运行Hive。
因为Hive本身并不是一个分布式的安装运行软件,其分布式的特性主要由Hadoop完成。包括分布式存储,分布式计算。
不好意思,太复杂了,报错也看不懂,最后能跑了。而且我之前配置的是单机模式,后面用的都是集群模式,有很大的改变。
下面是hive的两个服务启动代码,nohup是linux系统后台运行的命令。

#先启动metastore服务,然后启动hiveserver2服务
nohup /path/hive/bin/hive --service metastore &
nohup /path/hive/bin/hive --service hiveserver2 &
启动之后是要等待一段时间的,服务启动是要时间的。
如果直接在远程机器上前台启动beeline,有连接访问的操作。
! connect jdbc:hive2://node1:10000
root
(enter)
1.1.1 Hive可视化客户端
相关的工具是有很多的:
DataGrip、Dbeaver、SQuirrel SQL Client等
我这里使用的DataGrip,然后其他的工具或多或少都使用过,但是数据库的连接DataGrip像那个pycharm一样,有些JDBC协议是可以直接在DataGrip中下载即用的。(而且都是jetbrains公司的,可以重复自己的破解过程)
1.1.1.0 DataGrip工具的使用
DataGrip工具的安装和破解(学生学习无所谓,以后工作肯定是会用正版的)请自行百度。尽量安装低版本的,然后用重复激活就可以用了。
DataGrip要先建立项目,然后创建连接,新建文件。
注意:如果下次是直接打开的DataGrip,要先去打开项目,然后再进行一些操作,不然就会看到一个空的文件夹,然后你所有操作都会存在c盘的暂时文件目录下。
1.1.2 Hive的数据库操作
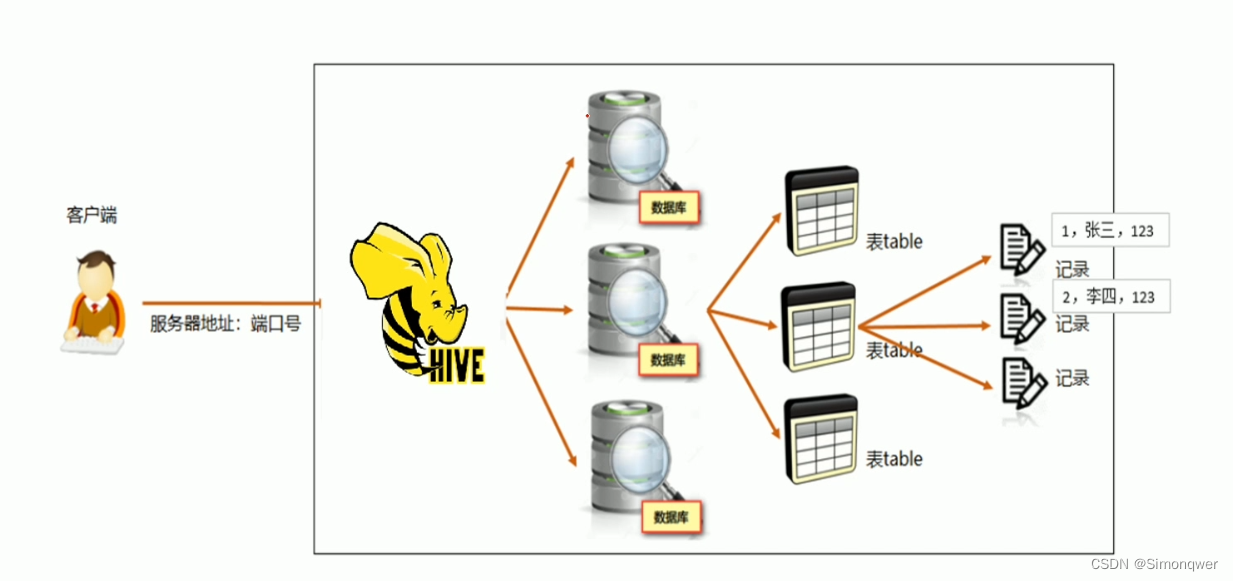
下图是hive数据模型,基本与一般的数据库一样
数据库的DDL(Data Definition Language)语法
数据定义语言(Data Definition Language,DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言,这些数据库对象包括database、table等。
DDL的核心语法由CREATE,ALTER和DROP三个所组成,并不设计表内部数据的操作。
1、use database
选定特定的数据库
切换当前的操作数据库,如果实在不放心,就直接在所有的sql操作之前使用这个语句
use xxx
2、create database
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ..)];
3、drop database
删除数据库
默认行为是RESTRICT,就是只有数据库为空时才删除它。
要删除带有表的数据库(不为空的数据库),我们可以使用CASCADE。
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
3、show语句
- 显示所有数据库(SCHEMAS和DATABASES的用法、功能一样)
show databases;
show schemas;
- 显示当前数据库所有表
show tables;
SHOW TABLES [IN database_name];
- 查询显示一张表的元数据信息
desc formatted t_team_ace_player;
1.1.3 Hive的数据表操作
1、create table
- 关键字
- []中括号的语法表示可选。
- 建表语句中的语法顺序要和语法树中顺序保持一致。
- 最低限度必须包括的语法为:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name
(col_name data_type [COMMENT col_comment], ...)
[COMMENT table_comment]
[ROW FORMAT DELIMITED ...];
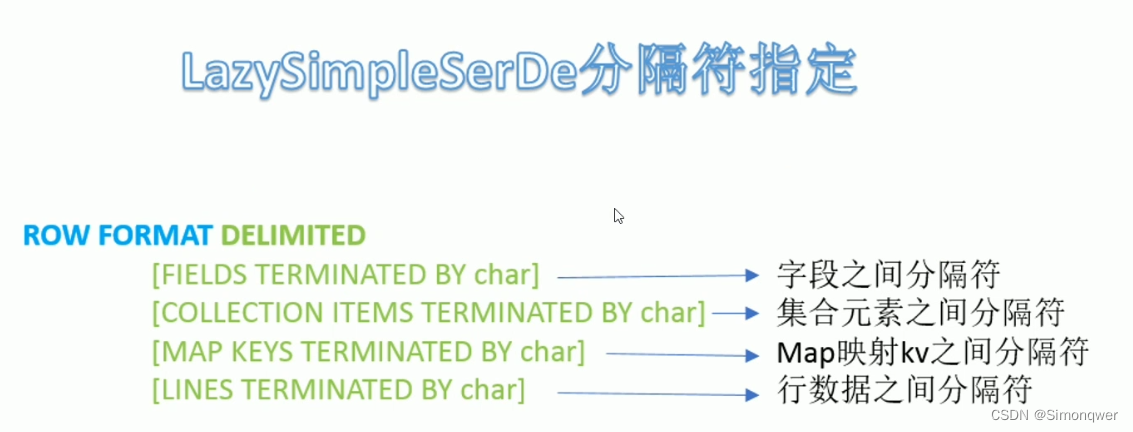
下图是ROW FORMAT DELIMITED,决定分隔符指定,这个主要是面对一些结构化文件直接输入,并不是直接从某些处理好的数据库来进行操作。
这里插入一下Hive的数据类型
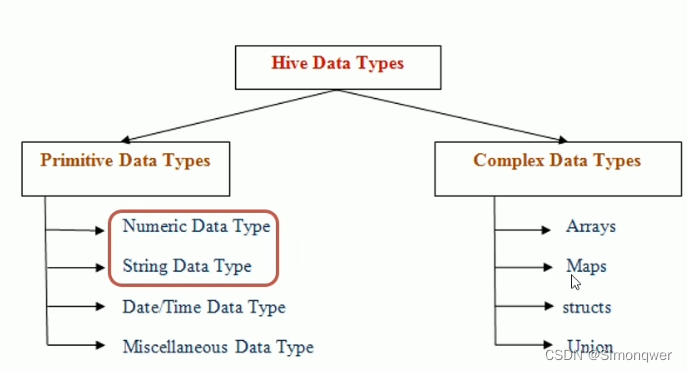
- Hive数据类型指的是表中列的字段类型。
- 整体分为两类:原生数据类型(primitive data type)和复杂数据类型(complex data type)。
- 最常用的数据类型是字符串 String和数字类型 Int。
2、show table
use databaseName;
show tableName;show tableaName in databaseName;
这两种语法都是可以完成显示某个表的操作。
3、desc table
desc tableName;
就是和数据库操作一样,显示这个表的一些详细信息。
4、drop table
drop tableName;
删除某个表的操作。
5、comment
create table tableName (id int comment "ID编号",
)
建表操作时,如果要在键上表明注释,可以用comment来标记。
这里插入一下在table里写comment,在datagrip里调用desc命令查看时是乱码的问题
一般的数据库,例如mysql的编码存储汉字的时候会显示乱码,下面的方法是用mysql的解决乱码问题。
进入装有mysql的电脑,开启mysql。
--注意 下面sql语句是需要在MySQL中执行 修改Hive存储的元数据信息(metadata)
use hive3;
show tables;alter table hive3.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table hive3.TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive3.PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
alter table hive3.PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table hive3.INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;