
Python数据挖掘-机器学习
零、概念
机器学习:从数据中自动分析获得模型,并利用模型对位置数据进行预测
数据集(机器学习所要学习的数据):特征值(基础属性) [ + 目标值(所求问题) ]
分类问题:目标值为类别
回归问题 :目标值为连续型(目标值与特征值有关联)的数据
无监督学习:没有目标值(有目标值的均为监督学习)
算法:
监督学习:knn算法、贝叶斯分类、决策树与随机森林、逻辑回归
无监督学习:聚类k-means
开发流程:
获取数据、数据处理、特征工程、算法训练-模型、模型评估、应用
一、sklearn
1.数据集
(1)sklearn自带数据集应用
sklearn.datasets.load_*:小数据集
sklearn.datasets.fetch_*:大数据集
(2)数据集划分
原理:将原数据取一部分出来当作预测值,来证明学习后得到的预测结果符合要求(模型评估)
x_train,x_test,y_train,t_test=sklearn.model_selection.train_test_split()
传入:数据集的特征值;数据集的目标值;test_size测试集的大小,一般为float;random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return: 训练集特征值(x_train),测试集特征值(x_test),训练集目标值(y_train),测试集目标值(y_test)。
2.特征工程
补充:将任意数据转换为可用于机器学习的数字特征
(1)字典特征提取:sklearn.feature_extraction.DictVectorizer()
DIctVectorizer().fit_transform(x):转换数据
DIctVectorizer().get_feature_names_out():返回类别名(转换完数据才能查看)
from sklearn.feature_extraction import DictVectorizer
def sk():data=[{'city':'北京',"temperature":23},{'city':'上海',"temperature":29},{'city':'广州',"temperature":32}]transfer1 = DictVectorizer()#实例化方法;sparse=True为稀疏矩阵transfer2=DictVectorizer(sparse=False)data_new1=transfer1.fit_transform(data) #调用fit_transformdata_new2 = transfer2.fit_transform(data)print(data_new1)#稀疏矩阵就是将非0值的位置表示出来print(data_new2)
#1图为稀疏矩阵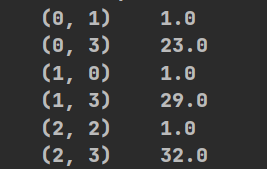

(2)文本特征提取:sklearn.feature_extraction.text.CountVectorize()
补充:统计文本特征词出现的次数
CountVectorize(stop_words=["","",...]):参数可带停用词
CountVectorize().fit_transform(x):转换数据
CountVectorize().get_feature_names_out():返回类别名(转换完数据才能查看)
from sklearn.feature_extraction.text import CountVectorizer
def count():data=["life is short, i like like python","life is too long,i dislike python"]transfer=CountVectorizer()#文本没有sparse属性data_new = transfer.fit_transform(data)print(data_new.toarray())#用toarray()转化为非稀疏矩阵print(transfer.get_feature_names_out())