
应该记住的10个SQL 查询
注意:所有查询都是用PostgreSQL编写的。
文章目录
- 选择所有行
- where 语句
- Group by and Have 子句
- Order By and Limit
- 日期函数
- 内连接、左连接或右连接
- 子查询
- 相关子查询
- Case When 子句
- 窗口函数
- 对值进行排序
选择所有行
SELECT * FROM employees
如下:

where 语句
我们可以使用WHERE子句,它根据给定的语句过滤数据。
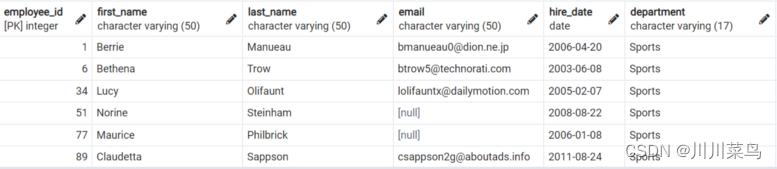
示例:编写查询以打印Department为”Sports “ 的所有变量。
SELECT * FROM employees
WHERE department = 'Sports'
如下:
Group by and Have 子句
Group By子句将具有相同值的行分组。
示例:每个部门的总工资是多少?
SELECT SUM(salary) as total_salary,department
FROM employees
GROUP BY department
如下:

在 SQL 中,不能在WHERE子句中使用SUM、AVG、MAX、MIN和COUNT等聚合函数。如果我们想通过聚合函数过滤我们的表,我们需要使用HAVING子句。
示例:哪些部门的员工超过 50 人?
SELECT count(*) as total_employee,department
FROM employees
GROUP BY Department
HAVING COUNT(*) > 50
如下:

Order By and Limit
示例:查找每个部门的总工资,并按总工资列降序排序。
SELECT SUM(salary) as total_salary,department FROM employees
GROUP BY department
ORDER BY total_salary desc
如下:

Limit 命令用于指定要返回的记录数。
示例:编写一个查询,查找前 5 名员工及其名字、部门和薪水,并按名字排序。
注意:默认 Order By 子句按 ASCENDING 顺序对结果进行排序
SELECT first_name,department,salary from employees
ORDER BY first_name
LIMIT 5
如下:

日期函数
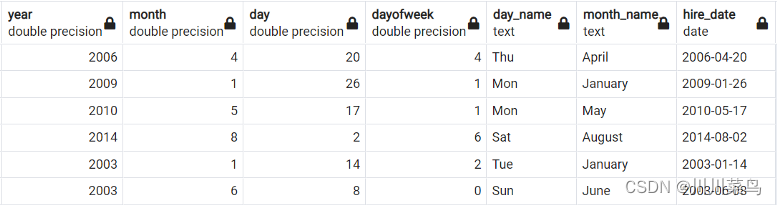
在 PostgreSQL 中,可以轻松地从日期列中提取值。将在下面看到最常用的日期函数。
SELECT
date_part('year',hire_date) as year,
date_part('month',hire_date) as month,
date_part('day',hire_date) as day,
date_part('dow',hire_date) as dayofweek,
to_char(hire_date, 'Dy') as day_name,
to_char(hire_date,'Month') as month_name,
hire_date
FROM employees
如下:
内连接、左连接或右连接
Inner Join子句通过组合两个或多个表中具有匹配值的行来创建一个新表(非物理表)。
示例:查询所有员工信息及其所属部门。
SELECT * FROM employees e
INNER JOIN departments d
ON e.department = d.department
Left Join返回左表中的所有行和右表中的匹配行。如果在右表中没有找到匹配的行,则使用NULL。(右连接反之亦然)
示例:编写一个查询,打印employee 中的所有部门并匹配department 表中的部门。
SELECT e.department,d.department FROM employees e
LEFT JOIN departments d
ON e.department = d.department
如下:

子查询
子查询是嵌套在更大查询中的 SQL 查询。
子查询可能发生在:
- 一个 SELECT 子句
- FROM 子句
- WHERE 子句
示例:查询每个员工的名字、部门和薪水以及给定的最高薪水。
SELECT first_name,department,salary,(SELECT max(salary) FROM employees)
FROM employees
如下:

相关子查询
相关子查询是读取表中每一行并将每一行中的值与相关数据进行比较的一种方法。每当子查询必须为主查询考虑的每个候选行返回不同的结果或结果集时,都会使用它。
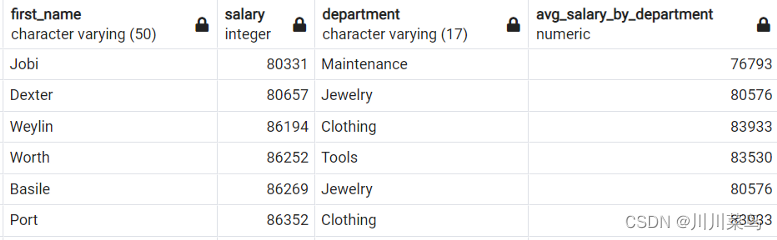
示例:编写一个查询,按部门查找名字、薪水、部门和平均薪水。
SELECT first_name,salary,department,round((SELECT AVG(salary) FROM employees e2 WHERE e1.department = e2.department GROUP BY department)) as avg_salary_by_department
FROM employees e1
WHERE pay > (SELECT AVG(salary) FROM employees e2 WHERE e1 .department = e2.department GROUP BY Department )
ORDER BY Salary
如下:
Case When 子句
CASE 语句用于实现希望根据其他列中的值设置一列的值的逻辑。它类似于 python 中的 IF-ELSE 语句。
示例:编写查询以打印名字、薪水和平均薪水,以及显示员工薪水是否高于平均薪水的新列。
SELECT first_name,salary,(SELECT ROUND(AVG(salary)) FROM employees) as average_salary,
(CASE WHEN Salary > (SELECT AVG(salary) FROM employees) THEN 'higher_than_average'
ELSE 'lower_than_average' END) as Salary_Case
FROM employees
窗口函数
窗口函数在特定窗口(行集)上应用聚合和排名函数。OVER 子句与窗口函数一起使用来定义该窗口。OVER 子句做了两件事:
- 对行进行分区以形成行集(使用 PARTITION BY 子句)。
- 将这些分区中的行按特定顺序排序(使用 ORDER BY 子句)。
应用于特定窗口(行集)的各种聚合函数,例如 SUM()、COUNT()、AVERAGE()、MAX() 和 MIN(),称为聚合窗口函数。
以下查询将为您提供每个部门的平均工资。
SELECT first_name,salary,department,
ROUND(AVG(salary) OVER(PARTITION BY department)) as avg_sales_by_dept
FROM employees
ORDER BY Salary DESC
如下:

对值进行排序
Rank() 函数是一个窗口函数,它为结果集分区内的每一行分配一个排名。
以下示例按薪水(降序)对表进行排序。排名值 1 是最高薪水值。
SELECT first_name,salary,RANK() OVER(ORDER BY Salary DESC)
FROM employees
如下:
