
AI大模型破译甲骨文?厦大团队又有新尝试……
《AI大模型助力厦大团队破译甲骨文新尝试》
在甲骨文研究领域,厦门大学团队开启了令人瞩目的新征程,他们引入AI大模型进行破译甲骨文的尝试。甲骨文作为古老而神秘的文字,其解读一直充满挑战。厦大团队借助AI大模型强大的数据分析、模式识别能力,为探索甲骨文的奥秘注入新活力。这一尝试意味着传统古文字研究与现代前沿技术的深度融合。它有望加速对甲骨文的解读进程,帮助我们更深入地理解殷商时期的文化、社会和历史,让那些被岁月尘封的古老信息在现代科技的助力下逐渐清晰地展现在世人面前。
近日,厦门大学信息学院自然语言处理实验室史晓东教授团队申报的“基于甲骨文多模态大模型的多元信息甲骨文辅助考释模型”入选“探元计划2024”“创新探索型项目”TOP10榜单。

甲骨文也被称作“殷墟文字”,距今已有三千多年历史,是世界四大古文字之一,是现代汉字的根脉。传统的甲骨文字考释工作极其耗时费力,依托于专家进行人工释读,多采用字形分析、辞例研究等方法,需要考古专家以深厚的知识积累和大量的文献阅读为基础,结合多方面的知识去破译甲骨字,已经难以为继。近年来AI技术迅猛发展,利用深度学习模型超强语义表示能力来实现甲骨文的辅助考释,优势已经崭露头角。
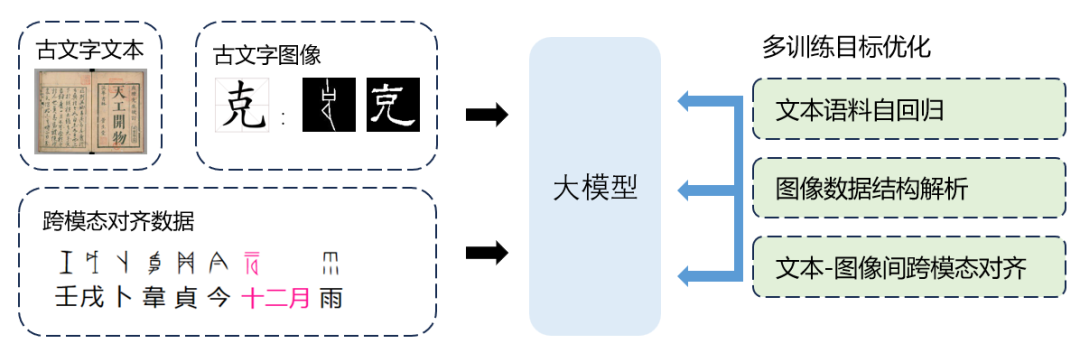
团队研究人员针对甲骨文数据稀缺、图像质量参差不齐的现状,系统整理相关古文字数据,构建更大规模、更高质量的甲骨文多模态数据集,提出了“基于甲骨文多模态大模型的多元信息辅助考释模型”的技术方案。
项目将设计一系列与实际考释过程密切相关的任务和评估方法,如跨字体图像映射、跨字体IDS(表达结构的部首偏旁序列)解码和甲骨字现代字对译关系等,以有效训练多模态大模型。利用其强大的跨模态理解能力,辅助甲骨文考释。在大模型提供的语义嵌入基础上,本项目还将设计融合音、形、义、用多元信息的端到端甲骨文综合考释模型,综合利用字形结构、语义关联、同音通假和用法聚类分析,开发一种更加轻量的考释系统,以适应资源有限的实际考释场景。
据悉,“探元计划2024”是由国家文物局科技教育司指导,中国文物信息咨询中心(国家文物局数据中心)、腾讯SSV数字文化实验室、腾讯研究院、社会价值投资联盟(深圳)与中国文物报、紫荆杂志社联合发起。厦门大学信息学院史晓东教授为“基于甲骨文多模态大模型的多元信息甲骨文辅助考释模型”项目的团队负责人,团队成员包括陈毅东副教授以及吴智聪、周子涵、付彪、黄崇轩等研究人员。项目团队在甲骨文考释方面深耕多年,在研究中积累了大规模的甲骨文相关语料,为项目的顺利开展奠定了坚实基础。