
大数据-学习实践-4MapReduce
大数据-学习实践-4MapReduce
(大数据系列)
文章目录
- 大数据-学习实践-4MapReduce
- 1知识点
- 2具体内容
- 2.1MapReduce介绍
- 2.2分布式计算介绍、原理
- 2.2.1MapReduce原理剖析
- 2.2.2Map
- 2.2.3Reduce
- 2.3 WordCount分析
- 2.4MapReduce任务日志查看
- 2.4.1停止Hadoop集群的任务
- 2.4.2MapReduce程序扩展
- 2.5Shuffle过程
- 2.5.1序列化机制
- 2.5.2 InputFormat分析-getSplits
- 2.5.3 InputFormat分析-RecordReader
- 2.5.4 OutputFormat分析
- 3待补充
- 4Q&A
- 5code
- 6参考
1知识点
- MapReduce介绍
- 分布式计算、原理
- 实例分析:WordCount分析
- 日志查看
- Shuffle执行过程及源码分析
2具体内容
2.1MapReduce介绍

只需要磁盘IO,不需要网络IO
2.2分布式计算介绍、原理
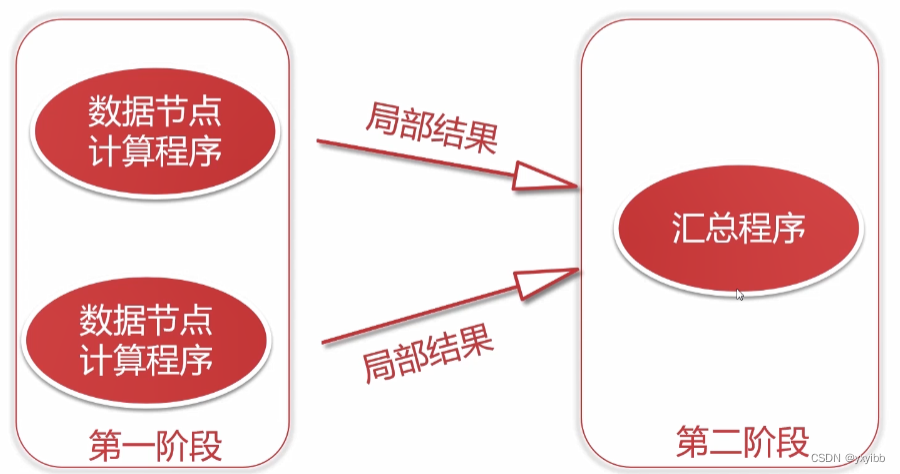
2.2.1MapReduce原理剖析
- MapReduce是一种分布式计算模型,用于搜索,解决海量数据计算
- Map+Reduce阶段
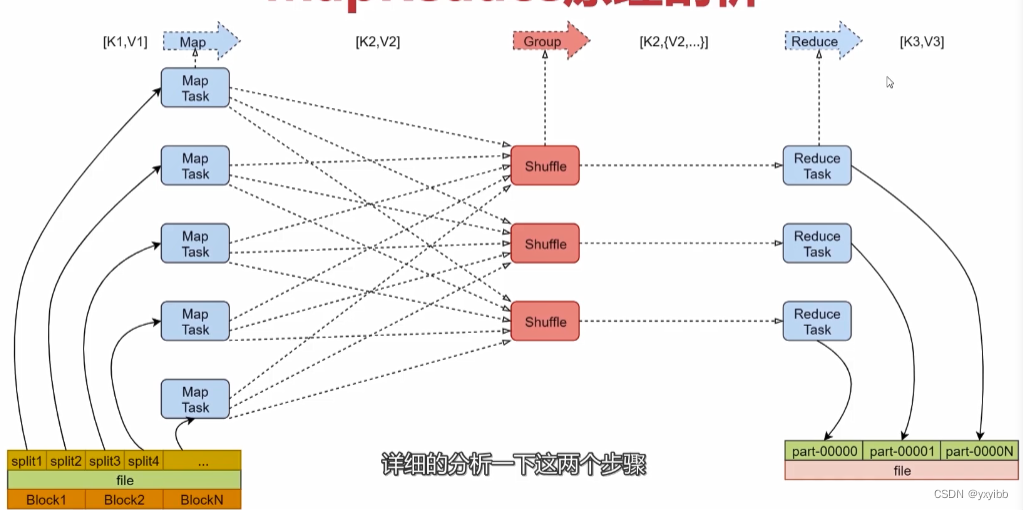
2.2.2Map
- 框架会把输入文件(夹)划分为很多InputSplit,默认每个HDFS的Block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个
- 框架调用Mapper类中的map(…)函数,map函数的输入是
- 框架对map函数输出的
- 框架对每个分区中的数据,按照k2进行排序、分组。分组,指的是相同k2的v2分成一个组
- 在Map阶段,框架可以执行Combiner操作【可选】
- 框架会把Map Task输出的
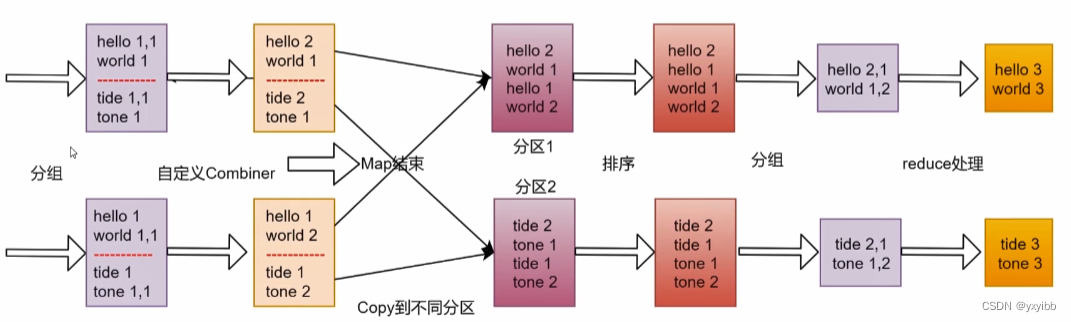
eg:hello.txt
hello you
hello me
第一步:
<0,hello you>
<10, hello me>
第二步:
第三步:
第四步:
排序
分组
第五步:规约combiner,可选,默认不执行。
可在Map端先聚合,Map端执行Reduce的聚合
第六步:写入文件
若没有reduce阶段,执行到第二步即可结束。
2.2.3Reduce
- 框架对多个Map Task的输出,按照不同的分区,通过网络Copy到不同的Reduce节点,这个过程称作Shuffle
- 框架对Reduce节点接收到的相同分区的
- 框架调用Reducer类中的reduce方法,输入
- 框架把Reduce的输出结果保存到HDFS中
第一步:
第二步:与Map阶段合并重组不重复,是对全局所有block的合并重组
第三步:
第四步:写入文件
hello 2
me 1
you 1
2.3 WordCount分析

 开发:
开发:
map-reduce-组装
- 建立一个mr包,建立WorldCountob文件
- 实现map函数,接收
- 实现reducer函数,接收
- 组装job=map+reduce
- 提交集群执行,补充pom.xml依赖,打jar包
cd db_hadoop
mvn clean package -DskinTests#清除之前生成的target目录,打包
#两个jar包,上传有依赖的
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJob /test/hello.txt /out#yarn(8088)界面也可查看
2.4MapReduce任务日志查看
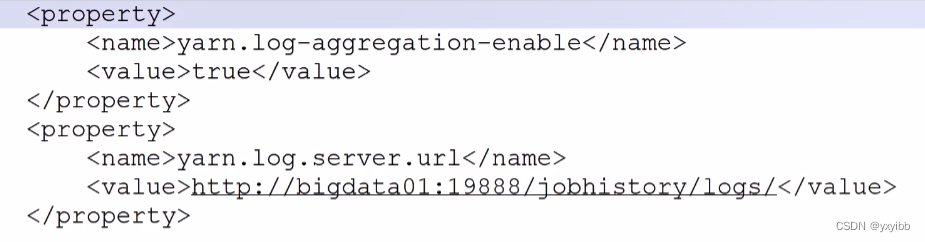
- 需要开启YARN日志聚合功能,散落在NodeManager节点的日志统一收集管理,方便查看(改配置重启集群,重启进程)
- 开日志聚合、增加访问链接
- 启动集群(所有节点)
- 启动进程(所有节点):
bin/mapred --daemon start historyserver
- 开日志聚合、增加访问链接
- yarn命令执行
yarn logs -applicationID application_15.....- yarn网页的日志中去取
- grep查
2.4.1停止Hadoop集群的任务
yarn application -kill- 命令行Ctrl+C无法停止程序,因为程序已经在Hadoop集群运行了
2.4.2MapReduce程序扩展
只留Map阶段,不需要Reduce任务时:
job.setNumReduceTasks(0)即可
2.5Shuffle过程
shuffle:从map端像reduce端,网络拷贝的过程
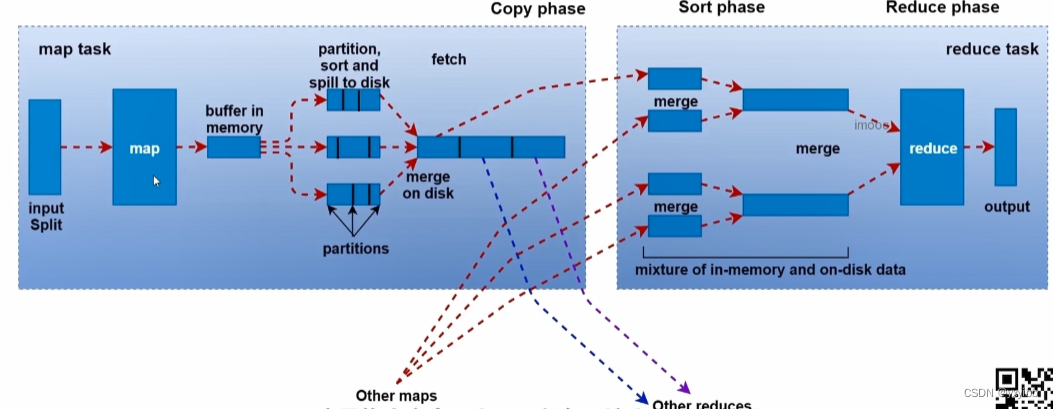
2.5.1序列化机制
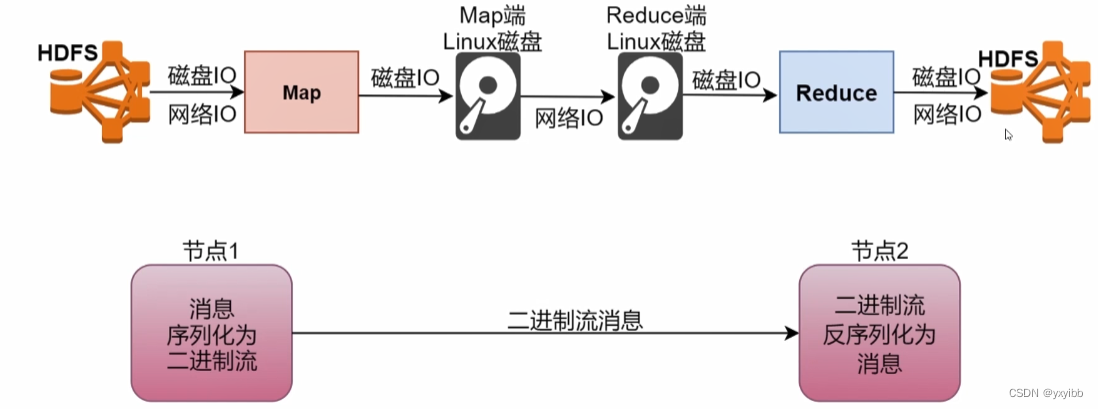
- 最影响MapReduce执行效率的主要原因-磁盘IO
- 磁盘IO会对数据进行序列化和反序列化
- 优化序列化机制!
- 序列化:内存中的对象信息转换成二进制形式
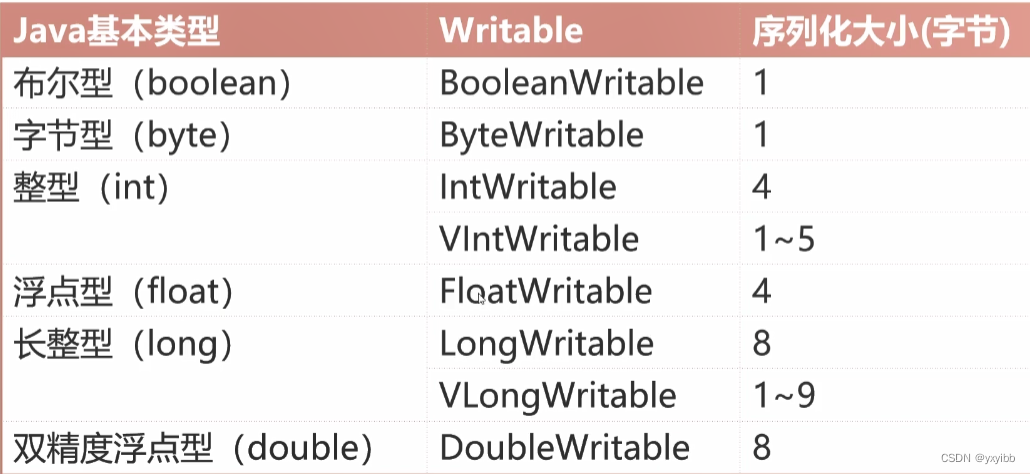
- Hadoop常用的Writable实现类:
- Text等价于java.lang.String的Writable,针对UTF-8序列
- NullWritable是单例,获取实例使用NullWritable.get()
- Hadoop序列化机制特点:
- 紧凑,高效使用存储空间
- 快速,读写数据的额外开销小
- 可扩展,可透明地读取老格式数据
- 互操作,支持多语言的交互
- Java序列化不足:
- 不精简,附加信息多,不适合随机访问
- 存储空间大,递归输出类的超类描述直到不再有超类
- 效果对比,实现两个类下文件输出,对比文件大小,几乎差10倍
2.5.2 InputFormat分析-getSplits
-
MapReduce中,原始数据被分割成若干InputSplit,每个InputSplit作为一个map任务输入
-
官网下源码,分析FileInputFormat类的getSplits方法
-
getSplit:当文件剩余大小bytesRemaining与splitSize的比值大于1.1的时候,就继续切分,否则,剩下的直接作为一个InputSize(即当bytesRemaining/splitSize <= 1.1时,会停止划分,将剩下的作为一个InputSplit)
-
把不支持切割的文件作为一个InputSplit,比如压缩文件
-
1个1G文件产生8个Map任务1个bolck块
- 一般,一个InputSplit大小=一个block大小
- 一个InputSplit产生一个Map任务
- 1G约是8个128M
-
1000个文件,每个文件100K,产生1000个Map任务
- 1个文件1个bolck块
- 1个bolck块1个InputSplit
- 对应1个Map任务
- 不适合小文件处理
-
一个140M文件,产生1个Map任务
- 140/128=1.09<1.1,产生1个Map任务
2.5.3 InputFormat分析-RecordReader
-
每一个InputSplit都有一个RecordReader,作用是把InputSplit中的数据解析成Record,即
-
如果这个InputSplit不是第一个InputSplit,将会丢掉读取出来的第一行,因为总是通过next()方法多读取一行(会多读取下一个InputSplit的第一行)
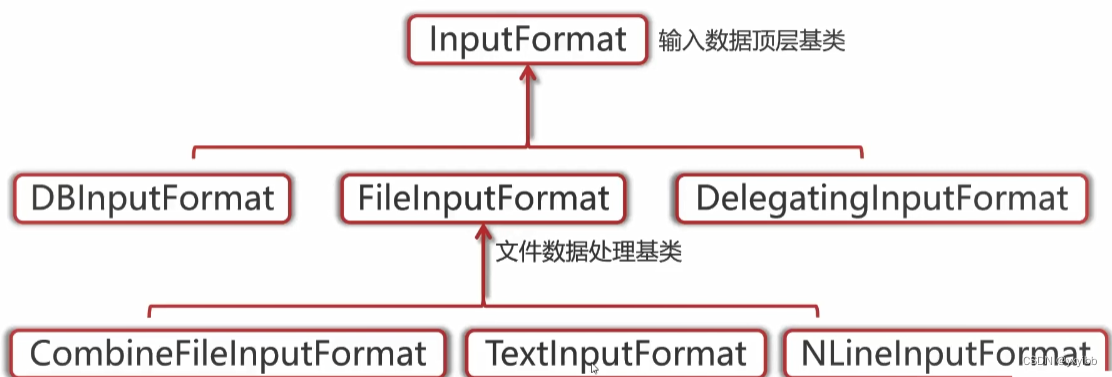
2.5.4 OutputFormat分析
- OutputFormat:输出数据顶层基类
- FileOutputFormat:文件数据处理基类
- TextOutputFormat:默认文本文件处理类
3待补充
无
4Q&A
无
5code
无
6参考
- 大数据课程资料
上一篇:Vue3实现滚动加载动画效果
下一篇:Java学习笔记——集合