
Linux基础IO(二)
文章目录
- 再谈文件描述符fd
- 文件是怎么被访问的?
- 文件描述符的分配规则
- 输出重定向
- 输出重定向证明
- 输出重定向原理
- 输入重定向;
- 输入重定向证明
- 输入重定向模拟实现
- 什么叫做文件呢?
- 如何用C语言实现面向对象
- 总述打开文件流程
- 初谈缓冲区
- 为什么要有缓冲区呢?
- 抛出疑问,缓冲区结合父子进程问题
- 回答疑问,缓冲区与父子基础进程结合问题
- 用户级缓冲区的存在位置
- 浅谈内核缓冲区
再谈文件描述符fd
文件是怎么被访问的?
(一):
fopen打开一个文件 ——> 调用系统接口open——>返回一个fd——> fd被封装成FILE ——> 以FILE*的方式供用户使用
(二):
用户调用fwrite() ——> 传进去一个FILE* ——> FELE里面包含了fd,和 write方法 ——>进程实际调write(fd,s,strlen(s))——> 就能找到进程的task_struct ——> 通过指向文件描述符的指针fs——> 找到对应的files_struct ——>通过fd找到对应的filefd_arry指针数组下标的地址——>该地址指向我们所要找的已经被打开的文件struct file——>进行IO操作。

文件描述符的分配规则
分配规则:
优先选取最小的,没有被占用的文件描述符给对应新打开的文件。
证明:
当我们正常打开打开一个文件,并打印该文件的fd时:
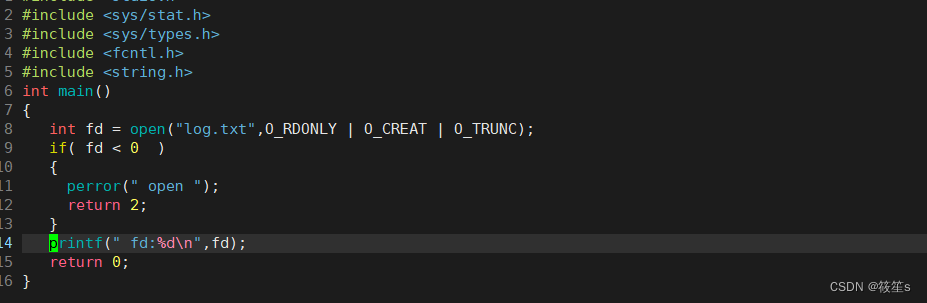
此时 fd = 3; 可能因为fd中的0,1,2 已经被占用了。

可是,当我把fd为2的文件关闭时,此时我再次打开文件并打印该fd的值,发现fd的值就变成了2.说


输出重定向
输出重定向证明
综合以上情况,此时我们将文件描述符为1的文件关闭,但是经过编译链接之后再运行该可执行程序时,却发现原本该打印再屏幕上的数据却无法打印了。

运行结果如下:
什么也没打印。

那么我们要打印的数据跑去哪里了呢?是不是我们将添加了close(1) 这一行代码的原因呢?
此时,当我们再将log.txt文件打印时运行结果如下:

总结;
本来是应该向stdout打印的数据,但是却都写入了log.txtr文件中,这个功能正好与输出重定向类似。
输出重定向原理
默认情况下:
我们知道PCB中的task_struct中的有一个指向files_struct中的指针,通过fs指针找到files_struct,而filesfd_array指针数组中文件描述符分别为0,1,2的内存空间分别储存这文件对象struct files 标准输入,标准输出,标准错误的地址。进程通过fs指针找到files_struct结构体后通过fd就能寻找并访问filefd_array数组对应下标的内容,进而找到对应文件对象标准输出stdout并将数据写入。

可是,当我们使用close(1)关闭stdout文件时,将files*fd_array数组中文件描述符为fd中的内容赋值为null,进程就无法再寻找并访问到stdout文件了。此时,根据fd文件描述符的分配规则,当进程执行到open时,则会将新创建文件对象log.txt中的地址填入到fd为1的数组空间中。此时,当进程继续执行到write操作时,进程找到的文件对象就为log.txt了。此时,原本应该写入在stdout文件中的数据便写入在了log.txt文件中。

输入重定向;
输入重定向证明
如果我们将stdin流中读取的数据写入到缓冲区buff中,并打印到stdout中时:
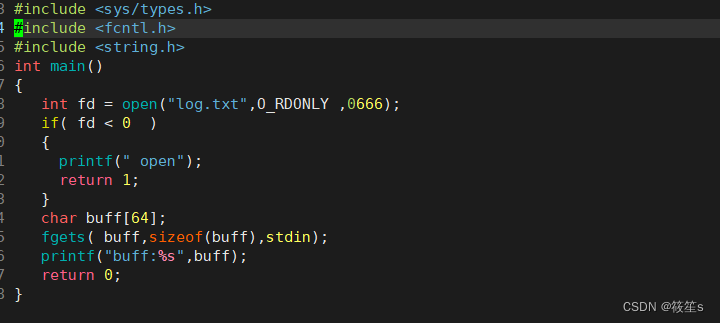
运行结果如下:
我们在stdin中输入什么数据,缓冲区中就被写入什么数据。

可是,当我们使用添加代码clos(0)将输入流stin关闭时。此时,再重新编译运行时:

发现此时输出了log.txt的文本内容。

总结:
类似于输出重定向,当我们使用close(0)时,则让本应该从键盘中读取的数据转变为从log.txt文件中读取。
输入重定向模拟实现
为了避免重复的开,关文件。我们推荐使用dup2()函数,其中形参为( int oldfd,int newfd),为了更好的区分使用,我们要清楚的分析 经过重定向之后该数组空间的内容和谁一致,和谁一致谁就是oidfd。

例如:
我们通过命令行参数将从键盘中输出的数据打印在stdout中。

运行结果如下:

当我们使用dup2函数时,将原本写入在stout中的数据写入在log.txt文件中,并打印log.txt文件。
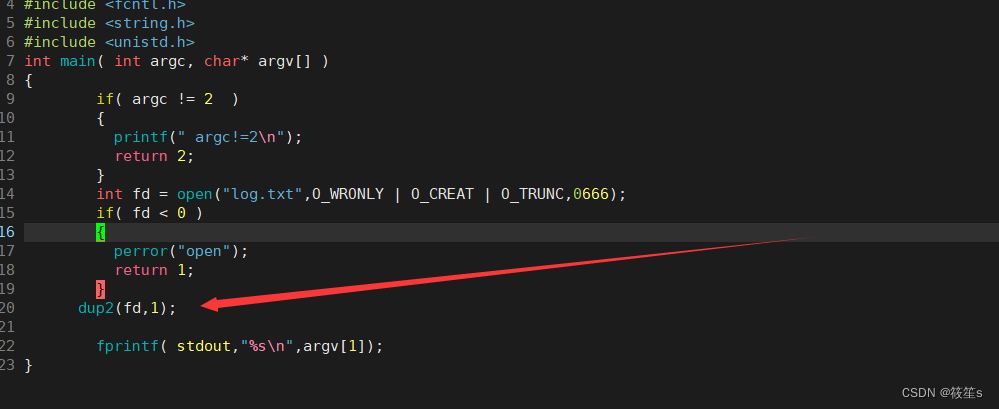
运行结果如下:

如果我们想实现追加重定向,直接将O_TRUNC换成O_APPEND就可以就行文本内容追加啦,该原理和输入重定向差不多,就不叙述了。
什么叫做文件呢?
如何用C语言实现面向对象
struct可以包含成员变量,不能像类一样包含成员方法,但是C语言有函数函数,通过函数指针就可以找到用户所需要的成员方法,这样的效果就和类一样具有面向对象的作用了。

另外,我们知道,像网卡,声卡等底层不同的硬件,一定对应的不同的操作方法。但是,又因为上面的设备都是外设,所以,每一个设备的核心访问函数,都可以是read,write(简称IO)。但是,代码的实现一定是不同的。
总述打开文件流程
当我们打开文件时,操作系统便会生成一个struct file ,这里面的struct file包含了成员变量和对应硬件成员方法的函数指针。例如,如果我们想对磁盘进行写入,我们首先要找到对应的磁盘文件对象,通过该对象的函数指针就能找到不同的硬件的成员方法。所以,我们可以将每个硬件都看作一个struct file文件对象,即Linux下,一切皆文件!
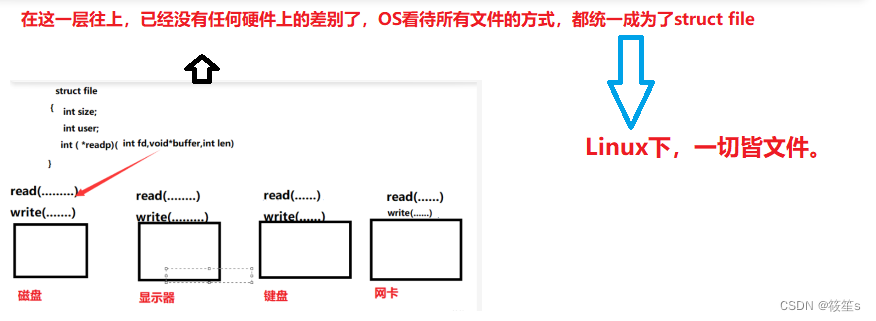
简述多态:
当如访问不同硬件文件一样,对于同一种文件类型,却表现出不同的行为的过程就叫做多态。
初谈缓冲区
缓冲区其实就是一段内存空间。
为什么要有缓冲区呢?
如果我们将数据写入到另一个磁盘文件,这种模式称为写透模式WT,但是成本高,效率低。
当我们将写入到缓冲区中,缓冲区储存了一大批数据之后再由缓冲区传递给对应目标磁盘文件,这种模式也叫做写回模式WB。快速,并且成本低。
(一):缓冲区存在的意义:
1:提高整机效率
2:提高用户的响应速度
如果不通过缓冲区将数据写入到磁盘中,内存写入速度为微秒级别,而磁盘写入速 度确是毫秒级别,它们效率整整差了1000倍,所以必须得有缓冲区。
(二):缓冲区的刷新策略
1:立即刷新
2:行刷新,将/n之前的内容全部刷新。
3:满刷新(全缓冲)
特殊情况:
1:用户强制刷新(fflush)
2:进程退出
抛出疑问,缓冲区结合父子进程问题
如果我们将四段字符串分别写入到stdout文件中编译并运行时,发现此时正好打印了四条字符串。

运行结果如下;

可是,当我们进行了输出重定向时:
此时的log.txt文件的内容却打印了,并且我们发现,C语言调用的输出函数接口打印了两行,而系统调用接口却只打印了一行!
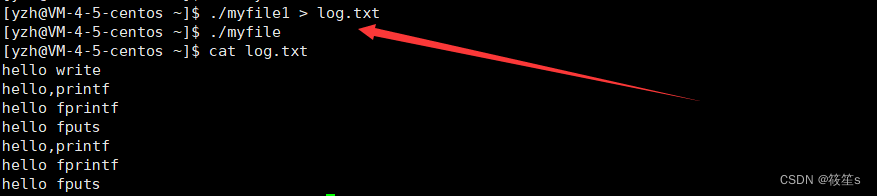
这又是怎么回事呢???
回答疑问,缓冲区与父子基础进程结合问题
(一):缓冲区的新认识
1:一般而言,采用行缓冲的设备文件——显示器
2; 采用全缓冲的设备文件 —— 磁盘文件
(二):两个设备缓冲区的方案差异原因:
所有的设备——>倾向于全缓冲——>缓冲区满了才能够刷新——>进而减少OS的IO操作——>进而减少外设访问 ——>提高效率。
注意:
系统和外部设备进行IO的时候,数量的多少并不是主要矛盾,我们和外设预备 IO的过程才是最耗费时间的。
其他刷新策略则是用户结合综合情况做出的妥协。
例如:
显示器采用行刷新:方便用户读取。
极端情况: 像一个个字符刷新是可以自定义规则的。
(三)回答问题,缓冲区与父子进程结合
我们知道,同一个和程序的情况下,原来在stdout上只会打印四行,加了fork()函数之后并进行输出重定向时,关于C文件接口打印了两次,关于系统接口却只打印了一次。

我们知道,所谓的“缓冲区”,绝对不是由OS提供的,如果由OS提供的话,那么我们上面的程序,加不加代码fork()的效果应该是一样的。
对于进程来说,当我们调用C文件接口fputs时,实际是将进程数据写入到C标准库中的缓冲区里,然后再统一调用系统接口write函数写入到对应的目标文件中。

当我们不使用输出重定向时,则进程执执行到fork()函数时会将C标准库里缓冲区的数据全部进行刷新出去。这样就是一开始的打印四次的结果。
可是,当我们进行输出重定向时,将原本写入到stdout文件中的数据写入到了磁盘文件中,而一旦写入到磁盘文件,缓冲模式就由行刷新变成了全缓冲。当进程执行到代码fork()时,此时进程写入C标准库中的缓冲区数据还未刷新。当进程执行fork函数,便又生成了子进程。
此时,当进程继续执行到return 0的时候,父子进程全部退出,此时便会将C标准库中的数据刷新到磁盘文件中。但是刷新数据在磁盘文件中的过程又是一次父子进程共同写入的过程。
那么,父子进程共同将数据写入时为了进程的独立性,进而会发生写时拷贝,就等于此时C标准库中的数据有了两份共同写入到了磁盘文件中,该文件也就正好有了两份数据。当我们使用cat log.txt命令时,就会出现C文件接口打印两次的情况!

用户级缓冲区的存在位置
综合以上情况,我们在执行fork()函数前将调用fflush接口来将及时将缓冲区的数据全部打印时。

运行结果如下:
再进行重定向运行时,发现和最初的程序没有进程重定向一样,仅仅只打印了四行!

那么,为什么调用C接口fflush函数后打印log.txt文件就变成了四行呢???
为什么我们在调用fflush接口的时候秩序只需要传入stdout,就能知道缓冲区在哪并进行刷新呢?
因为fflush和fprintf等文件输出函数一样,也是C标准库函数,当进程执行完fflush语句之后再执行fork()语句后。此时,C标准库中的缓冲区数据已经被刷新到磁盘文件中了,父子进程既然没有共同写入的数据那么就不会发生写时拷贝。
我们知道stdout便是1号描述符,进程通过1号描述符进行访问就能访问到对应的目标文件对象struct file。可是struct file对象中不但封装了描述符fd,还封装了C标准库中的缓冲区结构。
浅谈内核缓冲区
以上情况我们都是针对于C文件接口以及C标准库中的用户级缓冲区问题。但是对于系统接口write,在调用write函数时也不是直接将数据写入到外设文件中的。
而是写入到了属于FILE文件中的内核缓冲区,一旦数据写入到内核缓冲区就说明该数据并不属于父子进程的范畴了,而是属于内核操作系统了,所以即使对上述程序进行重定向,父子进程也不会发生写时拷贝!
上一篇:【面经】之小鼠喝药问题