
【小练】day1
day1
选择题
1. 以下for循环的执行次数是()。
for(x=0,y=0;(y=123)&&(x<4);×++);
A 是无限循环
B 循环次数不定
C 4
D 3
本题主要考察for
for(初始化部分;条件判断部分;调整部分)
初始化部分只执行一次。
&&:控制求值顺序——两边都为真才为真,若左边为假,直接判断为假,右边不判断。
(y=123)是一个赋值语句,赋值返回的结果是123,恒为真。所以x=[0, 3]共4次,选D。
2. 以下程序的运行结果是()。
int main()
{printf("%s, %5.3s\n","computer", "computer");return 0;
}
A computer, puter
B computer, com
C computer, computer
D computer, compu.ter
本题主要考察printf的字符串格式控制
对于printf(“%M.Ns”):
- M:打印的宽度
- M>0:右对齐 M<0:左对齐
- 多的补空格
- N:从左边开始,拿N个字符打印
所以题中printf(“%5.3s”)的意思是:
- M>0,右对齐,打印的宽度为5,多的补空格
- 左边开始,拿3个字符
" com" 空格空格com,选B。
3. 下列main()函数执行后的结果为()
int func()
{int i,j,k=0;for(i=0, j=-1;j=0;i++, j++){k++;}return k;
}int main(){cout<<(func());}
A -1
B 0
C 1
D 2
仍然考察for循环。j=0的返回值恒为假,初始化后,发现判断条件为假,就根本不会进for,返回k,即0,打印。选B。
4. 下面程序输出是什么?
#include
int main()
{int a=1,b=2, c=3,d=0;if(a == 1 && b++ == 2)if(b!=2 || c-- !=3)printf("%d,%d,%d\n"”,a,b,c);elseprintf("%d,%d,%d\n" ,a,b,c);elseprintf("%d, %d,%din",a,b,c);return 0;
}
A 1, 2, 3
B 1, 3, 2
C 1, 3, 2
D 1, 3, 3
本题考察if else的匹配
根据else的特性:会匹配最近的if。
我们可以找第一个else,匹配“if(b!=2llc–!=3)”,这两个拉走之后,第二个else就匹配"if(a == 1 8& b++==2)"。
第一个if是可以进的,判断后b自增至3。所以第二个if也能进,||控制求值顺序,判断为真后直接跳出。a=1 b=3 c=3。D
5. 若有定义语句:int a=10;double b=3.14;则表达式 A+a+b 值的类型是()
A char
B int
C double
D float
用相近类型直接进行计算,会发生自动类型转换(提升):精度低 ==> 精度高。C
6. 在int p[][4]={ {1}, {3,2}, {4,5,6}, {0} };中,p[1][2]的值是()
A 1
B 0
C 6
D 2
本题考察数组的特性
p是一行有4个int的二维数组,按照一对花括号一行的原则初始化
[1, 0, 0, 0]
[3, 2, 0, 0]
[4, 5, 6, 0]
[0, 0, 0, 0]
B
7. 选择表达式 11|10 的结果(本题数值均为十进制)
A 11
B 10
C 8
D 2
本题考察进制转换和位运算
对于数值不大的“十进制转二进制”,我们可以凑
11 = 8 + 2 + 1 = 2^3 + 2^1 + 2^0
= 0000 1011
10 = 8 + 2 = 2^3 + 2^1
= 0000 1010
按位或|:1是老大,每位上有1则1
0000 1011 | 0000 1010
1111121= 0000 1011 —— 选A
对于数值较大的“十进制转二进制”,我们可以“除2倒取余”的方法。
具体见文末。
8. fun(21)运行结果是()
int fun(int a)
{a^=(1<<5) -1;return a;
}
A 10
B 5
C 3
D 8
本题考察位运算
-
a ^= (1<<5) - 1:a = a ^ (1<<5) - 1
-
1 << 5 - 1
- (0000 0001 << 5 ) - 1 =
- 0010 0000 - 1 = 31
-
a = 21:
a = 21 ^ 31
0001 0101 ^
0001 1111 =
0000 1010 = 10(十进制)
选A。
9. 若有定义语句:int year=1009,*p=&year;以下不能使变量 year 中的值增至 1010 的语句是
A *p+=1;
B (*p)++;
C ++(*p);
D *p++;
A:解引用找到year,year += 1
B:解引用找到year,对其后置++。此语句后,year++
C:解引用找到year,对其前置++。year在当前语句++。
D:的优先级比*(解引用)高,但因为是后置++,所以先对p解引用找到year,但什么也没对year做,而后p++,让它跳过一个int(指针的加减见文末)。
选D。
10. 下面关于"指针"的描述不正确的是()
A 当使用free释放掉一个指针内容后,指针变量的值被置为NULL
B 32位系统下任何类型指针的长度都是4个字节
C 指针的数据类型声明的是指针实际指向内容的数据类型
D 野指针是指向未分配或者已经释放的内存地址
A:free函数仅进行释放空间的操作,不会自动将指针变量置空。(free对NULL也是什么都不做的)
B:没问题。不管你类型的大小是多大,32位机器下,都是用32个二进制位来标识地址,也就是4个字节
C:没问题。
D:没问题。
总结
printf的格式控制
对于printf(“%M.Ns”):
- M:打印的宽度
- M>0:右对齐
- M<0:左对齐
- 多的补空格
- N:从左边开始,拿N个字符打印
控制求值顺序
&& 和 ||都可以控制求值顺序——能判断出结果直接得出结果,不进行后面的操作和判断。
编程题
1. 组队竞赛
题目描述:
牛牛举办了一次编程比赛,参加比赛的有3*n个选手,每个选手都有一个水平值a_i.现在要将这些选手进行组队,一共组成n个队伍,即每个队伍3人.牛牛发现队伍的水平值等于该队伍队员中第二高水平值。
例如:
一个队伍三个队员的水平值分别是3,3,3.那么队伍的水平值是3
一个队伍三个队员的水平值分别是3,2,3.那么队伍的水平值是3
一个队伍三个队员的水平值分别是1,5,2.那么队伍的水平值是2
为了让比赛更有看点,牛牛想安排队伍使所有队伍的水平值总和最大。
如样例所示:
如果牛牛把6个队员划分到两个队伍
如果方案为:
team1:{1,2,5}, team2:{5,5,8}, 这时候水平值总和为7.
而如果方案为:
team1:{2,5,8}, team2:{1,5,5}, 这时候水平值总和为10.
没有比总和为10更大的方案,所以输出10.
输入描述:
输入的第一行为一个正整数n(1 ≤ n ≤ 10^5)第二行包括3*n个整数a_i(1 ≤ a_i ≤ 10^9),表示每个参赛选手的水平值.
输出描述:
输出一个整数表示所有队伍的水平值总和最大值.
示例1
输入
2
5 2 8 5 1 5
输出
10
分析
读完题目,可以了解:
我们需要分组,最大化 “每组的第二大水平值总和”。换句话说,每组的次大都要尽可能大。怎么做?
需要 一个最大的,一个次大的,一个最小的, 来组成一组。拿一个最大的是为了次大的能成为次大,否则这个次大就是最大了,而我们尽可能大的次大已经拿到,剩下的一个就拿一个最小的,来保证最大化中值。
但这代码咋写啊,没头绪呢。“手过”个样例试试。
这样就需要排序。比如,将 [2, 4, 5, 1, 3, 8, 7, 9, 6] 排序,得到[1, 2, 3, 4, 5, 6, 7, 8, 9]
组1:[1, 8, 9] 9来保证次大,1来保证来保证最大化中值。
组2:[2, 6, 7] 7来保证次大,2来保证来保证最大化中值。
组3:[3, 4, 5] 5来保证次大,3来保证来保证最大化中值。
8 + 6 + 4 = 18 即是每组都拿到尽可能大的次大
那这个次大,怎么来?
[ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
0 1 2 3 4 5 6 7 8
组1的次大8,下标是7
组2的次大6,下标是5
组3的次大4,下标是3
可以推出公式:次大下标 = 数组长度 - 2(组数i +1)*
7 = 9 - 2*1
5 = 9 - 2*2
3 = 9 - 2*3
代码
#include
#include
#include
using namespace std;int main()
{int n = 0;cin >> n;vector arr;arr.resize(3 * n);for(int i = 0; i < 3*n; ++i)cin >> arr[i];sort(arr.begin(), arr.end());int sum = 0;for(int i = 0; i< n; ++i){//次大的下标int index = arr.size() - 2 *(i+1);sum += arr[index];}cout << sum << endl;return 0;
}
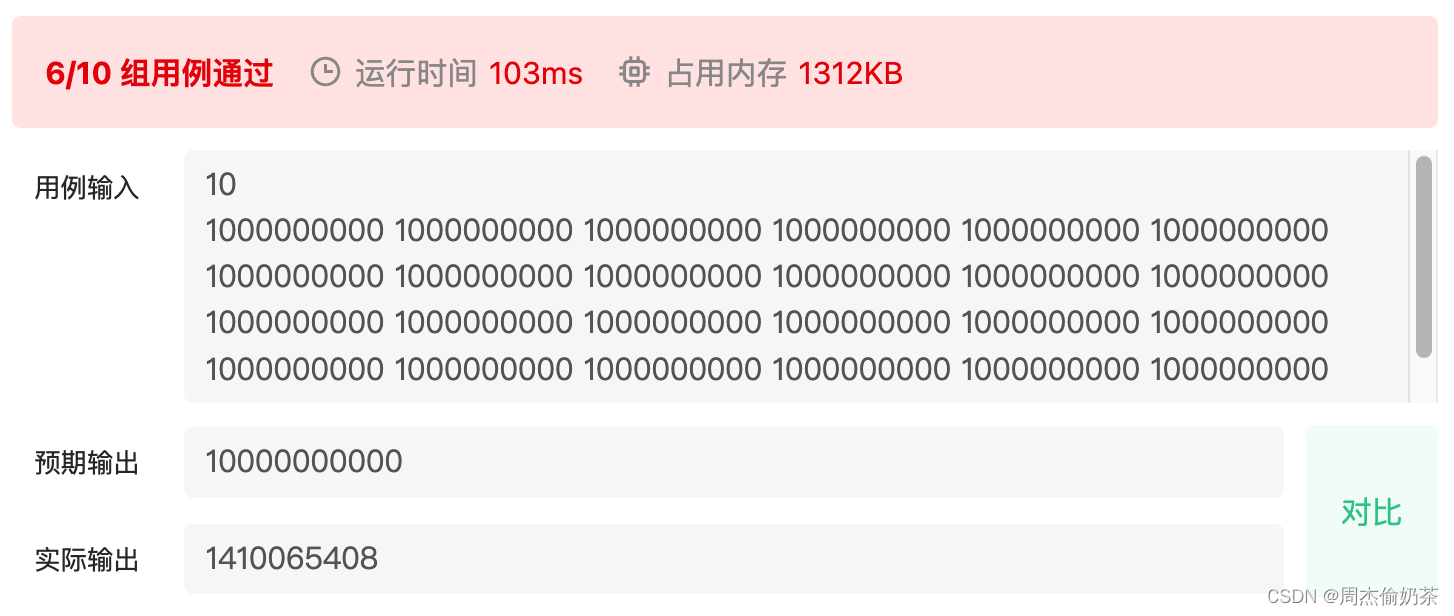
过了大部分用例,但是数据量大的时候崩了,能想到是int溢出,sum给上一个long即可
#include
#include
#include
using namespace std;int main()
{int n = 0;cin >> n;vector arr;arr.resize(3 * n);for(int i = 0; i < 3*n; ++i)cin >> arr[i];sort(arr.begin(), arr.end());long sum = 0;for(int i = 0; i< n; ++i){//次大的下标int index = arr.size() - 2 *(i+1);sum += arr[index];}cout << sum << endl;return 0;
}

总结
明白题意,能手过样例,但代码不知道怎么写:写出用例,把过程总结成代码
2. 删除公共字符
描述
输入两个字符串,从第一字符串中删除第二个字符串中所有的字符。例如,输入”They are students.”和”aeiou”,则删除之后的第一个字符串变成”Thy r stdnts.”
输入描述:
每个测试输入包含2个字符串
输出描述:
输出删除后的字符串
示例1
输入:
They are students.
aeiou
输出:
Thy r stdnts.
分析
读完题可以知道,要在第一个字符串中删除第二个字符串中的所有元素。
怎么删除?遍历第一个字符串,如果发现当前字符是第二个字符串中的任意一个,删除。
我们这里采用hash映射的思想。
hash映射:构建一个足够大的数组,每个下标对应的元素,是“下标值”出现过的次数。
什么意思呢?就是把值映射成下标,具体位置记录次数,比如
对于int数组[1, 1, 3, 4, 5],我们要映射进hash内(有相对映射和绝对映射两种,此处讲解相对映射)
构建足够大的数组:因为最大值达到了5,我们 int hash[6]
hash: [0, 0, 0, 0, 0, 0, 0]
下标 0 1 2 3 4 5 6
遍历数组[1, 1, 3, 4, 5],发现1出现两次,那么在hash内,把1的值映射成下标,就是hash[1],hash内的元素记录次数,所以hash[1]应该是2。遍历完成应该是这样:
hash: [0, 2, 0, 1, 1, 1, 0]
下标 0 1 2 3 4 5 6
这样能极大加快效率,把第二个字符串映射到hash数组,遍历第一个字符串的时候,想对比当前字符是不是要删除的,就可以通过下标直接访问:如果是0就没出现过,反之就要删除。
代码
#include
#include
using namespace std;int main()
{string s;string del;//要删除的getline(cin, s);getline(cin, del);//hash映射//构建hash数组:因为char的范围是[-128,127],所以128个元素就足够大vector hash;hash.resize(128);//映射for(int i = 0; i < del.size(); ++i){++hash[del[i]];//将值映射成下标,记录次数}//直接删除麻烦,我们选不删除的保存起来吗,最后再赋给sstring tmp;for(int i = 0; i < s.size(); ++i){if(hash[s[i]] == 0)tmp.push_back(s[i]);}s = tmp;cout << s << endl;
}
总结
优化查找效率,空间换时间:哈希映射。
除2倒取余:
如:255=(11111111)B
255/2=127=====余1
127/2=63======余1
63/2=31=======余1
31/2=15=======余1
15/2=7========余1
7/2=3=========余1
3/2=1=========余1
1/2=0=========余1
789=1100010101(B)
789/2=394 余1 第10位
394/2=197 余0 第9位
197/2=98 余1 第8位
98/2=49 余0 第7位
49/2=24 余1 第6位
24/2=12 余0 第5位
12/2=6 余0 第4位
6/2=3 余0 第3位
3/2=1 余1 第2位
1/2=0 余1 第1位
指针的运算
*指针变量的类型,决定了它指向的空间内的数据类型。如int* p,指向的空间存放的就是int。
*所谓“指向”,也就是指针变量内存了目标的地址,解引用就是通过指针变量内的地址找到目标。
- 指针 +/- 常数:跳过常数个指针指向空间的数据类型,如int*p += 1,就是跳过一个int
- 指针 +/- 指针:计算指针之间的元素个数(对int* p一个元素就是一个int)