
【数据结构】KMP算法(详解)
创始人
2025-05-30 04:17:38
目录
- 1. 朴素的模式匹配
- 2. KMP算法解决的问题
- 3. KMP算法
- 公共前后缀(重点)
- next 数组
- KMP算法实现
1. 朴素的模式匹配
-
朴素算法中,当匹配到不同位时,主串指针i会退回到该次匹配起点处的下一位置,以其为下一次匹配的主串起点
-
同时字串的j指针退回其起始位置
-
如此一来每次匹配主串指针后移一位,字串指针始终在其起始位置
-
时间复杂度为O(m*n)
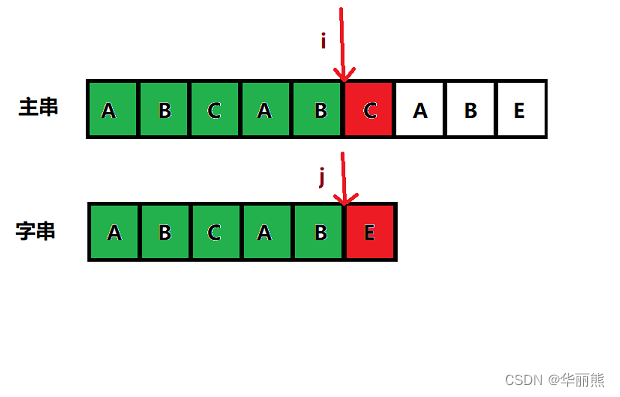
2. KMP算法解决的问题
-
可以发现下图中,在第二次匹配时,第一个元素就已经不一样了
-
朴素算法的缺点就在于其会傻傻的执行许多次这样不必要的判断
-
这就是KMP算法所解决的问题
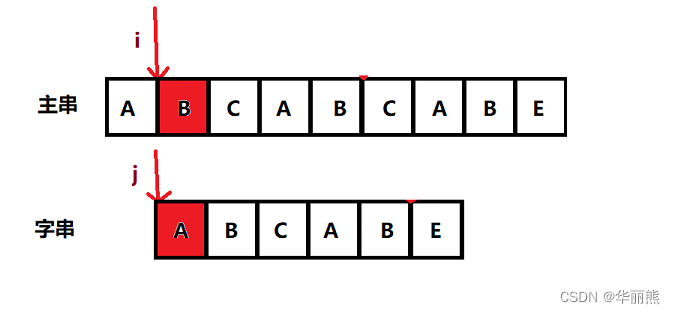
3. KMP算法
- 主串指针不会进行回溯,不会回到朴素匹配中的下一匹配点
- 利用已匹配部分中的公共前后缀来调整字串指针位置,以此加速下一次匹配
根据下面的动画感受感受
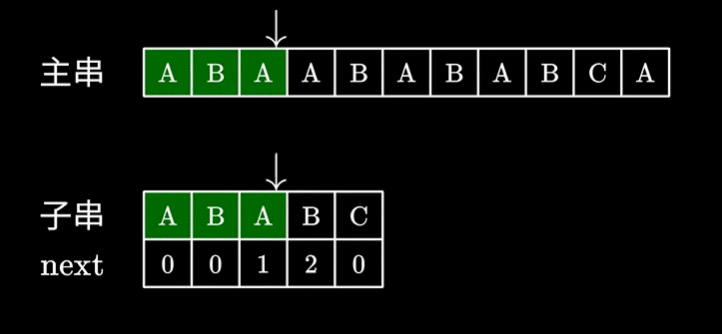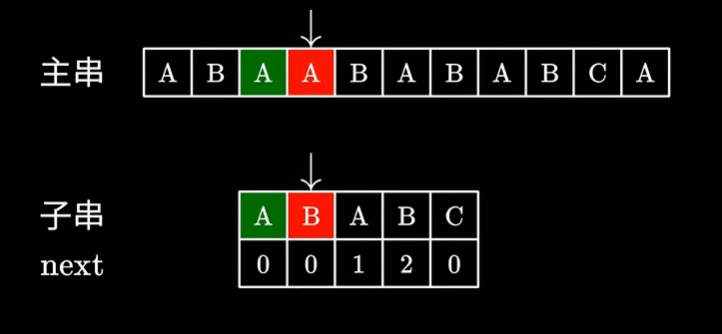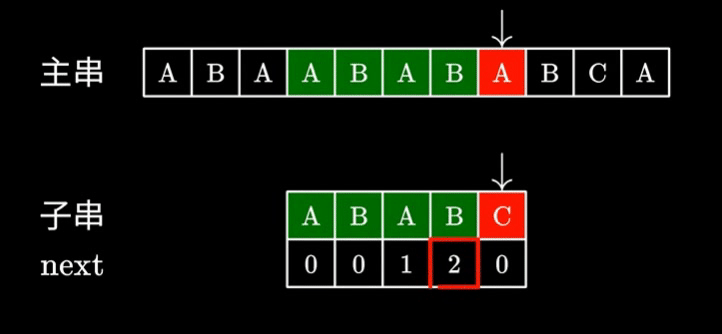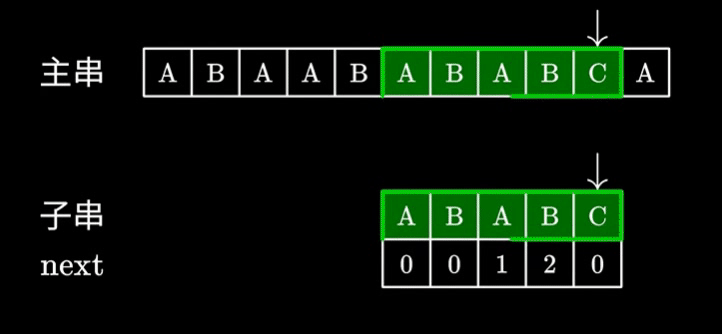
- 可以看到,主串指针( i )在整个查找过程中都没有前移,每次查找的起点均为上次查找的结束点,即 i 永远不递减,这也使KMP的精髓
- 同时,当不匹配位置前一位对应的next数组中元素不为0时,字串指针( j )会向后偏移相应个数的字符
- 这样一来,无论是主串还是字串的判断次数都得到了优化,时间复杂度优化至O(m+n)
公共前后缀(重点)
公共前后缀的计算:
这里用公式理解,计算下标为a处的公共前后缀个数,如果[a-x,a]范围的每一个元素与[0,x]范围的每一个元素相等,则a处的公共前后缀个数为x+1
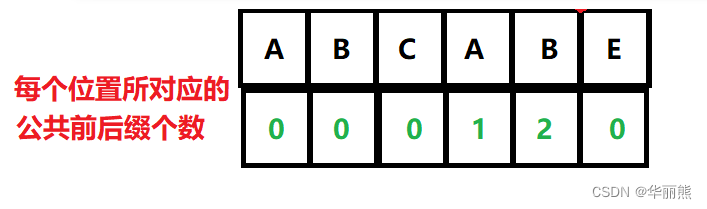
这里注意找某一位置的公共前后缀时,要将起始位置的字符同该位置字符比较,而不是只要在该位置之前出现了相同元素就判断存在公共前后缀
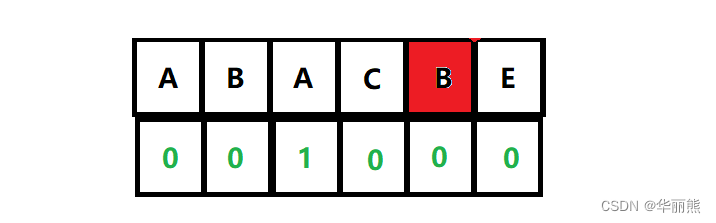
如下图中的红色位置B,虽然在其之前存在一个字符B,但是该位置的公共前后缀为0
next 数组
理解了什么是公共前后缀,其实next数组就是存储该数组每个对应位置公共前后缀数量的数组
(这里的next数组实际上为PM表,PM表右移一位 (空缺的用-1填充,最后一个元素的部分匹配值用于下一个元素,但没有下一个元素故可以舍弃) 并加一得到next数组。)


next表的含义是子串的第j个字符发生失配时跳到子串的next[j]位置重新与主串当前位置进行比较。
代码实现next数组(PM表)
这里其实用到了双指针,i 为next数组的下标,j 指向字串中的元素
int* get_next(const char* p)
{assert(p);int len = strlen(p);int* next = (int*)malloc(sizeof(int) * len);if (next == NULL)//满足vs2019及以上动态开辟检查标准,不写会报错{printf("malloc fail\n");exit(-1);//申请失败,异常退出}else{//先将其全部初始化为0memset(next, 0, sizeof(int) * len);int j = 0;//字串字符指针int i = 0;//相应位置next指针for (i = 1; i < 6; i++){if (p[i] == p[j]){next[i] = next[i - 1] + 1;//连续相等则next值递增j++;//字串字符指针依次向后偏移}else{//不相等则跳回字串起点,再判断是否与首位相同j = 0;if (p[i] == p[j]){next[i] = 1;//相同直接赋 1j++;}}}return next;}
}
KMP算法实现
注意代码注释
int my_kmp(char* a1, char* a2)
{int* next = get_next(a2);int len1 = strlen(a1);int len2 = strlen(a2);int i = 0;int j = 0;while (i < len1){if (a1[i] == a2[j]){//相等则两指针均向后偏移i++;j++;}else if (j > 0) // j>0 时,根据next数组调整 j 的位置j = next[j - 1];else //字串第一个字符就不匹配i++;if (j == len2) //匹配成功,返回值为字串第一个字符在主串中的下标return i - j;}return -1;
}
相关内容
热门资讯
辽宁福鞍重工股份有限公司关于部...
■辽宁福鞍重工股份有限公司关于部分限制性股票回购注销实施的公告本公司董事会及全体董事保证本公告内容不...
滁州职业技术学院:双向赋能打造...
(来源:光明日报)转自:光明日报 滁州职业技术学院作为地方政府举办的高职院校,扎根服务滁州,以产教...
上海威派格智慧水务股份有限公司...
证券代码:603956 证券简称:威派格 公告编号:2025-093上海威派格智慧水务股份有限公司关...
原创 分...
分析:马刺对阵尼克斯的NBA杯决赛为何预示着NBA总决赛的对决? 马刺和尼克斯将在NBA杯决赛中展开...
让人感到温暖的个人QQ签名 q...
1、 你在这头,我在那头,虽然不能见面,一条短信,带着祝福,将你我相连,愿你快乐幸福到永远 2、 一...