
数据挖掘实验:关联规则分析之Apriori算法的实现
创始人
2025-05-28 04:25:09
一、实验原理
Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。该算法中项集的概念即为项的集合。包含K个项的集合为k项集。项集出现的频率是包含项集的事务数,称为项集的频率。如果某项集满足最小支持度,则称它为频繁项集。
二、实验内容
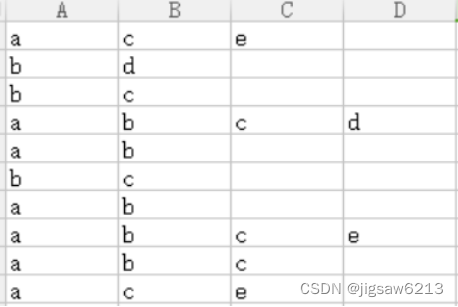
三、实验过程
python实现Apriori算法
from __future__ import print_function
import pandas as pd#自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):x = list(map(lambda i:sorted(i.split(ms)), x))l = len(x[0])r = []for i in range(len(x)):for j in range(i,len(x)):if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))return r#寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果support_series = 1.0*d.sum()/len(d) #支持度序列column = list(support_series[support_series > support].index) #初步根据支持度筛选k = 0while len(column) > 1:k = k+1print(u'\n正在进行第%s次搜索...' %k)column = connect_string(column, ms)print(u'数目:%s...' %len(column))sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数#创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).Tsupport_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选support_series = support_series.append(support_series_2)column2 = []for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?i = i.split(ms)for j in range(len(i)):column2.append(i[:j]+i[j+1:]+i[j:j+1])cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列for i in column2: #计算置信度序列cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选result[i] = 0.0result[i]['confidence'] = cofidence_series[i]result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]result = result.T.sort_values(['confidence','support'], ascending = False) #结果整理,输出print(u'\n结果为:')print(result)return result
Apriori算法调用,进行关联性分析
from __future__ import print_function
import pandas as pd
from apriori import * #导入自行编写的apriori函数inputfile = '../data/menu_orders.xls'
outputfile = '../tmp/apriori_rules.xls' #结果文件
data = pd.read_excel(inputfile, header = None)print(u'\n转换原始数据至0-1矩阵...')
ct = lambda x : pd.Series(1, index = x[pd.notnull(x)]) #转换0-1矩阵的过渡函数
b = map(ct, data.as_matrix()) #用map方式执行
data = pd.DataFrame(list(b)).fillna(0) #实现矩阵转换,空值用0填充
print(u'\n转换完毕。')
del b #删除中间变量b,节省内存support = 0.2 #最小支持度
confidence = 0.5 #最小置信度
ms = '---' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符find_rule(data, support, confidence, ms).to_excel(outputfile) #保存结果
四、实验结果
结果如下
support confidence
e—a 0.3 1.000000
e—c 0.3 1.000000
c—e—a 0.3 1.000000
a—e—c 0.3 1.000000
c—a 0.5 0.714286
a—c 0.5 0.714286
a—b 0.5 0.714286
c—b 0.5 0.714286
b—a 0.5 0.625000
b—c 0.5 0.625000
a—c—e 0.3 0.600000
b—c—a 0.3 0.600000
a—c—b 0.3 0.600000
a—b—c 0.3 0.600000
上一篇:深度学习——3D点云
相关内容
热门资讯
中央财经大学最新或2023(历...
各位同学: 根据教育部、公安部、民政部、总参谋部、总政治部联合下发的《关于进一步做好从全日制高...
北京230名适龄大学生参加了征...
身高放宽2cm,体重放宽10%,视力放宽0.3……昨天上午,在朝阳区第二医院体检中心,230名适龄大...
北京市征兵办:大学生当兵总经济...
记者昨天从本市夏秋季征兵工作动员会上获悉,今年义务兵服役期间经济补助再次大幅提高,本科生总经济补助...
北京最新或2023(历届)征兵...
继身高、体重、视力等体检标准放宽后,今年征兵的政治考核也将简化。记者从北京市最新或2023(历届...
西城区召开最新或2023(历届...
7月2日,西城区召开夏秋季征兵工作动员部署大会,征兵工作全面启动。会议总结去年征兵工作情况,部署...