
pandas基础-pandas之Series+ 读取外部数据+dataframe+dataframe的索引
创始人
2024-04-07 17:59:11
目录
pandas之Series
pandas之series创建
pandas之Series切片和索引
pandas之series的索引和值编辑
pandas之读取外部数据
pandas之dataframe
pandas之dataframe的创建
传入字典创建数据
dataframe的描述信息
dataframe的索引
pandas之loc
pandas之iloc
pandas之布尔索引
pandas之字符串方法
缺失数据的处理
常用数据类型:
1.series 一维,带标签数组
2.dataframe 二维,series 容器
pandas之Series
pandas之series创建


pandas之Series切片和索引
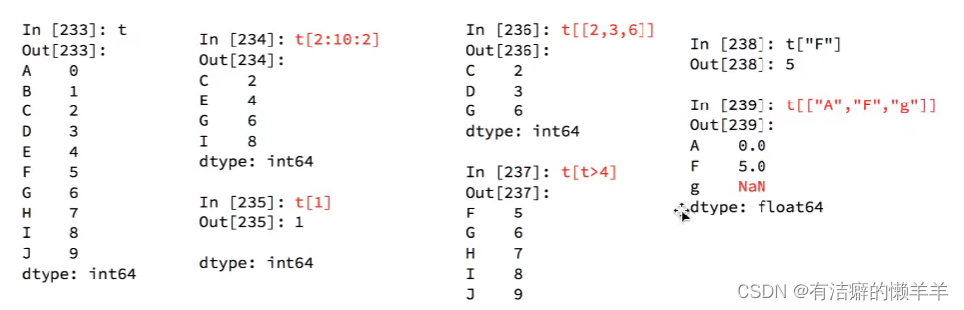
pandas之series的索引和值
pandas之读取外部数据
import pandas as pd
### csv
pd.read_csv()
### mysql
pd.read_sql(sql_sentence,connection)
### mongodb
from pymongo import MongoClent
client = MongoClient()
collection = client["donban"]["tv1"]
data = list(collection.find())t1 = data[0]
t1 = pd.Series(t1)
pandas之dataframe
pandas之dataframe的创建

传入字典创建数据
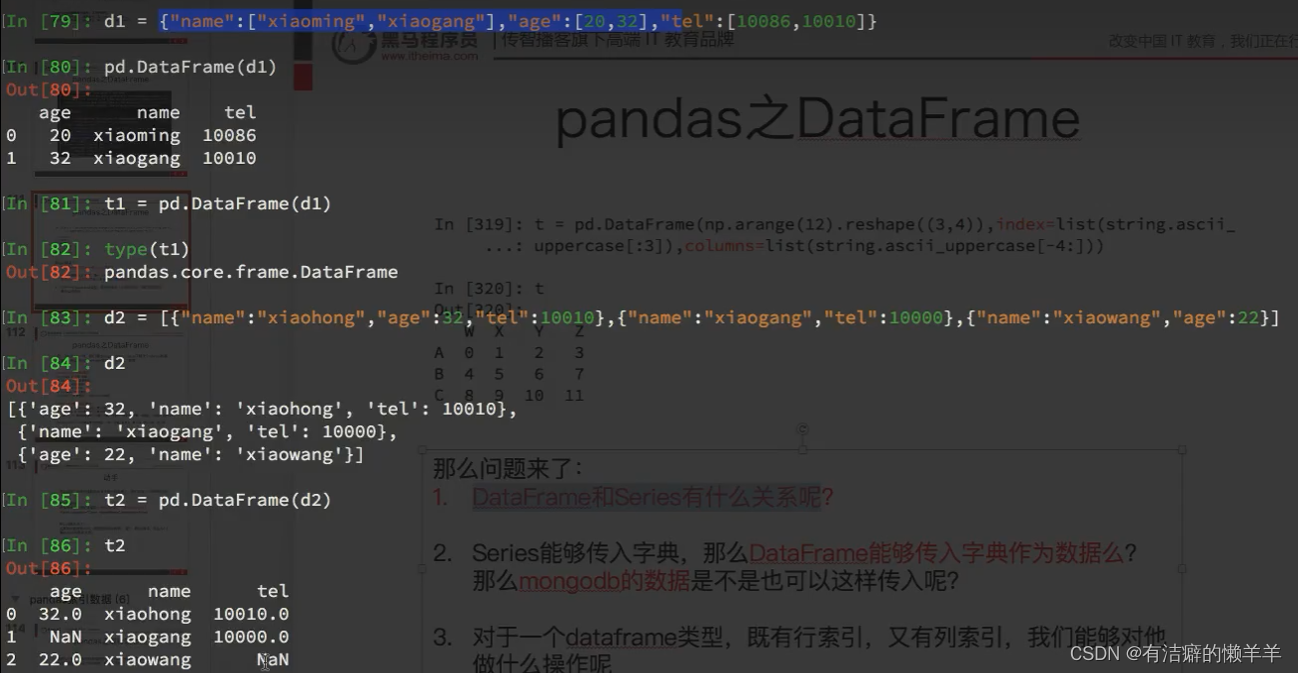
dataframe的描述信息
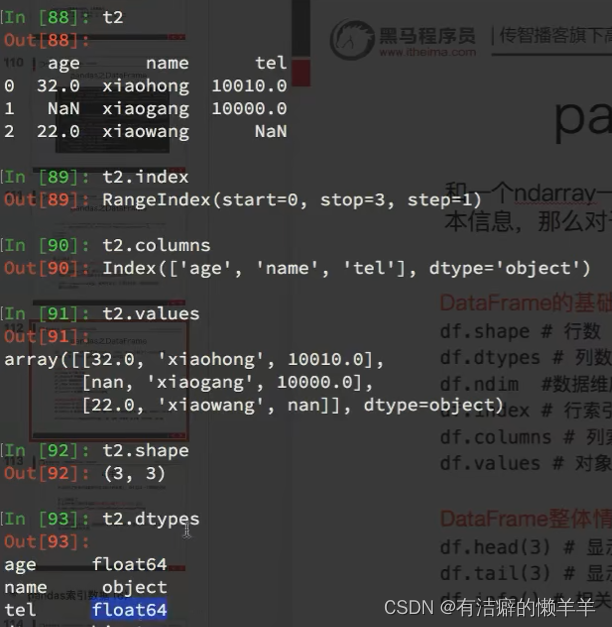

dataframe的索引
import pandas as pddf = pd.read_csv("./dogNames2.csv")#dataframe中排序的方法
df = df.sort_values(by="Count_AnimalName",ascending=False)
# print(df.head(5))
# pandas取行或者取列的注意点
# - 方括号写数组,表示取行,对行进行操作
# - 写字符串,表示的去列索引,对列进行操作
print(df[:20])
print(df["Row_Labels"])pandas之loc


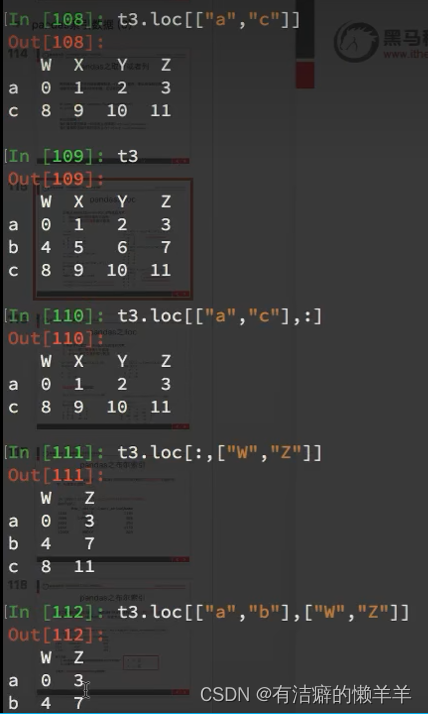
pandas之iloc



pandas之布尔索引
import pandas as pd# pandas读取csv中的文件
df = pd.read_csv("./dogNames2.csv")# &且 |或
print(df[(800pandas之字符串方法

# 转为列表
print(df["info"].str.split("/").tolist())缺失数据的处理


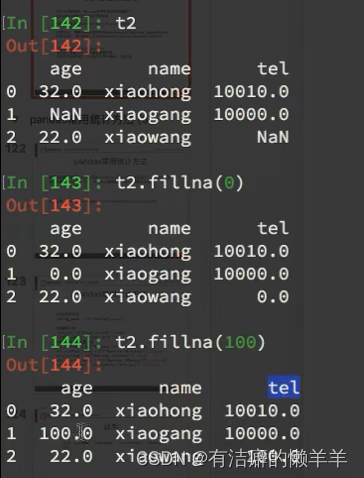
inplace = True 对之前的dataframe原地修改,就地修改


上一篇:linux系统文件权限
相关内容
热门资讯
原创 特...
美媒:若美伊谈判失败,特朗普支持以色列空袭伊朗弹道导弹设施 美国媒体在15日报道中指出,特朗普曾向以...
一条鱼如何游出180亿元产业
珠海金湾养殖的黄立鱼肉质鲜美 文/羊城晚报记者 杨雪薇 吴国颂 图/受访者提供 岁末年初...
最新或2023(历届)沈阳省重...
目前,尚有部分省级重点高中(含省级示范性高中)及沈阳经济区优质普通高中在我市录取未完成招生计划。 ...
最新或2023(历届)沈阳市第...
沈阳市第二十中学录取分数线(公费择校) 省级重点高中学校公 费 生择 校 生沈阳市第二十中学7146...
最新或2023(历届)沈阳铁路...
沈阳铁路实验中学录取分数线(公费择校) 省级重点高中学校公 费 生择 校 生沈阳铁路实验中学6906...